标签:master contain webui use order 解压 分布 you over
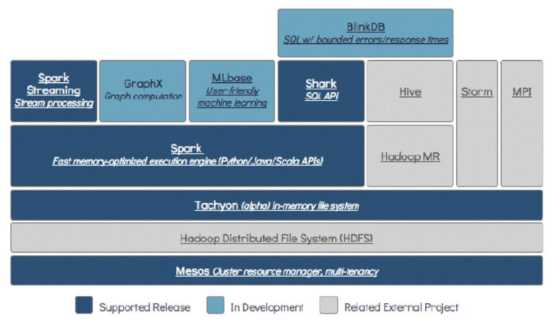
Apache Spark是一个快速且通用的集群计算系统。它提供Java,Scala,Python和R中的高级API以及支持通用执行图的优化引擎。是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark是Scala编写,方便快速编程。
官方下载地址:http://spark.apache.org/downloads.html
|
运行环境 |
模式 |
描述 |
|
Local |
本地模式 |
常用于本地开发测试,本地还分为local单线程和local-cluster多线程; |
|
Standalone |
集群模式 |
典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark支持ZooKeeper来实现HA |
|
On yarn |
集群模式 |
运行在yarn资源管理器框架之上,由yarn负责资源管理,Spark负责任务调度和计算 |
|
On mesos |
集群模式 |
运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算 |
|
术语 |
描述 |
|
Application |
Spark的应用程序,包含一个Driver program和若干Executor |
|
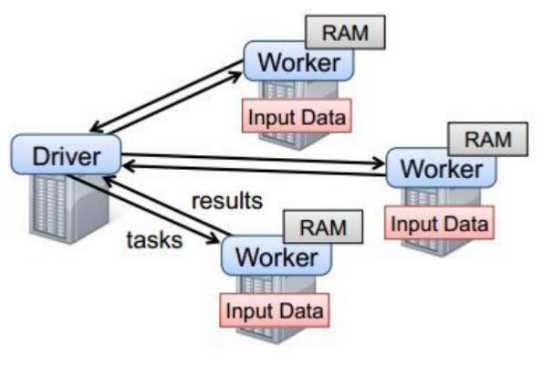
SparkContext |
Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor |
|
Driver Program |
运行Application的main()函数并且创建SparkContext |
|
Executor |
是为Application运行在Worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。 每个Application都会申请各自的Executor来处理任务 |
|
Cluster Manager |
在集群上获取资源的外部服务(例如:Standalone、Mesos、Yarn) |
|
Worker Node |
集群中任何可以运行Application代码的节点,运行一个或多个Executor进程 |
|
Task |
运行在Executor上的工作单元 |
|
Job |
SparkContext提交的具体Action操作,常和Action对应 |
|
Stage |
每个Job会被拆分很多组task,每组任务被称为Stage,也称TaskSet |
|
RDD |
是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类 |
|
DAGScheduler |
根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler |
|
TaskScheduler |
将Taskset提交给Worker node集群运行并返回结果 |
|
Transformations |
是Spark API的一种类型,Transformation返回值还是一个RDD, 所有的Transformation采用的都是懒策略,如果只是将Transformation提交是不会执行计算的 |
|
Action |
是Spark API的一种类型,Action返回值不是一个RDD,而是一个scala集合;计算只有在Action被提交的时候计算才被触发。 |
[admin@node21 software]$ tar zxvf spark-2.3.0-bin-hadoop2.7.tgz -C /opt/module/ [admin@node21 module]$ mv spark-2.3.0-bin-hadoop2.7 spark-2.3.0
[admin@node21 spark-2.3.0]$ sudo vi /etc/profile export SPARK_HOME=/opt/module/spark-2.3.0 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile
Local模式下spark基本测试:bin/spark-shell
