标签:包括 最小 多个 分布 XA 通过 聚类 SM scipy
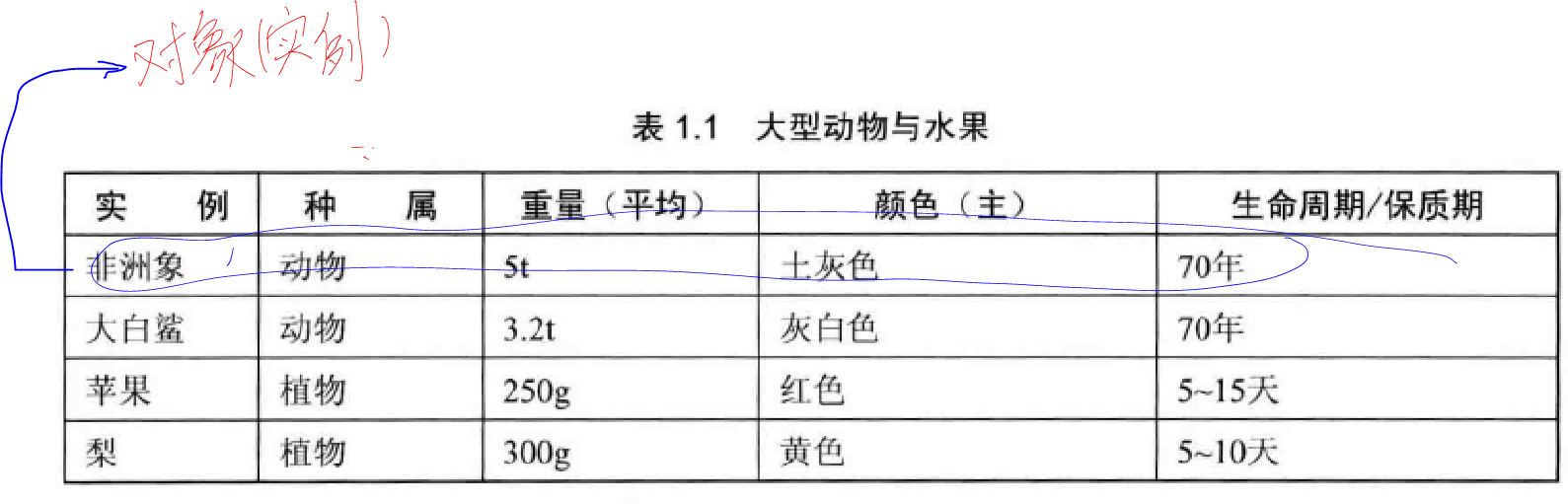
一般而言,一个对象应该被视为完整的个体,表现实中有意义的事物,不能轻易拆分。
对象是被特征化的客观事物,而表(或矩阵)是容纳这些对象的容器。换句话说,对象是表中的元素,表是对象的集合(表中的每个对象都有相同的特征和维度,对象对于每个特征都有一定的取值)。
分类或聚类可以看作根据对象特征的相似性与差异性,对矩阵空间的一种划分。
预测或回归可以看作根据对象在某种序列(时间)上的相关性,表现为特征取值变化的一种趋势。
import numpy as npa = np.arange(9).reshape((3, -1))
aarray([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])b = a.copy()id(a) == id(b)Falserepr(a) == repr(b)TrueA = np.mat([[1, 2, 4, 5, 7], [9,12 ,11, 8, 2], [6, 4, 3, 2, 1], [9, 1, 3, 4, 5], [0, 2, 3, 4 ,1]])np.linalg.det(A)-812.00000000000068np.linalg.inv(A)matrix([[ -7.14285714e-02, -1.23152709e-02, 5.29556650e-02,
9.60591133e-02, -8.62068966e-03],
[ 2.14285714e-01, -3.76847291e-01, 1.22044335e+00,
-4.60591133e-01, 3.36206897e-01],
[ -2.14285714e-01, 8.25123153e-01, -2.04802956e+00,
5.64039409e-01, -9.22413793e-01],
[ 5.11521867e-17, -4.13793103e-01, 8.79310345e-01,
-1.72413793e-01, 8.10344828e-01],
[ 2.14285714e-01, -6.65024631e-02, 1.85960591e-01,
-8.12807882e-02, -1.46551724e-01]])A.Tmatrix([[ 1, 9, 6, 9, 0],
[ 2, 12, 4, 1, 2],
[ 4, 11, 3, 3, 3],
[ 5, 8, 2, 4, 4],
[ 7, 2, 1, 5, 1]])A * A.Tmatrix([[ 95, 131, 43, 78, 43],
[131, 414, 153, 168, 91],
[ 43, 153, 66, 80, 26],
[ 78, 168, 80, 132, 32],
[ 43, 91, 26, 32, 30]])np.linalg.matrix_rank(A)5\[Ax = b\]
b = [1, 0, 1, 0, 1]
S = np.linalg.solve(A, b)
Sarray([-0.0270936 , 1.77093596, -3.18472906, 1.68965517, 0.25369458])现代数学三大基石:
比较常见是范数(如欧式距离(\(L_2\))、曼哈顿距离(\(L_1\))、切比雪夫距离(\(L_{\infty}\)))和夹角余弦。下面我主要说明一下其他的几个比较有意思的度量:
定义:两个等长字符串 s1 与 s2 之间的汉明距离定义为将其中一个变成另外一个所需要的最小替换次数。
应用:信息编码(为了增强容错性,应该使得编码间的最小汉明距离尽可能大)。
A = np.mat([[1, 1, 0, 1, 0, 1, 0, 0, 1], [0, 1, 1, 0, 0, 0, 1, 1, 1]])
smstr = np.nonzero(A[0] - A[1])A[0] - A[1]matrix([[ 1, 0, -1, 1, 0, 1, -1, -1, 0]])smstr(array([0, 0, 0, 0, 0, 0], dtype=int64),
array([0, 2, 3, 5, 6, 7], dtype=int64))d = smstr[0].shape[0]
d6相似度:
\[
J(A, B) = \frac{|\;A \bigcap B\;|}{|\;A \bigcup B\;|}
