标签:spi 贴吧 col gen input div idt __init__ alt
工具:python3
问题:在执行loadPage时遇到了问题,
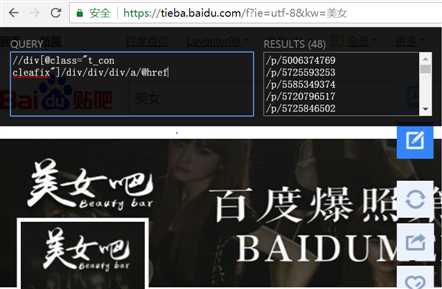
link_list = content.xpath(‘//div[@class="t_con cleafix"]/div/div/div/a/@href‘)
这个正则表达式在xpath helper中能够找到对应的href值,如图:
但是在在执行程序时 link_list = content.xpath(‘//div[@class="t_con cleafix"]/div/div/div/a/@href‘) 返回的列表值为空,如图:
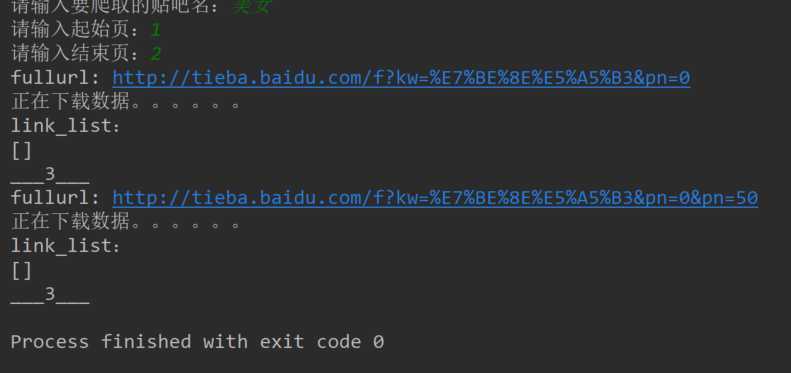
尝试进入两个输出的fullurl均能正确进入网页,说明上一步传入的网址是没有错误的呀!
到底是什么原因呢?
import urllib.request import re from lxml import etree class Spider: def __init__(self): self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36", } def loadPage(self, link): """ 下载页面 """ print("正在下载数据。。。。。。") request = urllib.request.Request(link, headers=self.headers) html = urllib.request.urlopen(request).read() # html = html.decode("utf-8") with open("meinvba.txt", "w") as f: f.write(str(html)) # 获取每页的HTML源码字符串 # html = html.decode("gbk") # 解析html文档为HTML DOM类型 content = etree.HTML(html) print(content) # 返回所有匹配成功的列表集合 link_list = content.xpath(‘//div[@class="t_con cleafix"]/div/div/div/a/@href‘) print(link_list) for i in link_list: print("__4__") fulllink = "http://tieba.baidu.com" + i self.loadImage(fulllink) print("___3___") # 取出每个帖子的图片链接 def loadImage(self, link): request = urllib.request.Request(link, headers=self.headers) html = urllib.request.urlopen(request).read() content = etree.HTML(html) link_list = content.xpath(‘//img[@class="BDE_Image"]/@src‘) print("____1____") for link in link_list: self.writeImage(link) def writeImage(self, link): request = urllib.request.Request(link, headers=self.headers) image = urllib.request.urlopen(request).read() filename = link[-5:] print("___2____") with open(filename, "wb") as f: f.write(image) print("*"*30) def startWork(self, kw, beginpage, endpage): """ 控制爬虫运行 """ url = "http://tieba.baidu.com/f?" key = urllib.parse.urlencode({"kw": kw}) print("key:" + key) fullurl = url + key for page in range(int(beginpage), int(endpage) + 1): pn = (page - 1)*50 fullurl = fullurl + "&pn=" + str(pn) self.loadPage(fullurl) # print("fullurl:" + fullurl) if __name__ == "__main__": tiebaSpider = Spider() kw = input("请输入要爬取的贴吧名:") beginpage = input("请输入起始页:") endpage = input("请输入结束页:") tiebaSpider.startWork(kw, beginpage, endpage)
好想知道哪里出了错误啊!!!
爬虫(Xpath)——爬tieba.baidu.com (bug)
标签:spi 贴吧 col gen input div idt __init__ alt
原文地址:https://www.cnblogs.com/gaoquanquan/p/9120871.html