[admin@node21 spark-2.3.0]$ bin/spark-shell 2018-06-05 03:47:16 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://node21:4040 Spark context available as ‘sc‘ (master = local[*], app id = local-1528184918749). Spark session available as ‘spark‘. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ ‘_/ /___/ .__/\_,_/_/ /_/\_\ version 2.3.0 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171) Type in expressions to have them evaluated. Type :help for more information. scala> sc.textFile("/opt/module/datas/wc.input") res0: org.apache.spark.rdd.RDD[String] = /opt/module/datas/wc.input MapPartitionsRDD[1] at textFile at <console>:25 scala> res0.collect res1: Array[String] = Array(hadoop habse hive, spark flink storm, sqoop spark hadoop, flume kafka) scala> sc.stop() scala> :quit
[admin@node21 software]$ tar zxvf spark-2.3.0-bin-hadoop2.7.tgz -C /opt/module/ [admin@node21 module]$ mv spark-2.3.0-bin-hadoop2.7 spark-2.3.0
2.1 修改slaves.template文件,添加从节点。
[admin@node21 conf]$ mv slaves.template slaves
[admin@node21 conf]$ vi slaves

2.2 修改spark-env.sh
[admin@node21 conf]$ mv spark-env.sh.template spark-env.sh
[admin@node21 conf]$ vi spark-env.sh
SPARK_MASTER_HOST=node21 #master的ip或主机名 SPARK_MASTER_PORT=7077 #提交任务的端口,默认是7077 SPARK_MASTER_WEBUI_PORT=8080 #masster节点的webui端口 SPARK_WORKER_CORES=2 #每个worker从节点能够支配的core的个数 SPARK_WORKER_MEMORY=3g #每个worker从节点能够支配的内存数 SPARK_WORKER_PORT=7078 #每个worker从节点的端口(可选配置) SPARK_WORKER_WEBUI_PORT=8081 #每个worker从节点的wwebui端口(可选配置) SPARK_WORKER_INSTANCES=1 #每个worker从节点的实例(可选配置)
2.3 配置spark-defaults.conf(可选配置)
配置spark-defaults.conf文件:不配置此选项运行spark服务还是在local模式下运行。 spark.master spark://node21:7077 ----------------------------------------------------------------------------- 如果没有配置此选项,也可以通过bin/spark-shell命令通过指定--master参数指定其运行在哪种模式下,例如: # bin/spark-shell --master spark://node21:7077 或者 # bin/spark-shell --master local
[admin@node21 module]$ scp -r spark-2.3.0 admin@node22:/opt/module/ [admin@node21 module]$ scp -r spark-2.3.0 admin@node23:/opt/module/
同步完成,配置node22,node23的环境变量
启动spark:
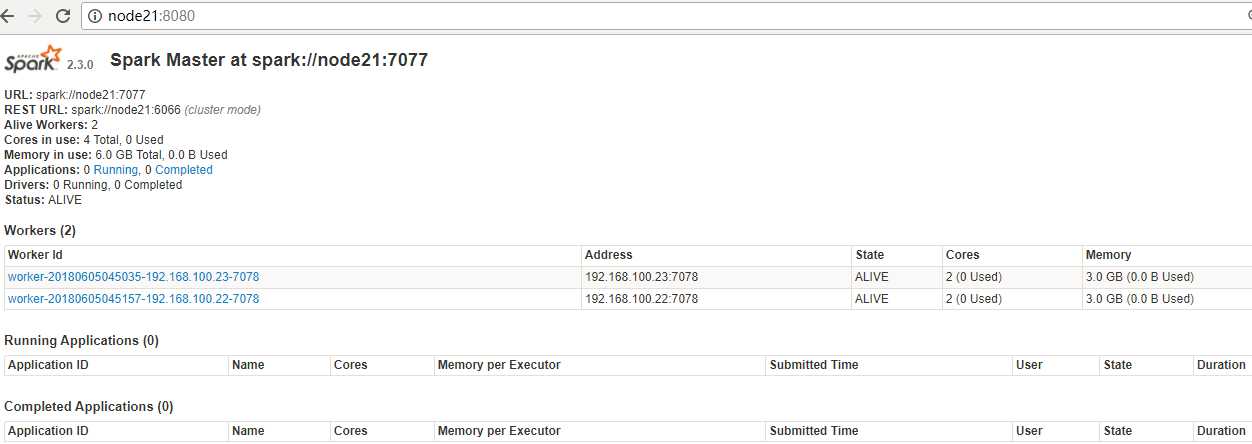
sbin/start-master.sh
sbin/start-slaves.sh
或者
sbin/start-all.sh

