标签:port ike etc line lines 复制 remove nal 选项
注释:基础不牢固,特别不牢固,项目无从下手!
这次花一个星期的时间把Python的基础库学习一下,一来总结过去的学习,二来为深度学习打基础。
部分太简单,或者映象很深的就不记录了,避免浪费时间。博客园的makedown真是无语了,排版好久,上传就是这个鬼模样
[TOC]
print("abc".upper())#转为大写
print("ABC".lower())#转为小写
print("abc"+"abc")#合并
print("abc ".rstrip())#删除最右边(结尾)的空白(不改变"abc "的档案,只是结果删除)
print(" abc".lstrip())#删除最左边(开头)空白
print("abc".title())#首字母变成大写ABC
abc
abcabc
abc
abc
Abc#整数和浮点数不能直接相乘
3*0.1 0.3000000000004list[0] #第一个元素
list[-1]#最后一个元素
list[:] #打印全部元素
list[0:-1]#打印不包括最后一个元素
list[a:b:c]#打印a-b,间隔为c
list[0::-1]#颠倒数据list.append('data')#正常添加一个元素
list.extend("data")#添加一个列表数据
list.insert(num,'data')#从num位置插入一个数据
del list[num]#删除num位置元素
list.remove('data')#删除名字为"data"的数据
list.sort(bool)#排序列表(永久)
sorted(list)#排序列表(临时排序)
list.reverse()#颠倒列表,可用上面"读写列表的list[0::-1]进行颠倒"
len(list)#列表长度
min(list)
max(list)list1 = list2#浅复制
list1 = list2[1:2]#深度复制# 循环列表
values = [10,20,4,50.31]
squres = []
for x in values:
squres.append(x)
print(squres)[10, 20, 4, 50.31]#列表推导式
values = [10,20,4,50.31]
squres = [x for x in values]
print(squres)[10, 20, 4, 50.31]#推导式中加入条件进行筛选
values = [10,20,4,50.31]
squres = [x**2 for x in values if x<=12]
squres[100, 16]#推导式生成集合和字典
values = [10,20,4,50.31]
squres_set = {x**2 for x in values if x<=12}
squres_dict = {x:x**2 for x in values}
print(squres_set)
squres_dict{16, 100}
{4: 16, 10: 100, 20: 400, 50.31: 2531.0961}#求和表达式
values = [10,20,4,50.31]
sum(x**2 for x in values)3047.0961A if B else C #B==True-->>A B==False-->>Cdict.items() #得到[(key,value),(key,value)...]
dict.keys() #得到key
dict.values()#得到values
del dict[key]#删除某个键-值对
dict[key]=value#更改某个键值对break #跳出大循环
continue#跳出小循环#内部函数
def fuction(num):
return (num)
fuction1 = fuction('hello')
print(fuction1)
#外部函数调用
import fuction
fuction1 = fuction.fuction('hello')
print(fuction1)
#调用外部特定函数
from fuction import fuction
fuction1 = fuction('hello')
print(fuction1)
#调用函数之后指定别名
import fuction as fuc
fuction1 = fuc.fuction('hello')
print(fuction1)
from fuction import fuction as fuc
fuction1 = fuc('hello')
print(fuction1)#内部创建类
#self相当于C++的this指针
class Dog():
#num1和num2是输入的形参
def __init__(self,num1,num2):
#num3和num4是函数内部使用的参数
self.num3 = num1
self.num4 = num2
def printf(self):
print(self.num3)
def sum1(self):
print(self.num3+self.num4)
my_dog = Dog(32,'jake')
#外部创建类
import dog
my_dog = dog.Dog(23,'rake')
from dog import Dog
my_dog = Dog(23,'rake')#类的继承
class Dog():
def __init__(self,num1,num2):
self.num3 = num1
self.num4 = num2
def printf(self):
return self.num3
def sum1(self):
print(self.num3+self.num4)
class Cdog(Dog):
def __init__(self,num1,num2):
super().__init__(num1,num2)
self.num3 = super().printf()
my_dog = Cdog(23,'rake')
print(my_dog.num3)#读取文件
'''with的作用是不再访问程序的时候关闭程序'''
'''close()的作用是直接关闭程序,用 with 比较好'''
with open('test.txt') as file_object:
contents = file_object.read()
print(contents)
#读取文件内容成一行
with open('test.txt') as file_object:
contents = file_object.readlines()#行读取
print(contents[:42] + '...')#写入文件
#'w':格式化以后输入
#'a':在原来基础上输入
with open('test.txt','w') as file_object:
file_object = 'hello world'
'''先输入int、float类型的时候得转化成str''' #简单扩展
#zip(a,b)返回一个tuple
a = [1,2,3]
b = [4,5,6]
ab = zip(a,b)
ab = [(1, 4), (2, 5), (3, 6)]
#lambda
#x,y为自变量,x+y为具体运算
fun = lambda x,y:x+y
num = fun(x,y)
#map是把函数和参数绑定在一起
map(函数(迭代器),参数)#把函数和参数卸载一起了
>>> def fun(x,y):
return (x+y)
>>> list(map(fun,[1],[2]))
"""
[3]
"""
>>> list(map(fun,[1,2],[3,4]))
"""
[4,6]
"""os模块主要是对系统~文件~目录等进行操作
os.listdir(path)----#返回指定目录下的所有文件和目录名。在读取文件的时候经常用到!
