标签:词频统计 alt range 综合 item 字典 其他 excludes clu
本例是数组、字典、列表、jieba(第三方库)的综合应用,我们将对三国演义中出现次数前十的任务进行排名并统计出出现的次数。

程序1:
#CalThreeKingdomsV1.py
import jieba
txt = open("threekingdoms.txt", "r", encoding="utf-8").read()
words = jieba.lcut(txt) #利用jieba函数进行分词并返回列表类型
counts = {} #创建一个字典存储信息
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items()) #强制列表转换(列表中以元组对的形式存放)
items.sort(key=lambda x:x[1], reverse=True) #排序,从大到小
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
运行结果:
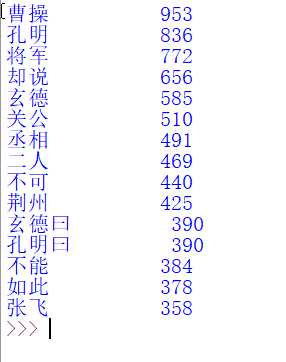
可以看出这个程序只是满足的要求,并未达到理想的效果,即结果中存在不是人名的词,对此我们要做出适当修改,修改后程序如下:
源程序2:
import jieba
excludes = {"将军","却说","荆州","二人","不可","不能","如此","如何","商议","军士","左右","引兵","军马","次日","大喜","天下","东吴","于是","今日","不散","魏兵","不敢","陛下","一人"}
txt = open("threekingdoms.txt", "r", encoding=‘utf-8‘).read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰" :
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
elif word == "都督" :
rword = "周瑜"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1 #将整理后的列表元素存入到字典中
for word in excludes:
del counts[word]#删除不合理的非人名元素
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
注意,这里excludes里面的元素是我们在运行中逐步添加的,直至达到我们理想中的要求。(本例中为前十位,可结合实际问题修改)
这个例子讲解的是三国演义的词频统计,我们还可以进行其他的应用,比如自己喜欢的文学作品或者小说,总之是一件很好玩的事情!
本文中所有文字、图片版权均属本人所有,如需转载请注明来源。
标签:词频统计 alt range 综合 item 字典 其他 excludes clu
原文地址:https://www.cnblogs.com/yufanxin/p/9134824.html