标签:实例 面向对象 bsp 增加 map str 行为型 工具 函数
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。
介绍
意图:给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。
主要解决:对于一些固定文法构建一个解释句子的解释器。
何时使用:如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。
如何解决:构件语法树,定义终结符与非终结符。
关键代码:构件环境类,包含解释器之外的一些全局信息,一般是 HashMap。
应用实例:编译器、运算表达式计算。
优点: 1、可扩展性比较好,灵活。 2、增加了新的解释表达式的方式。 3、易于实现简单文法。
缺点: 1、可利用场景比较少。 2、对于复杂的文法比较难维护。 3、解释器模式会引起类膨胀。 4、解释器模式采用递归调用方法。
使用场景: 1、可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。 2、一些重复出现的问题可以用一种简单的语言来进行表达。 3、一个简单语法需要解释的场景。
解释器模式的应用
解释器模式的优点
解释器是一个简单语法分析工具,它最显著的优点就是扩展性,修改语法规则只要修改相应的非终结符表达式就可以了,若扩展语法,则只要增加非终结符类就可以了。
解释器模式的缺点
解释器模式会引起类膨胀
每个语法都要产生一个非终结符表达式,语法规则比较复杂时,就可能产生大量的类文件,为维护带来了非常多的麻烦。
解释器模式采用递归调用方法
每个非终结符表达式只关心与自己有关的表达式,每个表达式需要知道最终的结果,必须一层一层地剥茧,无论是面向过程的语言还是面向对象的语言,递归都是在必要条件下使用的,它导致调试非常复杂。想想看,如果要排查一个语法错误,我们是不是要一个一个断点的调试下去,直到最小的语法单元。
效率问题。解释器模式由于使用了大量的循环和递归,效率是个不容忽视的问题,特别是用于解析复杂、冗长的语法时,效率是难以忍受的。
解释器模式使用的场景
重复发生的问题可以使用解释器模式
例如,多个应用服务器,每天产生大量的日志,需要对日志文件进行分析处理,由于各个服务器的日志格式不同,但是数据要素是相同的,按照解释器的说法就是终结符表达式都是相同的,但是非终结符表达式就需要制定了。在这种情况下,可以通过程序来一劳永逸地解决该问题。
一个简单语法需要解释的场景
为什么是简单?看看非终结表达式,文法规则越多,复杂度越高,而且类间还要进行递归调用(看看我们例子中的堆栈),不是一般地复杂。想想看,多个类之间的调用你需要什么样的耐心和信心去排查问题。因此,解释器模式一般用来解析比较标准的字符集,例如SQL语法分析,不过该部分逐渐被专用工具所取代。
在某些特用的商业环境下也会采用解释器模式,我们刚刚的例子就是一个商业环境,而且现在模型运算的例子非常多,目前很多商业机构已经能够提供出大量的数据进行分析。
解释器模式的注意事项
尽量不要在重要的模块中使用解释器模式,否则维护会是一个很大的问题。在项目中可以使用shell、JRuby、Groovy等脚本语言来代替解释器模式,弥补Java编译型语言的不足。我们在一个银行的分析型项目中就采用JRuby进行运算处理,避免使用解释器模式的四则运算,效率和性能各方面表现良好。
