标签:pad 类型 children add 名称 poc 查找 存在 exist
Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储, Zookeeper 作用主要是用来维护和监控存储的数据的状态变化,通过监控这些数据状态的变化,从而达到基于数据的集群管理。
像数据结构当中的树,也很像文件系统的目录。基于节点,这种节点叫做Znode。Znode的引用方式是路径引用,类似于文件路径
Znode内容:
注意,Zookeeper是为读多写少的场景所设计。Znode并不是用来存储大规模业务数据,而是用于存储少量的状态和配置信息,每个节点的数据最大不能超过1MB。
Znode类型:
Zookeeper基本操作:
Zookeeper客户端在请求读操作的时候,可以选择是否设置Watch。
当这个Znode发生改变(create,delete,setData),将会触发Znode上注册的对应事件,请求Watch的客户端会接收到异步通知。
具体交互过程如下:
1.客户端调用getData方法,watch参数是true。服务端接到请求,返回节点数据,并且在对应的哈希表里插入被Watch的Znode路径,以及Watcher列表。
2.当被Watch的Znode已删除,服务端会查找哈希表,找到该Znode对应的所有Watcher,异步通知客户端,并且删除哈希表中对应的Key-Value。
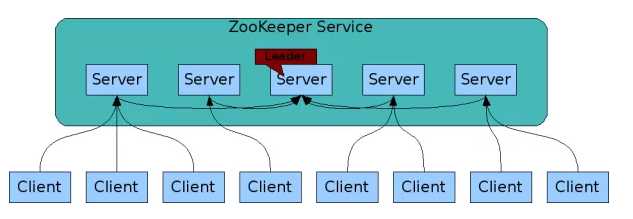
Zookeeper Service集群是一主多从结构。
在更新数据时,首先更新到主节点(这里的节点是指服务器,不是Znode),再同步到从节点。
在读取数据时,直接读取任意从节点。
Zookeeper角色介绍:
问题1:如何保证主从节点的数据一致性?
为了保证主从节点的数据一致性,Zookeeper采用了ZAB协议,这种协议非常类似于一致性算法Paxos和Raft。
Zab协议既不是强一致性,也不是弱一致性,而是处于两者之间的单调一致性。它依靠事务ID和版本号,保证了数据的更新和读取是有序的。
ZAB协议所定义的三种节点状态:
假如Zookeeper当前的主节点挂掉了,集群会进行崩溃恢复。ZAB的崩溃恢复分成三个阶段:
1.Leader election 选举阶段,此时集群中的节点处于Looking状态。
它们会各自向其他节点发起投票,投票当中包含自己的服务器ID和最新事务ID(ZXID)。
接下来,节点会用自身的ZXID和从其他节点接收到的ZXID做比较,如果发现别人家的ZXID比自己大,也就是数据比自己新,那么就重新发起投票,投票给目前已知最大的ZXID所属节点。
每次投票后,服务器都会统计投票数量,判断是否有某个节点得到半数以上的投票。如果存在这样的节点,该节点将会成为准Leader,状态变为Leading。其他节点的状态变为Following。
2.Discovery 发现阶段,用于在从节点中发现最新的ZXID和事务日志。
Leader接收所有Follower发来各自的最新epoch值。Leader从中选出最大的epoch,基于此值加1,生成新的epoch分发给各个Follower。
各个Follower收到全新的epoch后,返回ACK给Leader,带上各自最大的ZXID和历史事务日志。Leader选出最大的ZXID,并更新自身历史日志。
3.Synchronization 同步阶段,把Leader刚才收集得到的最新历史事务日志,同步给集群中所有的Follower。只有当半数Follower同步成功,这个准Leader才能成为正式的Leader。
问题2:如何保证保证事务的顺序一致性?
zookeeper采用了递增的事务编号(zxid)来标识事务。zxid是一个64位的数字,包含epoch和计数两部分,高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch。低32位用于递增计数。
问题3:ZAB是怎么实现写入数据的?
更新数据的时候,由Leader广播到所有的Follower。其过程如下:
1.客户端发出写入数据请求给任意Follower。
2.Follower把写入数据请求转发给Leader。
3.Leader采用二阶段提交方式,先发送Propose广播给Follower。
4.Follower接到Propose消息,写入日志成功后,返回ACK消息给Leader。
5.Leader接到半数以上ACK消息,返回成功给客户端,并且广播Commit请求给Follower。
1.分布式锁
利用Zookeeper的临时顺序节点,可以轻松实现分布式锁。
2.服务注册和发现
利用Znode和Watcher,可以实现分布式服务的注册和发现。最著名的应用就是阿里的分布式RPC框架Dubbo。
3.共享配置和状态信息
Redis的分布式解决方案Codis,就利用了Zookeeper来存放数据路由表和 codis-proxy 节点的元信息。同时 codis-config 发起的命令都会通过 ZooKeeper 同步到各个存活的 codis-proxy。
此外,Kafka、HBase、Hadoop,也都依靠Zookeeper同步节点信息,实现高可用。
标签:pad 类型 children add 名称 poc 查找 存在 exist
原文地址:https://www.cnblogs.com/mcahkf/p/9115811.html