标签:comm 内容 href hex 自定义 tput 传递 没有 drop
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy使用了Twisted异步网络库来处理网络通讯,整体架构大致如下: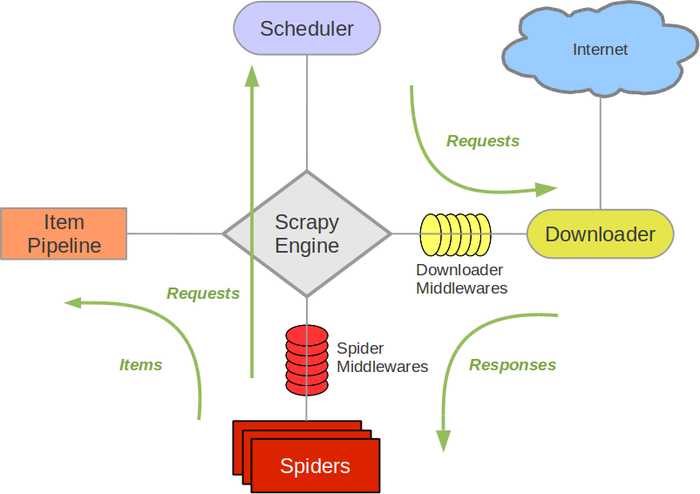
Scrapy主要包括了以下组件:
Scrapy Engine是整个框架的核心,用来处理整个系统的数据流处理。
用来接受引擎发过来的请求,也就是调度抓取网页链接的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址。
用于下载网页内容,建立在twisted高效异步模型上,整个Scrapy框架都建立在这个模型上。
用户定制的爬虫组件,用于从特定的网页信息上提取自己需要的信息,也可以从中提取链接,让Scrapy继续抓取下一次要抓取的页面。
负责处理用户定制爬虫中提取的Item,主要的功能是持久化项目,验证项目的有效性,清除不需要的信息。当页面被爬虫解析后,将被发送给项目管道,并经过几个特定的次序处理数据。
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
介于Scrapy引擎和爬虫之间的框架,主要工作是处理spider的响应输入和请求输出。
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
1 pip3 install wheel 2 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/ #twisted 3 进入下载目录,执行 pip3 install Twisted?17.1.0?cp35?cp35m?win_amd64.whl 4 pip3 install scrapy 5 下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/
1 scrapy startproject 项目名称 2 cd 项目名称目录 3 scrapy genspider 爬虫名 网址域名
1 scrapy crawl banmakj --nolog # 单独运行 --nolog不显示日志 2 scrapy crawl banmakj -s JOBDIR=job1 # 中断运行,可继续从中断的地方继续爬取 3 # 在项目文件下,新建run.py,运行run.py,便于程序的调试 4 from scrapy import cmdline 5 cmdline.execute(‘scrapy crawl banmakj‘.split())
自定制命令
from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self): return ‘[options]‘ def short_desc(self): return ‘Runs all of the spiders‘ # help提示信息 def run(self, args, opts): spider_list = self.crawler_process.spiders.list() # 获取所有的爬虫名字 for name in spider_list: self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start()
win下终端运行scrapy没有内容显示,可能是编码的问题,在spider.py文件中加
import sys,os sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘)
Selectors选择器简介:从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 和 CSS 表达式机制: Scrapy Selectors 。 关于selector和其他提取机制的信息请参考 Selector文档 。
from scrapy.selector import Selector # 查看Selector源码
这里给出Xpath表达式的例子及对应的含义:
为了配合XPath,Scrapy除了提供了Selector之外,还提供了方法来避免每次从response中提取数据时生成selector的麻烦。
Selector有四个基本的方法:
from scrapy.selector import Selector ... html = Selector(response=response).xpath(‘...‘) # 简洁写法 ... html = response.xpath(‘...‘)
使用第三方库xpath的解析方法:
from lxml import etree ... selector = etree.HTML(response.text) content = selector.xpath(‘...‘) # 网页内容 response.text
scrapy默认会访问start_urls,调用start_requests方法,以及parse方法,进行初始化url。可以重写此方法,这样就可以访问我们任意设置的初始化url和自定义parse方法。
在settings中设置递归深度 DEPTH_LIMIT = 4 指定递归的层数为4层。
def start_requests(self): url = ‘...‘ yield request(url,callback=self.custom_parse)
scrapy默认url去重源码在from scrapy.dupefilters import RFPDupeFilter类中,通过创建一个本地文件以追加的方式打开,把url存储到文件中,然后利用set集合去重。
dont_filter = False scrapy默认开启去重,如果想多次请求同一个url,可以将其设为True。
其实,我们可以自定义scrapy的去重方法,在spiders同级目录下,创建duplication.py文件,添加RepeatFilter类。
在settings中设置 DUPEFILTER_CLASS = ‘项目名称.duplication.RepeatFilter‘
# 去重函数在scrapy开始运行的时候就已经执行了 class RepeatFilter(object): def __init__(self): # 第2步 初始化 self.visited_url=set() # 可以在这里设置写到数据库、缓存中... scrapy默认写到文件中 @classmethod # obj = RepeatFilter.from_setting() 返回cls()等于调用了RepeatFilter() def from_settings(cls, settings): print(‘from_setting‘) # 第1步 创建对象 return cls() def request_seen(self, request): # 第4步 set集合去重 if request.url in self.visited_url: return True self.visited_url.add(request.url) return False def open(self): # 第3步 打开spider print(‘open‘) pass def close(self, reason): # 第5步 关闭 print(‘close‘) pass def log(self, request, spider): pass
scrapy用set()去重带来的弊端就是url长度不一致,占据的内存空间大,读取访问速度也相对较慢。可以通过对url加密的方式,如md5,长度相同,同一url的mad5值相同,存储长度也一样。