[admin@node21 spark-2.3.0]$ spark-shell 2018-06-05 05:36:37 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://node21:4040 Spark context available as ‘sc‘ (master = local[*], app id = local-1528191467883). Spark session available as ‘spark‘. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ ‘_/ /___/ .__/\_,_/_/ /_/\_\ version 2.3.0 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171) Type in expressions to have them evaluated. Type :help for more information. scala> sc.textFile("/opt/module/datas/wc.input") res0: org.apache.spark.rdd.RDD[String] = /opt/module/datas/wc.input MapPartitionsRDD[1] at textFile at <console>:25 scala> res0.collect res1: Array[String] = Array(hadoop habse hive, spark flink storm, sqoop spark hadoop, flume kafka) scala> sc.stop() scala> :quit
或是运行官方的例子
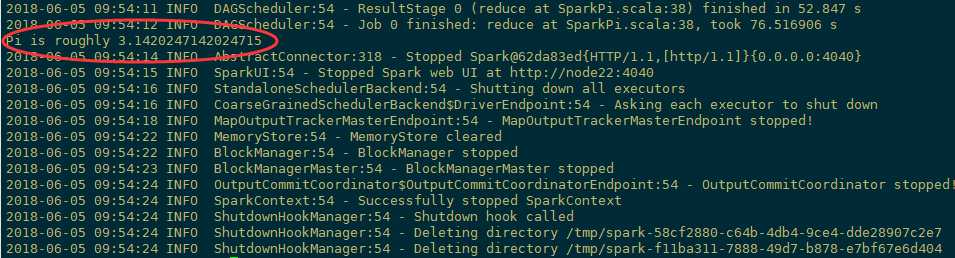
[admin@node21 spark-2.3.0]$ spark-submit --master spark://node21:7077
--class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.11-2.3.0.jar 100
配置HADOOP_CONF_DIR配置文件的路径
HADOOP_CONF_DIR=/opt/module/hadoop-2.7.6/etc/hadoop
确保HADOOP_CONF_DIR或YARN_CONF_DIR指向包含Hadoop集群(客户端)配置文件的目录。这些配置用于写入HDFS并连接到YARN ResourceManager。该目录中包含的配置将被分发到YARN集群,以便应用程序使用的所有容器使用相同的配置。如果配置引用不是由YARN管理的Java系统属性或环境变量,还应该在Spark应用程序的配置(驱动程序,执行程序和以客户端模式运行时的AM)中对其进行设置。
有两种部署模式可用于在YARN上启动Spark应用程序。在cluster模式中,Spark驱动程序在由群集上的YARN管理的应用程序主进程内运行,客户端可以在启动应用程序后离开。在client模式下,驱动程序在客户端进程中运行,而应用程序主服务器仅用于从YARN请求资源。
与Spark支持的其他集群管理器不同,该--master 参数中指定了主设备的地址,在YARN模式下,ResourceManager的地址从Hadoop配置中获取。因此,--master参数是yarn。
以cluster模式启动Spark应用程序:
$ ./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] <app jar> [app options]
例如:
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 4g --executor-memory 2g --executor-cores 1 --queue thequeue examples/jars/spark-examples*.jar 10
以上启动了一个启动默认应用程序主控的YARN客户端程序。然后SparkPi将作为Application Master的子线程运行。客户端将定期轮询应用程序主文件以获取状态更新并将其显示在控制台中。一旦你的应用程序运行完毕,客户端将退出。有关如何查看驱动程序和执行程序日志的信息,请参阅下面的“调试应用程序”部分。
要在client模式下启动Spark应用程序,请执行相同的操作,但替换cluster为client。以下显示如何spark-shell在client模式下运行:
$ ./bin/spark-shell --master yarn --deploy-mode client
添加其他JAR
在cluster模式下,驱动程序运行在与客户端不同的机器上,因此SparkContext.addJar无法使用客户端本地文件开箱即用。要使客户端上的文件可用SparkContext.addJar,请使用--jars启动命令中的选项将它们包括在内。
$ ./bin/spark-submit --class my.main.Class --master yarn --deploy-mode cluster --jars my-other-jar.jar,my-other-other-jar.jar my-main-jar.jar app_arg1 app_arg2
2.4 spark on yarn 的支持两种模式:
1) yarn-cluster:适用于生产环境;
2) yarn-client:适用于交互、调试,希望立即看到app的输出