最佳实践
解释器模式在实际的系统开发中使用的非常少,因为它会引起效率、性能以及维护等问题,一般在大中型的框架型项目能够找到它的身影,比如一些数据分析工具、报表设计工具、科学计算工具等等
通用类图:
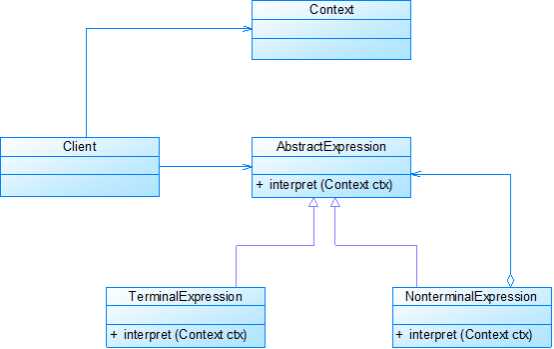
实例:
输入一个模型公式(加减四则运算),然后输入模型中的参数,运算出结果。
需求不复杂,若仅仅对数字采用四则运算,每个程序员都可以写出来。但是增加了增加模型公式就复杂了。先解释一下为什么需要公式, 而不采用直接计算的方法,例如有如下3个公式:
业务种类1的公式:a+b+c-d;
业务种类2的公式:a+b+e-d;
业务种类3的公式:a-f。
我们来想,公式中有什么?仅有两类元素:运算元素和运算符号,运算元素就是指a、b、c等符号,需要具体赋值的对象,也叫做终结符号,为什么叫终结符号呢?因为这些元素除了需要赋值外,不需要做任何处理,所有运算元素都对应一个具体的业务参数,这是语法中最小的单元逻辑,不可再拆分;运算符号就是加减符号,需要我们编写算法进行处理,每个运算符号都要对应处理单元,否则公式无法运行,运算符号也叫做非终结符号。两类元素的共同点是都要被解析,不同点是所有的运算元素具有相同的功能,可以用一个类表示,而运算符号则是需要分别进行解释,加法需要加法解析器,减法也需要减法解析器。分析到这里,我们就可以先画一个简单的类图
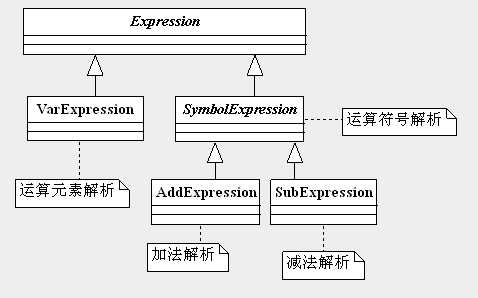
很简单的一个类图,VarExpression用来解析运算元素,各个公式能运算元素的数量是不同的,但每个运算元素都对应一个VarExpression对象。SybmolExpression负责运算符号解析,由两个子类AddExpression(负责加法运算)和SubExpression(负责减法运算)来实现。解析的工作完成了,我们还需要把安排运行的先后顺序(加减法是不用考虑,但是乘除法呢?注意扩展性),并且还要返回结果,因此我们需要增加一个封装类来进行封装处理,由于我们只做运算,暂时还不与业务有关联,定义为Calculator类,分析到这里,思路就比较清晰了
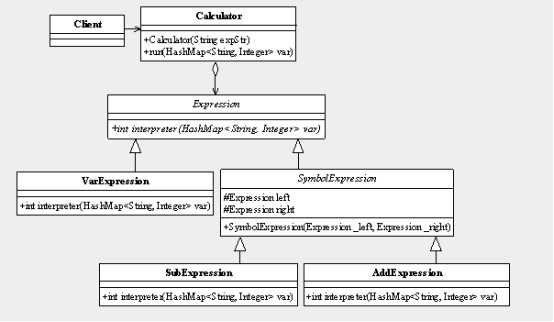
每个运算符号都只和自己左右两个数字有关系,但左右两个数字有可能也是一个解析的结果,无论何种类型,都是Expression的实现类,于是在对运算符解析的子类中增加了一个构造函数,传递左右两个表达式。
首先,要求输入公式。
请输入表达式:a+b-c
其次,要求输入公式中的参数。
请输入a的值:100
请输入b的值:20
请输入c的值:40
最后,运行出结果。
运算结果为:a+b-c=80
要求输入一个公式,然后输入参数,运行结果出来了!那我们是不是可以修改公式?当然可以了,我们只要输入公式,然后输入相应的值就可以了,公式是在运行期定义的,而不是在运行前就制定好的,是不是类似于初中学过的“代数”这门课?先公式,然后赋值,运算出结果。
标签:实例 面向对象 bsp 增加 map str 行为型 工具 函数
原文地址:https://www.cnblogs.com/kangy123/p/9084875.html