import hashlib def md5(url): obj = hashlib.md5() obj.update(bytes(url,encoding=‘utf-8‘)) return obj.hexdigest()
from scrpay.exceptions import DropItem class SaveMongDBPipline(object): def __init__(self,mong_url): self.mong_url = mong_url @classmethod # 初始化时候,用于创建pipeline对象,从setting中导入配置文件 def from_crawler(cls,crawler): # crawler中封装了settings 配置文件必须大写。 mong_url = crawler.settings.get("MONG_URL") return cls(mong_url) def process_item(self,item,spider): # 保存item到mongdb # raise DropItem 不返回item 抛出异常 yield item def open_spider(self,spider): # 打开数据库 爬虫开始执行时被调用 def close_spider(self,spider): # 关闭数据库 爬虫结束时被调用
第一种方法:
#下面start_requests中键‘cookiejar’是一个特殊的键,scrapy在meta中见到此键后,会自动将cookie传递到要callback的函数中。既然是键(key),就需要有值(value)与之对应,例子中给了数字1,也可以是其他值,比如任意一个字符串。 def start_requests(self): yield Request(url,meta={‘cookiejar‘:1},callback=self.parse) #需要说明的是,meta给‘cookiejar’赋值除了可以表明要把cookie传递下去,还可以对cookie做标记。一个cookie表示一个会话(session),如果需要经多个会话对某网站进行爬取,可以对cookie做标记,1,2,3,4......这样scrapy就维持了多个会话。 def parse(self,response): key=response.meta[‘cookiejar‘] #经过此操作后,key=1 yield Request(url2,meta={‘cookiejar‘:key},callback=‘parse2‘) def parse2(self,response): pass #上面这段和下面这段是等效的: def parse(self,response): yield Request(url2,meta={‘cookiejar‘:response.meta[‘cookiejar‘]},callback=‘parse2‘) #这样cookiejar的标记符还是数字1 def parse2(self,response): pass
第二种方法:
# 先引入CookieJar()方法 from scrapy.http.cookies import CookieJar # 写spider方法时: def start_requests(self): yield Request(url,callback=self.parse) #此处写self.parse或‘parse’都可以 def parse(self,response): cj = response.meta.setdefault(‘cookie_jar‘, CookieJar()) cj.extract_cookies(response, response.request) container = cj._cookies yield Request(url2,cookies=container,meta={‘key‘:container},callback=‘parse2‘) def parse2(self,response): pass
第三种方法:
cookies = None # 全局变量保存cookies def parse(self, response): cookie_jar = CookieJar() cookie_jar.extract_cookies(response,response.request) cookies = cookie_jar._cookies yield scrapy.Request( ... cookies=cookies, ) #下一次请求带上self.cookies
扩展框架提供一个机制,使得你能将自定义功能绑定到Scrapy。扩展只是正常的类,它们在Scrapy启动时被实例化、初始化。
源码:from scrapy.extensions.telnet import TelnetConsole
#自定义扩展,新建extensions.py from scrapy import signals class MyExtend: def __init__(self, crawler): # 注册信号操作,信号触发的时候,可以执行很多东西 self.crawler = crawler self.crawler.signals.connect(self.start, signals.engine_started) # 注册自定义信号 @classmethod def from_crawler(cls, crawler): return cls(crawler) def start(self): print(‘signal.engine_started‘) # 扩展所能用的信号 engine_started = object() engine_stopped = object() spider_opened = object() spider_idle = object() spider_closed = object() spider_error = object() request_scheduled = object() request_dropped = object() response_received = object() response_downloaded = object() item_scraped = object() item_dropped = object()
BOT_NAME = ‘ ‘ # 爬虫的名字 通过user_agent发送出去 ROBOTSTXT_OBEY = True # 爬虫规则 False不遵守 CONCURRENT_REQUESTS = 32 # 并发请求数 DOWNLOAD_DELAY = 3 # 下载延时 CONCURRENT_REQUESTS_PER_DOMAIN = 16 # 针对域名并发数 CONCURRENT_REQUESTS_PER_IP = 16 # 针对IP并发 COOKIES_ENABLED = False # 默认为True 请求是否携带cookies TELNETCONSOLE_ENABLED = False # telnet 127.0.0.1 6023 监听当前爬虫的状态 True DEPTH_PRIORITY = 0 / 1 # 深度优先/广度优先