os.getcwd()-------#函数得到当前工作目录,即当前Python脚本工作的目录路径。读写文件常用!
os.path.join(path,name)---#连接目录与文件名或目录;使用“\”连接,保存文件路径常用
注意一下:#name前面如果没有‘\’,系统会自动添加!如:print(os.path.join("C:\wjy",name.txt))----->>>>C\:wjy\name.txt举两个例子:
#把某个文件夹的内部文件(二层目录)路径全部写到一个txt文档之中
import os
import re
def createFileList(path,txt_path):
fw = open(txt_path,'w+')
image_files = os.listdir(path)
for i in range(len(image_files)):
dog_categories = os.listdir(path+'/'+image_files[i])
for each_image in dog_categories:
fw.write(path+'/'+image_files[i]+'/'+ each_image + ' %d\n'%i)
print('生成txt文件成功\n')
fw.close()
path = 'dog_10_images'
txt_path = 'train.txt'
createFileList(path,txt_path)# TF模型保存的路径和文件名。
MODEL_SAVE_PATH = "saves_model_path"
MODEL_NAME = "model.ckpt"
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME),global_step=global_step)os常用命令如下,就不一一列举了:
os.sep#可以取代操作系统特定的路径分隔符。windows下为 “\\”
os.name#字符串指示你正在使用的平台。比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'。
os.getcwd()#函数得到当前工作目录,即当前Python脚本工作的目录路径。
os.getenv()#获取一个环境变量,如果没有返回none
os.putenv(key, value)#设置一个环境变量值
os.listdir(path)#返回指定目录下的所有文件和目录名。
os.remove(path)#函数用来删除一个文件。
os.system(command)#函数用来运行shell命令。
os.linesep#字符串给出当前平台使用的行终止符。例如,Windows使用'\r\n',Linux使用'\n'而Mac使用'\r'。
os.curdir:#返回当前目录('.')
os.chdir(dirname):#改变工作目录到dirname
========================================================================================
os.path#常用方法:
os.path.isfile()和os.path.isdir()#函数分别检验给出的路径是一个文件还是目录。
os.path.exists()#函数用来检验给出的路径是否真地存在
os.path.getsize(name):#获得文件大小,如果name是目录返回0L
os.path.abspath(name):#获得绝对路径
os.path.normpath(path):#规范path字符串形式
os.path.split(path) :#将path分割成目录和文件名二元组返回。
os.path.splitext():#分离文件名与扩展名
os.path.join(path,name):#连接目录与文件名或目录;使用“\”连接
os.path.basename(path):#返回文件名
os.path.dirname(path):#返回文件路径用于命令行参数操作,常使用在远程演示操作!
以下是一个简单的操作:
#定位参数,必须指定
parser = argparse.ArgumentParser()
parser.add_argument("integer",type=int,help="display an integer",name="--h")
args = parser.parse_args()
print(args.integer)#选择参数,带有"--"形式的,是可选的参数
parser = argparse.ArgumentParser()
parser.add_argument("--square",type = int ,help = "display a square of a given number")
parser.add_argument("--cubic",type = int,help = "display a cubic of a given number")
args = parser.parse_args()
if args.square:
print(args.square**2)
if args.cubic:
print(args.cubic**3)parser = argparse.ArgumentParser(description = "Process some integer")
parser.add_argument("integers",metavar="N",type=int,nargs="+",help="an integer for the accumulator")
parser.add_argument("--sum",dest="accumulate",action="store_const",const=sum,default=max,help="sum the integers(default: find the max)")
args = parser.parse_args()
print(args.accumulate(args.integers))以最后一个例子说明:
? description:描述我们这程序是干什么的,Str输入
metavar:是在命令行解释器的时候用来说明参数的
nargs:说明有多个定位参数,也就是输入 1 3 5 7 9 可以把这五个数都识别
具体参数指定如下:
具体参数指定如下:
name or flags - #选项字符串的名字或者列表,例如 foo 或者 -f, --foo。
action - #命令行遇到参数时的动作,默认值是 store。nargs - 应该读取的命令行参数个数,可以是具体的数字,或者是?号,当不指定值时对于 Positional argument 使用 default,对于 Optional argument 使用 const;或者是 * 号,表示 0 或多个参数;或者是 + 号表示 1 或多个参数。
store_const,#表示赋值为const;
append,#将遇到的值存储成列表,也就是如果参数重复则会保存多个值;
append_const,#将参数规范中定义的一个值保存到一个列表;
count,#存储遇到的次数;此外,也可以继承 argparse.Action 自定义参数解析;
nargs - #应该读取的命令行参数个数,可以是具体的数字,或者是?号,当不指定值时对于 Positional argument 使用 default,对于 Optional argument 使用 const;或者是 * 号,表示 0 或多个参数;或者是 + 号表示 1 或多个参数。
const - action 和 nargs 所需要的常量值。
default - #不指定参数时的默认值。
type - #命令行参数应该被转换成的类型。
choices - #参数可允许的值的一个容器。
required - #可选参数是否可以省略 (仅针对可选参数)。
help - #参数的帮助信息,当指定为 argparse.SUPPRESS 时表示不显示该参数的帮助信息.
