标签:服务端 ip访问 从库 http 命中率 根据 问题 就是 压力
1. 介绍
redis集群分为服务端集群(Cluster)和客户端分片(Sharding)
服务端集群:redis3.0以上版本实现,使用哈希槽,计算key的CRC16结果再模16834。此处暂不介绍
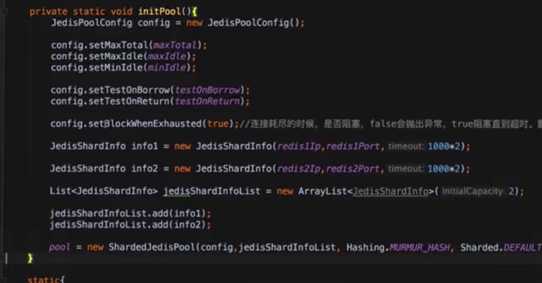
客户端分片:3.0以下使用,采用Key的一致性hash算法来区分key存储在哪个Redis实例上。每个Redis实例彼此独立,使用ShardedJedisPool
2. Sharding存在两个问题
3. 一致性hash算法(Consistent hashing)
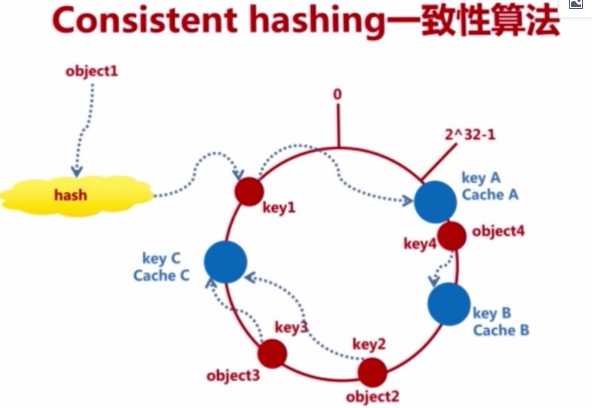
1. 单点故障问题解决:
使用Redis主从复制的功能,两台物理主机上分别都运行有Redis-Server,其中一个Redis-Server是另一个的从库,采用双机热备技术,客户端通过虚拟IP访问主库的物理IP,当主库宕机时,切换到从库的物理IP。只是事后修复主库时,应该将之前的从库改为主库(使用命令slaveof no one),主库变为其从库(使用命令slaveof IP PORT),这样才能保证修复期间新增数据的一致性。
2. 通过pre-sharding进行Redis在线扩容。
解决动态扩容和数据分区的问题,实际就是在同一台机器上部署多个Redis实例的方式,当容量不够时将多个实例拆分到不同的机器上,这样实际就达到了扩容的效果。Pre-Sharding方法是将每一个台物理机上,运行多个不同端口的Redis实例,假如有三个物理机,每个物理机运行三个Redis实例,那么我们的分片列表中实际有9个Redis实例,当我们需要扩容时,增加一台物理机来代替9个中的一个redis,有人说,这样不还是9个么,是的,但是以前服务器上面有三个redis,压力很大的,这样做,相当于单独分离出来并且将数据一起copy给新的服务器。值得注意的是,还需要修改客户端被代替的redis的IP和端口为现在新的服务器,只要顺序不变,不会影响一致性哈希分片。
拆分过程如下:
以上拆分流程是Redis作者提出的一个平滑迁移的过程,不过该拆分方法还是很依赖Redis本身的复制功能的,如果主库快照数据文件过大,这个复制的过程也会很久,同时会给主库带来压力。所以做这个拆分的过程最好选择为业务访问低峰时段进行。
标签:服务端 ip访问 从库 http 命中率 根据 问题 就是 压力
原文地址:https://www.cnblogs.com/wslook/p/9152542.html