源码:from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
scrapy默认代理依赖环境
os.environ{ http_proxy:http://root:woshiniba@192.168.11.11:9999/ https_proxy:http://192.168.11.11:9999/ }
自定义代理
class ProxyMiddleware(object): def process_request(self, request, spider): PROXIES = [ {‘ip_port‘: ‘111.11.228.75:80‘, ‘user_pass‘: ‘‘}, {‘ip_port‘: ‘120.198.243.22:80‘, ‘user_pass‘: ‘‘}, ] proxy = random.choice(PROXIES) if proxy[‘user_pass‘] is not None: request.meta[‘proxy‘] = "http://%s" % proxy[‘ip_port‘] encoded_user_pass = base64.encodestring(proxy[‘user_pass‘]) request.headers[‘Proxy-Authorization‘] = b‘Basic ‘ + encoded_user_pass print "**************ProxyMiddleware have pass************" + proxy[‘ip_port‘] else: print "**************ProxyMiddleware no pass************" + proxy[‘ip_port‘] request.meta[‘proxy‘] = "http://%s" % proxy[‘ip_port‘] DOWNLOADER_MIDDLEWARES = { ‘step8_king.middlewares.ProxyMiddleware‘: 500, }
from fake_useragent import UserAgent # 用户代理模块 # 设置随机的用户代理 class RandomUserAgentMiddleware(object): def __init__(self,crawler): super(RandomUserAgentMiddleware,self).__init__() self.ua = UserAgent() @classmethod def from_crawler(cls,crawler): return cls(crawler) def process_request(self,request,spider): request.headers.setdefault(‘User-Agent‘,self.ua.random)
相当于把request交给了下载中间,返回response经过spider中间件给spider,scrapy中包含很多个下载中间件,可以在最后调用scrapy默认的中间件之前,可以自定义
页面下载器。所有的process_request下载完成后,后续中间件无需下载,process_response返回response给spider。
class DownMiddleware1(object): def process_request(self, request, spider): ‘‘‘ 请求需要被下载时,经过所有下载器中间件的process_request调用 None,继续后续中间件去下载; Response对象,停止process_request的执行,开始执行process_response Request对象,停止中间件的执行,将Request重新调度器 raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception ‘‘‘ pass def process_response(self, request, response, spider): ‘‘‘ process_request处理完成,返回时调用 Response 对象:转交给其他中间件process_response Request 对象:停止中间件,request会被重新调度下载 raise IgnoreRequest 异常:调用Request.errback ‘‘‘ print(‘response1‘) return response def process_exception(self, request, exception, spider): ‘‘‘ 当下载处理器(download handler)或 process_request() (下载中间件)抛出异常 None:继续交给后续中间件处理异常; Response对象:停止后续process_exception方法 Request对象:停止中间件,request将会被重新调用下载 ‘‘‘ return None # 执行顺序 DownMiddleware1 process_request DownMiddleware2 process_request DownMiddleware2 process_response DownMiddleware1 process_response spider.response
class SpiderMiddleware(object): def process_spider_input(self, response, spider): ‘‘‘ 下载完成,执行,然后交给parse处理 ‘‘‘ pass def process_spider_output(self, response, result, spider): ‘‘‘ spider处理完成,返回时调用 :return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable) ‘‘‘ return result def process_spider_exception(self, response, exception, spider): ‘‘‘ 异常调用 :return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline ‘‘‘ return None def process_start_requests(self, start_requests, spider): ‘‘‘ 爬虫启动时调用 :return: 包含 Request 对象的可迭代对象 ‘‘‘ return start_requests
标签:comm 内容 href hex 自定义 tput 传递 没有 drop
原文地址:https://www.cnblogs.com/Abc2149/p/9096259.html