标签:一点 nic 大于 度量 分析 智能 生成word 大致 label
嗨,大家晚上吼哇~许久没更新的SuperChen今天,,终终终于要更新博客了!都怪自己太懒了。话不多说,今天我要高调秀出自己为期一天的华师大Innocamp之旅~
也算是为周末做个总结了,希望大家能够喜欢
这次Innocamp在华东师范大学举办,主要是教育学院承办,所以主题也就是教育+AI
活动伊始,老师先简单介绍了,人工智能在教育学的简单应用,并着重在如何实现个性化教学与利用机器学习达到教学目标。
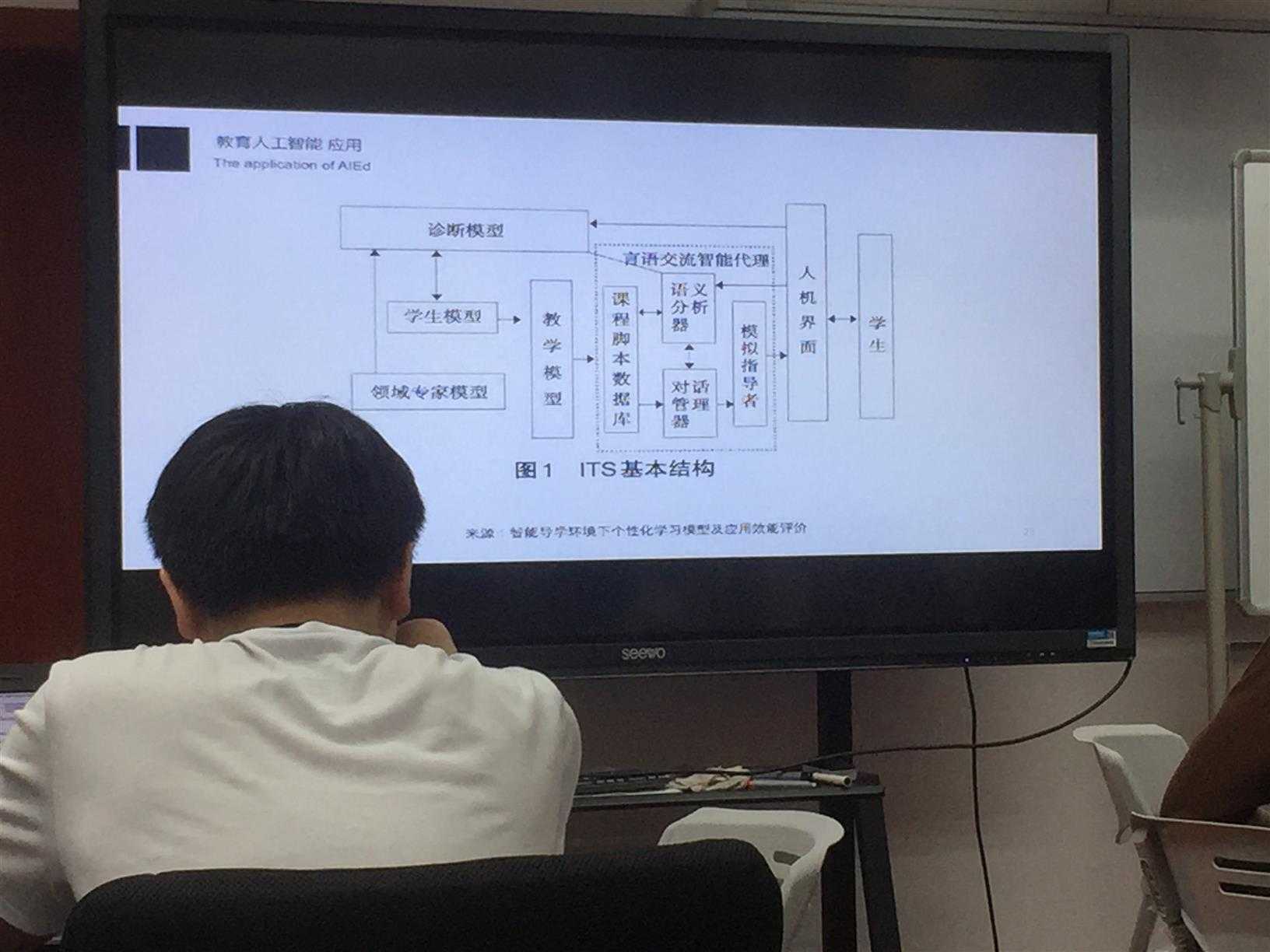
这是其中一个比较著名的教学框架ITS结构。
然后紧接着讲了如何利用AI进行学情预测、简化基础业务、通过AI实时反馈学生的听课情况,以及情绪分析。综述讲的比较琐碎,所以我也就大致记了一些概要。
接下来就是重头戏了,代码部分!说实话,这次Camp的代码难度也是一步步慢慢递进的,很适合初学者!接下来我会分几个阶段,慢慢分析

就是这位小哥哥辣,比个心~
Tensorflow基础
这一部分,首先介绍了TensorFlow基本的张量与计算图的概念,然后通过具体代码具体看了一下,具体的步骤应当是:定义Tensor -> 搭建计算图 -> 运行会话Session。所有的机器学习模型也就是建立在搭建计算图之上的。需要注意的是,TensorFlow的主要逻辑是,先定义计算图,全部搭建完成之后再Run Session;而PyTorch则提供了边搭建、边执行的功能,可以说各有优劣吧。运行后的模型可通过tensorboard进行查看(注意先要进行tf.summary.FileWriter(‘./logs/summary‘, sess.graph),把数据写入logs当中)。重要代码在下方展示:
import tensorflow as tf
graph = tf.Graph()
with graph.as_default():
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
y = tf.multiply(a,b)
with tf.Session(graph=graph) as sess:
print(sess.run(y,feed_dict={a:3,b:3}))Sentiment Analysis语义分析
