标签:综合 .com 使用 重要 网络 偏见 特征 神经元 神经网络
只是知道CNN是不够,我们需要对其进行解剖,继而分析不同部件存在的意义
简单来说,CNN的目的是以一定的模型对事物进行特征提取,而后根据特征对该事物进行分类、识别、预测或决策等。在这个过程里,最重要的步骤在于特征提取,即如何提取到能最大程度区分事物的特征。如果提取的特征无法将不同的事物进行划分,那么该特征提取步骤将毫无意义。而实现这个伟大的模型的,是对CNN进行迭代训练。
在图像中(举个例子),目标事物的特征主要体现在像素与像素之间的关系。比如说,我们能区分一张图片中有一条直线,是因为直线上的像素与直线外邻像素的区别足够大(或直线两边的像素区别足够大),以至于这“直线”能被识别出来:


除了直线外,其他特征也同理。在CNN中,大部分特征提取依赖于卷积运算。
卷积在此其实就是内积,步骤很简单,就是根据多个一定的权重(即卷积核),对一个块的像素进行内积运算,其输出就是提取的特征之一:
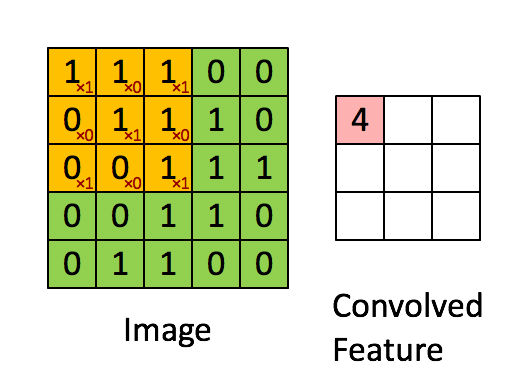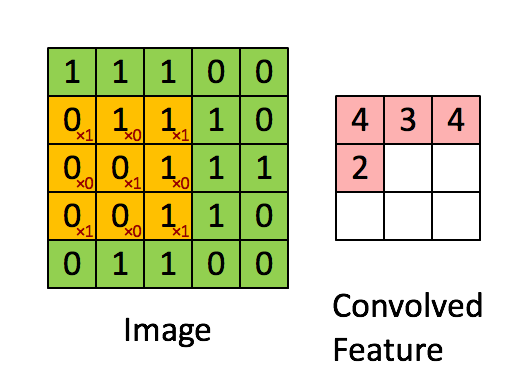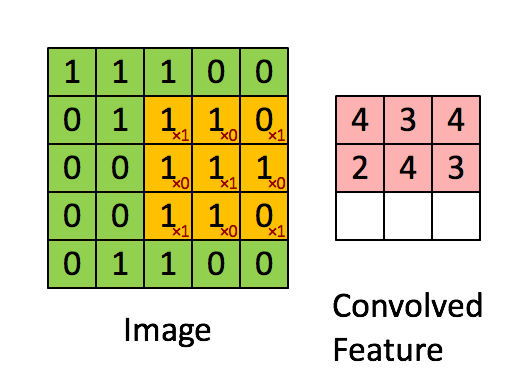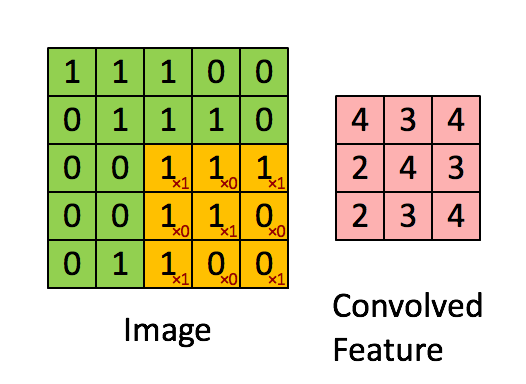
简单来说,卷积核的大小一般小于输入图像的大小(如果等于则是全连接),因此卷积提取出的特征会更多地关注局部 —— 这很符合日常我们接触到的图像处理。而每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
参数共享最大的作用莫过于很大限度地减少运算量了。