metavar - #在 usage 说明中的参数名称,对于必选参数默认就是参数名称,对于可选参数默认是全大写的参数名称.
dest - #解析后的参数名称,默认情况下,对于可选参数选取最长的名称,中划线转换为下划线.re模块主要是操作正则表达式内容,它能帮助我们方便的检查一个字符串是否与某种模式匹配
不用可以去学习,大概了解就行了,到时候用的时候再去查询
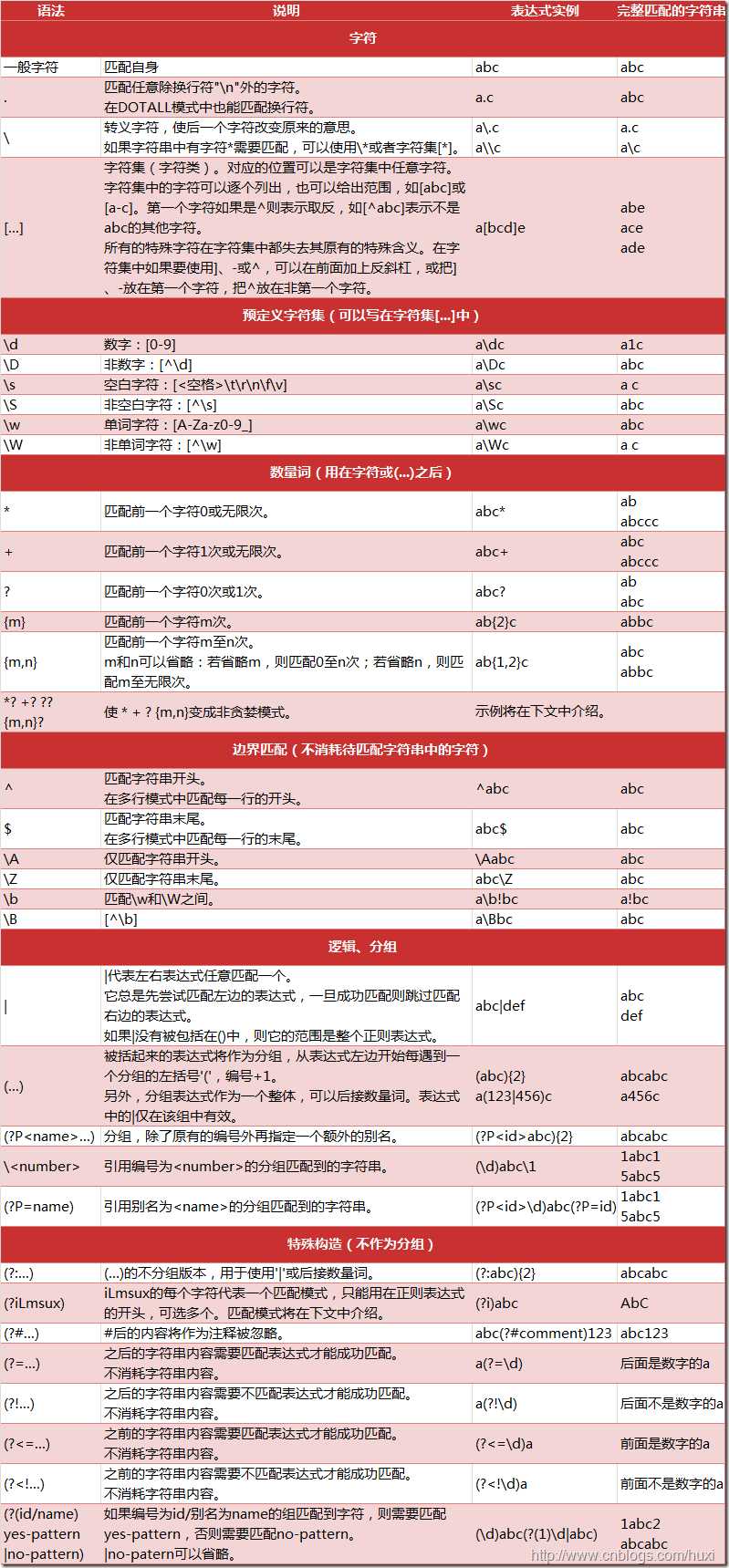
将字符串形式的正则表达式编译为Pattern对象
| compile(pattern,flags= 0) | 使用任何可选的标记来编译正则表达式的模式,然后返回一个正则表达式对象 |
|---|---|
| match(pattern,string,flags=0) | 尝试使用带有可选的标记的正则表达式的模式来匹配字符串。如果匹配成功,就返回 匹配对象; 如果失败,就返回 None |
|---|---|
| search(pattern,string,flags=0) | 使用可选标记搜索字符串中第一次出现的正则表达式模式。 如果匹配成功,则返回匹 配对象; 如果失败,则返回 None |
| findall(pattern,string[, flags] )① | 查找字符串中所有(非重复)出现的正则表达式模式,并返回一个匹配列表 |
| finditer(pattern,string[, flags] )② | 与 findall()函数相同,但返回的不是一个列表,而是一个迭代器。 对于每一次匹配,迭 代器都返回一个匹配对象 |
| split(pattern,string,max=0)③ | 根据正则表达式的模式分隔符, split函数将字符串分割为列表,然后返回成功匹配的 列表,分隔最多操作 max 次(默认分割所有匹配成功的位置) |
| sub(pattern,repl,string,count=0)③ | 使用 repl 替换所有正则表达式的模式在字符串中出现的位置,除非定义 count, 否则就 将替换所有出现的位置( 另见 subn()函数,该函数返回替换操作的数目) |
|---|---|
| purge() | 清除隐式编译的正则表达式模式 |
| group(num=0) | 返回整个匹配对象,或者编号为 num的特定子组 |
|---|---|
| groups(default=None) | 返回一个包含所有匹配子组的元组(如果没有成功匹配,则返回一个空元组) |
| groupdict(default=None) | 返回一个包含所有匹配的命名子组的字典,所有的子组名称作为字典的键(如果没有 成功匹配,则返回一个空字典) |
| re.I、 re.IGNORECASE | 不区分大小写的匹配 |
|---|---|
| re.L、 re.LOCALE | 根据所使用的本地语言环境通过\w、\W、\b、\B、\s、\S实现匹配 |
| re.M、 re.MULTILINE | ^和$分别匹配目标字符串中行的起始和结尾,而不是严格匹配整个字符串本身的起始 和结尾 |