这一块主要建立在上面的基础之上,建立词典之后,也就意味着有了词向量的关系。接着,我们可以用LSTM这个模型进行情感分析(其实情感分析与语义分析很像)。
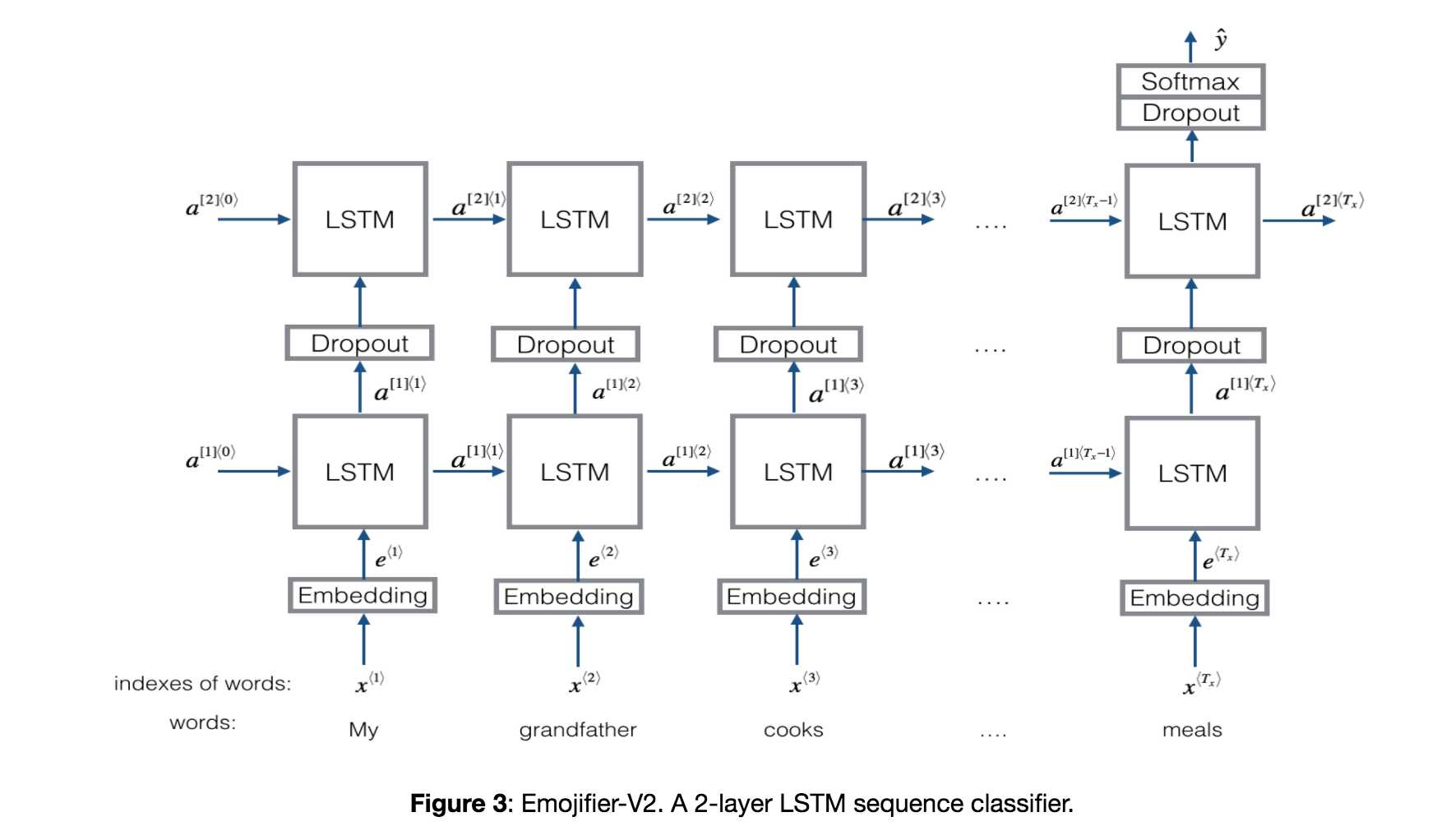
LSTM(Long Short Term Memory):通常输入的是一个个词向量,与RNN相似,通过一系列计算,还有最后的softmax整合,输出的是一个概率,分别代表可能性是多少,最后就可以转为是否的二分问题了
Emmmm关于LSTM,不想说太多,感觉实在是太复杂了=_=论文看的心累,而且之前看吴恩达的视频的时候,就非常理论2333。情感分析也是教育学一个重要的方向,在不久的将来,如果机器能捕捉到人类的情感的话,就能更好的服务人类了(当然也可能背叛人类了2333)以下是一些关键代码,我直接复制粘贴了:
# 构造计算图
graph = tf.Graph()
with graph.as_default():
tf_train_dataset = tf.placeholder(tf.float32, shape=(None, MAX_SIZE, vector_size),name=‘x‘)
tf_train_steps = tf.placeholder(tf.int32, shape=(None),name=‘x_step‘)
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, output_size))
# tf_test_dataset = tf.constant(testData, tf.float32,name=‘input_x‘)
# tf_test_steps = tf.constant(testSteps, tf.int32,name=‘steps‘)
tf_test_dataset = tf.placeholder(tf.float32, shape=(None, MAX_SIZE, vector_size), name=‘input_x‘)
tf_test_steps = tf.placeholder(tf.int32, shape=(None), name=‘steps‘)
lstm_cell = tf.contrib.rnn.BasicLSTMCell(num_units=num_nodes,
state_is_tuple=True)
w1 = tf.Variable(tf.truncated_normal([num_nodes, num_nodes // 2], stddev=0.1))
