标签:rbo member keras red loss += pes set inpu
代码:
# -*- coding: utf-8 -*-
import random
import gym
import numpy as np
from collections import deque
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.utils.vis_utils import plot_model
EPISODES = 1000
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.95 # discount rate
#self.epsilon = 1.0 # exploration rate
self.epsilon = 0.4 # exploration rate
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.learning_rate = 0.001
self.model = self._build_model()
#可视化MLP结构
plot_model(self.model, to_file=‘dqn-cartpole-v0-mlp.png‘, show_shapes=False)
def _build_model(self):
# Neural Net for Deep-Q learning Model
model = Sequential()
model.add(Dense(24, input_dim=self.state_size, activation=‘relu‘))
model.add(Dense(24, activation=‘relu‘))
model.add(Dense(self.action_size, activation=‘linear‘))
model.compile(loss=‘mse‘,
optimizer=Adam(lr=self.learning_rate))
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
act_values = self.model.predict(state)
#print("act_values:")
#print(act_values)
return np.argmax(act_values[0]) # returns action
def replay(self, batch_size):
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = (reward + self.gamma *
np.amax(self.model.predict(next_state)[0]))
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
#if self.epsilon > self.epsilon_min:
# self.epsilon *= self.epsilon_decay
def load(self, name):
self.model.load_weights(name)
def save(self, name):
self.model.save_weights(name)
if __name__ == "__main__":
env = gym.make(‘CartPole-v0‘)
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
#print(state_size)
#print(action_size)
agent = DQNAgent(state_size, action_size)
done = False
batch_size = 32
avg=0
for e in range(EPISODES):
state = env.reset()
state = np.reshape(state, [1, state_size])
for time in range(500):
env.render()
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
reward = reward if not done else -10
next_state = np.reshape(next_state, [1, state_size])
agent.remember(state, action, reward, next_state, done)
state = next_state
if done:
print("episode: {}/{}, score: {}, e: {:.2}"
.format(e, EPISODES, time, agent.epsilon))
avg+=time
break
if len(agent.memory) > batch_size:
agent.replay(batch_size)
print("Avg score:{}".format(avg/1000))
基本思路:
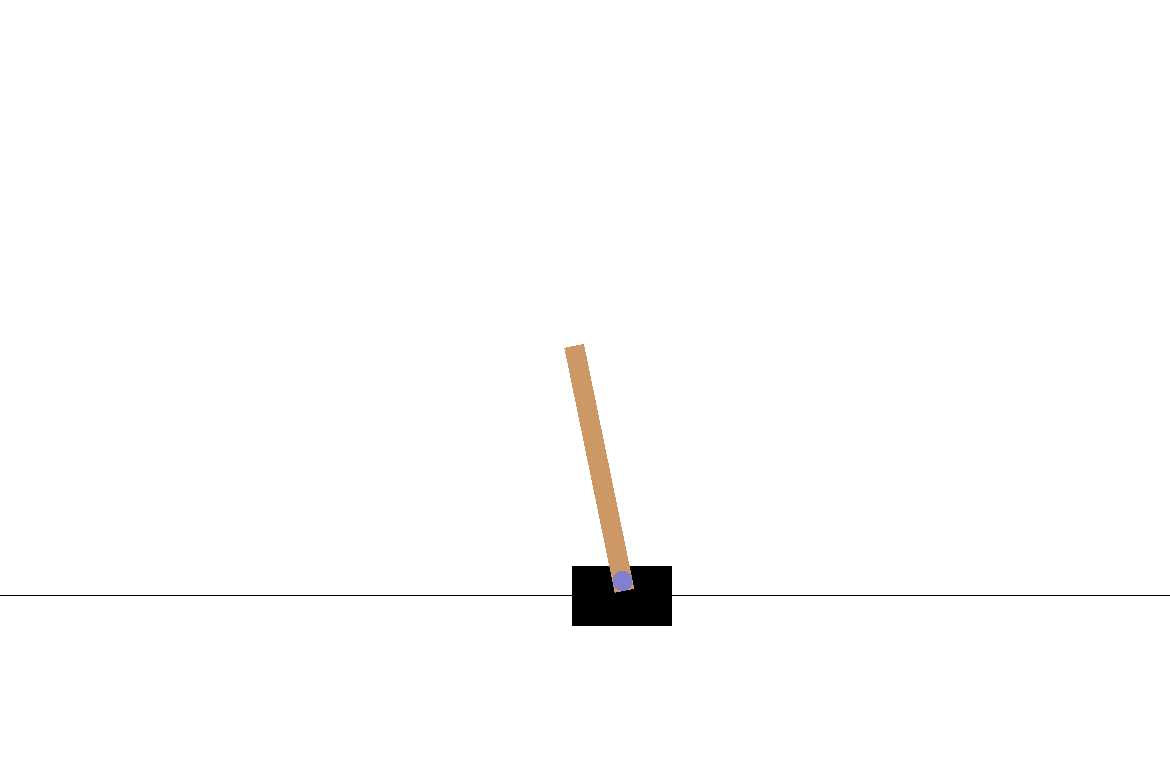
让他自己训练玩这个游戏(每次应该左右移动的距离),基本思路就是:
本质上就是使用MLP训练(动作,得分)
这个得分是坚持时间的长短,如果时间长得分就高。
但是我感觉这个gym自己做了很多事情,比如度量奖励分数,action描述等。待进一步挖掘!
DQN 处理 CartPole 问题——使用强化学习,本质上是训练MLP,预测每一个动作的得分
标签:rbo member keras red loss += pes set inpu
原文地址:https://www.cnblogs.com/bonelee/p/9146540.html