一般我们都不会只用一个卷积核对输入图像进行过滤,因为一个核的参数是固定的,其提取的特征也会单一化。这就有点像是我们平时如何客观看待事物,必须要从多个角度分析事物,这样才能尽可能地避免对该事物产生偏见。我们也需要多个卷积核对输入图像进行卷积。
卷积后再接上一个池化层(Pooling)简直就是绝配,能很好的聚合特征、降维来减少运算量。
层数越高,提取到的特征就越全局化。
池化,即对一块数据进行抽样或聚合,例如选择该区域的最大值(或平均值)取代该区域:
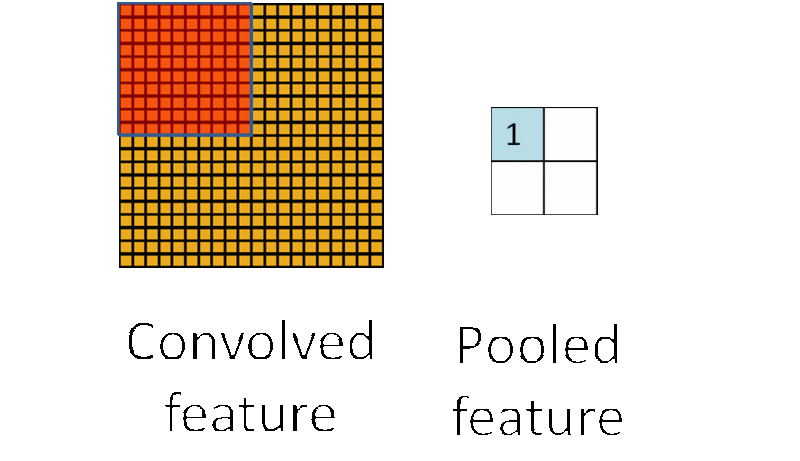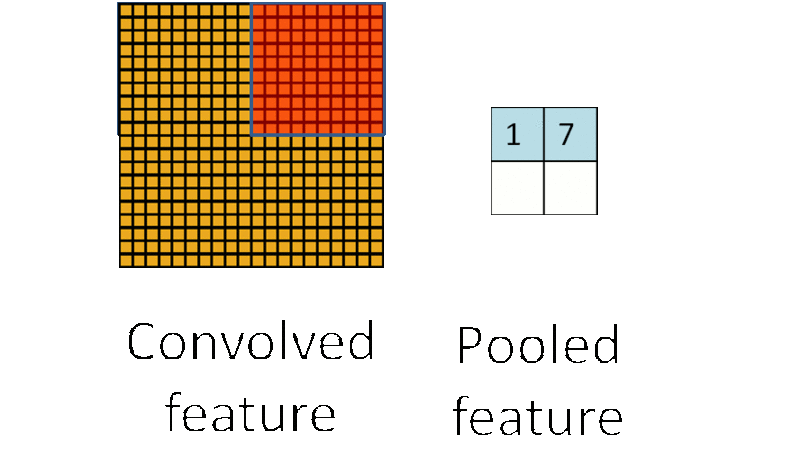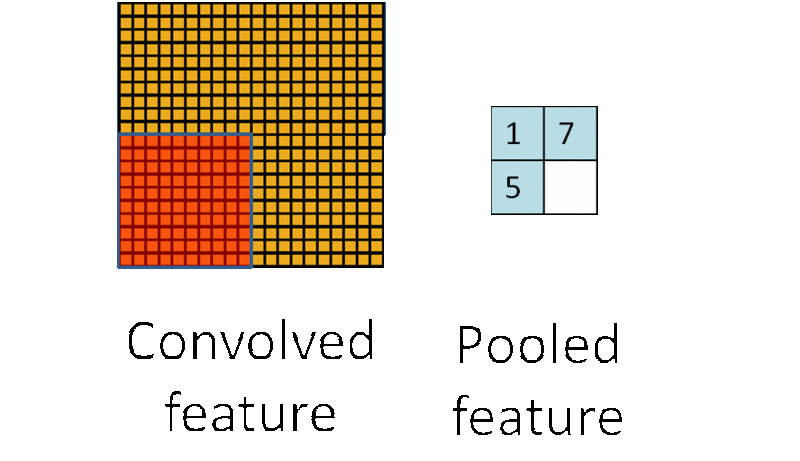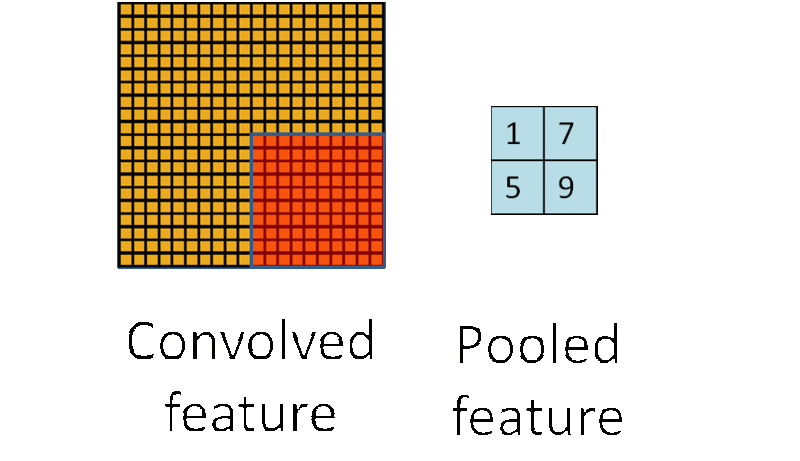
上图的池化例子,将10 * 10的区域池化层1 * 1的区域,这样使数据的敏感度大大降低,同时也在保留数据信息的基础上降低了数据的计算复杂度。
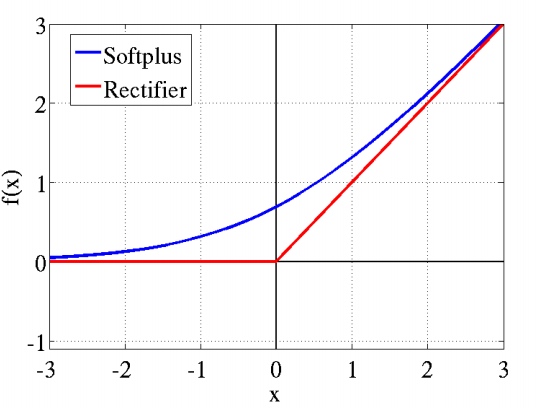
在数学上,激活函数的作用就是将输入数据映射到0到1上(tanh是映射-1到+1上)。至于映射的原因,除了对数据进行正则化外,大概是控制数据,使其只在一定的范围内。当然也有另外细节作用,例如Sigmoid(tanh)中,能在激活的时候,更关注数据在零(或中心点)前后的细小变化,而忽略数据在极端时的变化,例如ReLU还有避免梯度消失的作用。通常,Sigmoid(tanh)多用于全连接层,而ReLU多用于卷积层。
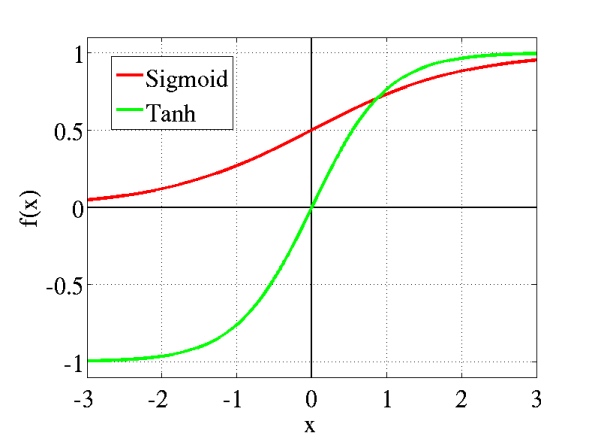
或者我们换一个卷积核(换一种角度)来看待这个激活函数,如果我们把每一次激活动作当成一次分类,即对输入数据分成两类(0或1),那么激活函数得到的输出是在0到1的值,它可以代表着这次“分类”的归属度。如果我们把0规定为未激活,1表示激活,那么输出0.44就表示激活了44%。