b1 = tf.Variable(tf.truncated_normal([num_nodes // 2], stddev=0.1))
w2 = tf.Variable(tf.truncated_normal([num_nodes // 2, 2], stddev=0.1))
b2 = tf.Variable(tf.truncated_normal([2], stddev=0.1))
def model(dataset, steps):
outputs, last_states = tf.nn.dynamic_rnn(cell=lstm_cell,
dtype=tf.float32,
sequence_length=steps,
inputs=dataset)
hidden = last_states[-1]
hidden = tf.matmul(hidden, w1) + b1
logits = tf.matmul(hidden, w2) + b2
return logits
train_logits = model(tf_train_dataset, tf_train_steps)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels,
logits=train_logits))
optimizer = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
test_prediction = tf.nn.softmax(model(tf_test_dataset, tf_test_steps))
tf.add_to_collection(‘pred_network‘, test_prediction) #用于加载模型获取要预测的网络结构
#保存模型
saver = tf.train.Saver()此处为构造计算图
到此处,我的总结也结束啦,最后贴上一张合照,以作纪念!我觉得,这次的活动主办方还是非常给力的,各方面准备都很棒,谢谢各位志愿者,谢谢老师的奉献~

最后,嗯,妹子真多,再跟本校比比,不说了,我还是继续写代码了=_=
标签:一点 nic 大于 度量 分析 智能 生成word 大致 label
原文地址:https://www.cnblogs.com/EchoWorld/p/9102723.html