yarn-cluster和yarn-client的区别在于yarn appMaster,每个yarn app实例有一个appMaster进程,是为app启动的第一个container;负责从ResourceManager请求资源,获取到资源后,告诉NodeManager为其启动container。yarn-cluster和yarn-client模式内部实现还是有很大的区别。如果你需要用于生产环境,那么请选择yarn-cluster;而如果你仅仅是Debug程序,可以选择yarn-client。
./spark-shell --master spark://node21:7077 --name myapp1 --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=hdfs://node21:8020/spark/test
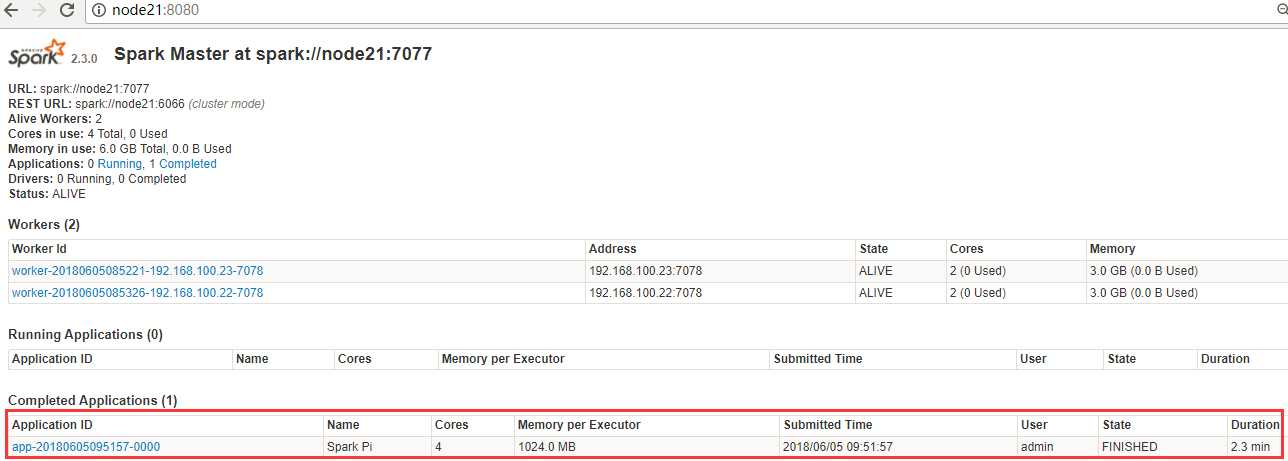
停止程序,在Web Ui中Completed Applications对应的ApplicationID中能查看history。
在客户端节点,进入../spark-2.3.0/conf/ spark-defaults.conf最后加入:
//开启记录事件日志的功能 spark.eventLog.enabled true //设置事件日志存储的目录 spark.eventLog.dir hdfs://node21:8020/spark/test //设置HistoryServer加载事件日志的位置 spark.history.fs.logDirectory hdfs://node21:8020/spark/test //日志优化选项,压缩日志 spark.eventLog.compress true
启动HistoryServer:
./start-history-server.sh
访问HistoryServer:node24:18080,之后所有提交的应用程序运行状况都会被记录。
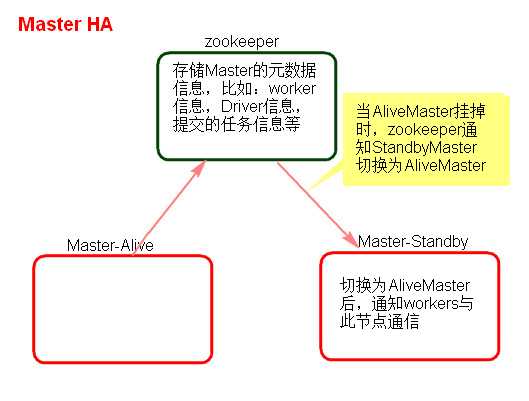
Standalone集群只有一个Master,如果Master挂了就无法提交应用程序,需要给Master进行高可用配置,Master的高可用可以使用fileSystem(文件系统)和zookeeper(分布式协调服务)。
fileSystem只有存储功能,可以存储Master的元数据信息,用fileSystem搭建的Master高可用,在Master失败时,需要我们手动启动另外的备用Master,这种方式不推荐使用。
zookeeper有选举和存储功能,可以存储Master的元素据信息,使用zookeeper搭建的Master高可用,当Master挂掉时,备用的Master会自动切换,推荐使用这种方式搭建Master的HA。
1) 在Spark Master节点上配置主Master,配置spark-env.sh
export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node21:2181,node22:2181,node23:2181 -Dspark.deploy.zookeeper.dir=/sparkmaster0821"
2) 发送到其他worker节点上
scp spark-env.sh 到node22,node23
3) 找一台节点(非主Master节点)配置备用 Master,修改spark-env.sh配置节点上的MasterIP
SPARK_MASTER_IP=node22
4) 启动集群之前启动zookeeper集群:
5) 启动spark Standalone集群,启动备用Master
6) 打开主Master和备用Master WebUI页面,观察状态。
注意点:
测试验证:
提交SparkPi程序,kill主Master观察现象。
./spark-submit --master spark://node21:7077,node22:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.0.jar 10000
[admin@node21 spark-2.3.0]$ spark-shell 2018-06-05 06:15:02 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN".
这种警告是由于glibc库版本不一致造成的。
第一种办法直接在log4j日志中去除告警信息。在hadoop-2.7.6/etc/hadoop/log4j.properties文件中添加
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
第二种办法在hadoop-env.sh中 增加HADOOP_OPTS:
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
标签:master contain webui use order 解压 分布 you over
原文地址:https://www.cnblogs.com/frankdeng/p/9092512.html