而激活函数的使用却有可能带来一定的负面影响(对于训练的负面影响),激活函数可能会使我们得输入数据都激活了大半,对此我们有另外的对策 —— LRN。
LRN,局部响应归一化。在神经学科中,有一个叫横向抑制(lateral inhibition)的概念,这种抑制的作用就是阻止兴奋神经元向邻近神经元传播其动作趋势,从而减少兴奋神经元的邻近神经元的激活程度。借鉴了这一生物现象(其实我们全部东西都是借鉴生物的,不是?),我们使用LRN层来对激活函数的输出数据进行横向抑制,在为激活函数收拾残局的同时,LRN还凸显了该区域的一个峰值 —— 这个峰值特征就是我们想要的特征。
特别是ReLU,它无限制的激活使得我们更需要LRN来到数据进行归一化。在大规模的数据中,我们大多情况下更看重被凸显的高频特征。因此,用LRN对数据的峰值进行催化而对其周围进行抑制,何乐不为。
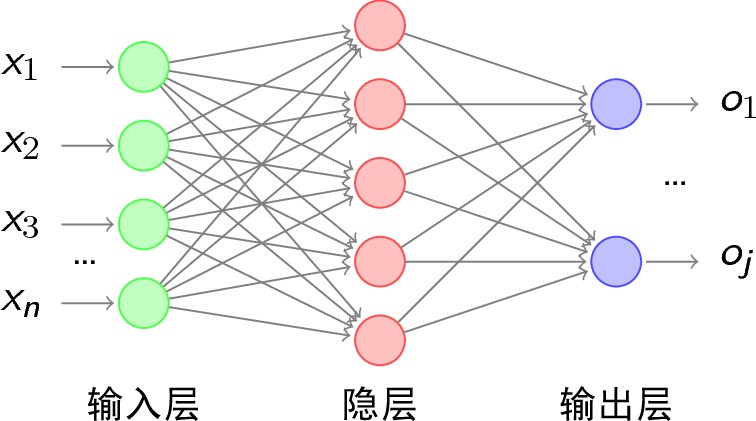
在许多CNN的后部分,都存在着一个IP(Inner Product)层/内积层/fc(full connect)层/全连接层。这个全连接网络的代表性层级,其存在于CNN的意义我不得而知。在许多论文中,它替代了softmax来特征负责最终的提取,而有人也指出CNN最后可以不用IP层。
舍弃一直是一个伟大的哲学,生物的进化上例子比比皆是。Dropout的任务就是在训练时,通过设置阈值并与某些隐含层节点的权重对比,让特定的权重不工作 —— 在该层舍弃这些权重。Dropout的作用也很明显,除了加速运算外,就是防止过拟合了。
标签:综合 .com 使用 重要 网络 偏见 特征 神经元 神经网络
原文地址:https://www.cnblogs.com/Ph-one/p/9074431.html