\]
区分度:
\[
J_{\delta}(A, B) = 1 - J(A, B) = 1 - \frac{|\;A \bigcap B\;|}{|\;A \bigcup B\;|}
\]
应用:
样本 \(A\) 和样本 \(B\) 所有维度的取值为 \(0\) 或 \(1\),表示包含某个元素与否。
import scipy.spatial.distance as distAmatrix([[1, 1, 0, 1, 0, 1, 0, 0, 1],
[0, 1, 1, 0, 0, 0, 1, 1, 1]])dist.pdist(A, ‘jaccard‘)array([ 0.75])总而言之,系统运动大的范围是确定的、可测的,但是运动的细节是随机的、不可测的。
从统计学角度来看,蝴蝶效应说明了:
随机性是事物的一种根本的、内在的、无法根除的性质,也是一切事物(概率)的本质属性。
衡量事物运动的随机性,必须从整体而不是局部来认知事物,因为从每个局部,事物可能看起来都是不同的(或相同的)。
概率论便是度量随机性的一个工具。一般地,上述所说的矩阵,被称为设计矩阵,基本概念重写:
由特征列的取值所构成的矩阵空间应具有完整性,即能够反映事物的空间形式或变换规律。
向量:具有大小和方向。
向量与矩阵的乘积就是一个向量从一个线性空间(坐标系),通过线性变换,选取一个新的基底,变换到这个新的基底所构成的另一个线性空间的过程。
矩阵与矩阵的乘法 \(C = A \cdot B\):
假设我们考察一组对象 \(\scr{A} = \{\alpha_1, \cdots, \alpha_m\}\),它们在两个不同维度的空间 \(V^n\) 和 \(V^p\) 的基底分别是 \(\{\vec{e_1}, \cdots, \vec{e_n}\}\) 和 \(\{\vec{d_1}, \cdots, \vec{d_p}\}\),\(T\) 即为 \(V^n\) 到 \(V^p\) 的线性变换,且有(\(k = \{1, \cdots, m\}\)):
\[
\begin{align}
&T
\begin{pmatrix}
\begin{bmatrix}
\vec{e_1} \\ \vdots \\ \vec{e_n}
\end{bmatrix}
\end{pmatrix} =
A
\begin{bmatrix}
\vec{d_1} \\ \vdots \\ \vec{d_p}
\end{bmatrix} \&\alpha_k =
\begin{bmatrix}
x_1^{k} & \cdots & x_n^k
\end{bmatrix}
\begin{bmatrix}
\vec{e_1} \\ \vdots \\ \vec{e_n}
\end{bmatrix}\&T(\alpha_k)=
\begin{bmatrix}
y_1^{k} & \cdots & y_p^k
\end{bmatrix}
\begin{bmatrix}
\vec{d_1} \\ \vdots \\ \vec{d_p}
\end{bmatrix}
\end{align}
\]
令
\[
\begin{cases}
&X^k =
\begin{bmatrix}
x_1^{k} & \cdots & x_n^k
\end{bmatrix}\&Y^k =
\begin{bmatrix}
y_1^{k} & \cdots & y_p^k
\end{bmatrix}
\end{cases}
\]
则记:
\[
\begin{cases}
&X =
\begin{bmatrix}
X^{1} \\ \vdots \\ X^m
\end{bmatrix} \&Y = \begin{bmatrix}
Y^{1} \\ \vdots \\ Y^m
\end{bmatrix}
\end{cases}
\]
由式(1)可知:
\[
\begin{align}
XA = Y
\end{align}
\]
因而 \(X\) 与 \(Y\) 表示一组对象在不同的线性空间的坐标表示。\(A\) 表示线性变换在某个基偶(如,\((\{\vec{e_1}, \cdots, \vec{e_n}\}, \{\vec{d_1}, \cdots, \vec{d_p}\})\))下的矩阵表示。
标签:包括 最小 多个 分布 XA 通过 聚类 SM scipy
原文地址:https://www.cnblogs.com/q735613050/p/9126826.html