标签:分享图片 模块 相等 输出 for int distance 导入 inf
# 以kNN算法为例
# 不同领域内,遇到不同的问题,产参数一般不同;
# 领域:如自然语言处理、视觉搜索等;
# 一般机器学习算法库中,会封装一些默认的超参数,这些默认的超参数一般都是经验数值;
# kNN算法这scikit-learn库中,k值默认为5,5就是在经验上比较好的数值;
# 在Jupyter NoteBook中实现的代码 import numpy as np from sklearn import datasets digits = datasets.load_digits() X = digits.data y = digits.target from ALG.train_test_split import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_train = 0.2) # 1)按经验选定超参数k = 5 from sklearn.neighbors import KNeighborsClassifier knn_clf = KNeighborsClassifier(n_neighbors = 5) knn_clf.fit(X_train, y_train) knn_clf.score(X_test, y_test) # 2)按试验搜索,获取最优的超参数K,不考虑weights best_score = 0.0 best_k = -1 for k in range(1, 11): knn_clf = KNeighborsClassifier(n_neighbors = k) knn_clf.fit(X_train, y_train) knn_score = knn_clf.score(X_test, y_test) if knn_score > best_score: best_score = knn_score best_k = k print("best_k = ", best_k) print("best_score = ", best_score) # 3)按试验搜索,获取最优的超参数k、weight best_method = "" best_score = 0.0 best_k = -1 for method in ["uniform", "distance"]: for k in range(1, 11): knn_clf = KNeighborsClassifier(n_neighbors = k) knn_clf.fit(X_train, y_train) knn_score = knn_clf.score(X_test, y_test) if knn_score > best_score: best_score = knn_score best_k = k best_method = method print("best_mrthod = ", best_method) print("best_k = ", best_k) print("best_score = ", best_score) # 4)试验搜索,获取最优产参数k、P(weights必须为distance) %%time best_p = -1 best_score = 0.0 best_k = -1 for k in range(1, 11): for p in range(1, 6): knn_clf = KNeighborsClassifier(n_neighbors = k, weights = "distance", p = p) knn_clf.fit(X_train, y_train) knn_score = knn_clf.score(X_test, y_test) if knn_score > best_score: best_score = knn_score best_k = k best_p = p print("best_p = ", best_p) print("best_k = ", best_k) print("best_score = ", best_score)
# 模型参数:算法过程中学习的参数;
# kNN算法中没有模型参数,因为它没有模型;
# 线性回归算法和逻辑回归算法,包含有大量的模型参数;
# 什么是模型选择?
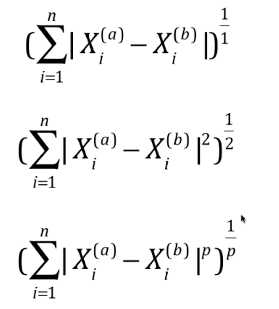
标签:分享图片 模块 相等 输出 for int distance 导入 inf
原文地址:https://www.cnblogs.com/volcao/p/9085363.html