| re.S、 rer.DOTALL | “.” (点号)通常匹配除了\n(换行符)之外的所有单个字符;该标记表示“.” (点号) 能够匹配全部字符 |
| re.X、 re.VERBOSE | 通过反斜线转义, 否则所有空格加上#(以及在该行中所有后续文字)都被忽略,除非 在一个字符类中或者允许注释并且提高可读性 |
下面举例说明几个常用函数和主要事项:
#span代表匹配的位置
#<_sre.SRE_Match object; span=(0, 3), match='www'>
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配(0, 3)
(11, 14)# *的作用是匹配前一个字符1次或者无数次
''' "e"="e" 只能匹配一次'''
print(re.split(r'e','one1two2three3four4'))
# out:['on', '1two2thr', '', '3four4']
''' "e+"="e"+"ee"+"eee"+"eee..." 匹配很多个类型'''
print(re.split(r'e+','one1two2three3four4'))
# out:['on', '1two2thr', '3four4']
''' \d+ 代表匹配很多次数字 '''
print(re.split(r'\d+','one1two2three3four4'))
# ['one', 'two', 'three', 'four', '']# '\d+' 匹配多个数字
print (p.findall(r'\d+','one1two2three3four4'))
# ['1', '2', '3', '4']
p = re.finditer(r'\d+','one1two2three3four4')
for i in p:
print(i.group())
# 1
# 2
# 3
# 4# '\w+' 匹配很多个单词,也就是遇到空格结束(换句话说匹配单词)
# r'(\w+) (\w+)' 匹配中间带空格的两个单词
# \<number> 分组匹配到的字符串
# r'\2 \1' 1和2的位置调换
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print (re.sub(r'(\w+) (\w+)',r'\2 \1', s))
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print (p.sub(func, s))
# say i, world hello!
# I Say, Hello World!注释:这个博文是针对之前的博文进行的总结,有些参考资料已经丢失,如果有侵权的地方请告知,马上删除或者添加遗漏的参考链接!
http://wiki.jikexueyuan.com/project/explore-python/Standard-Modules/argparse.html%E3%80%80
标签:port ike etc line lines 复制 remove nal 选项
原文地址:https://www.cnblogs.com/wjy-lulu/p/9131506.html