标签:apt 因此 image 配置 自适应 lstm 关键点 单位 9.png
基于因子分解的隐层变量学习,应用于短语句语种识别模型的自适应
LFVs(Language Feature Vectors,语种特征向量)[11],与BSVs(Bottleneck Speaker Vectors)类似,即瓶颈特征
3.1. 神经元调制
由于说话人特性的变化反映在语音信号中,因此将表示说话人适应声学特性的特征拼接到特征中。如VTLN或fMLLR,是直接对声学特征进行操作的自适应方法。可以训练一个说话人自适应系统以基于说话人属性直接对输入特征进行转换,这样效果与基于i-Vector的自适应类似[8]。但是与说话人变化特性相比,语言特性是更高阶的概念。在某些方面基于声学。例如,具有相同音素的多种语言,可以在某种程度上可以观察到语言特定属性。但是,声学特征变换适应性方法无法考虑到音位配列学或者不同声学单元集的知识。在这里,在更深层次的DNN处添加特征可能会改善自适应性。[17]基于Meta-PI网络进行了尝试。关键点是使用Meta-PI连接,它允许通过将隐层单元乘以系数来调制神经元的输出。应用于语种自适应,我们用LFV来对隐藏层的输出进行调制。基于语种特征的调制,LSTM单元的输出被衰减或增强。这迫使隐藏层中的单元基于语种特征来学习或适应。调制可以被认为与Dropout有关[18],其中网络连接以随机概率被丢弃。在结果部分中,我们将此方法称为"LFV调制"。
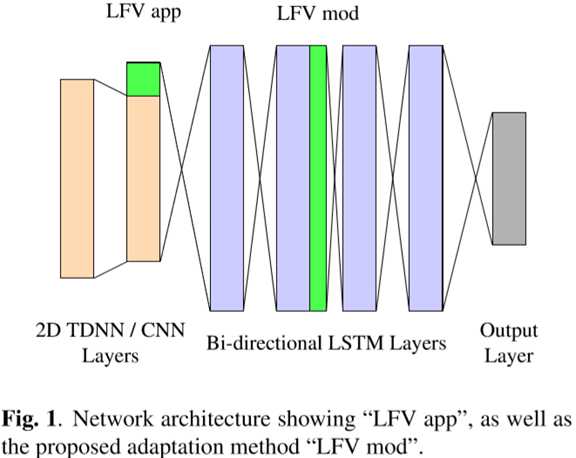
我们使用了如图1所示的网络配置。基??本架构受百度Deepspeech 2的启发。它将两个TDNN/CNN层与4个双向LSTM层组合在一起。输出层是一个前馈层,它将最后一个LSTM层的输出映射到目标。将每层LSTM单元维数设定为LFV维数的数倍。这样就可以构建包含相同单位数量的LSTM单元的隐藏层组。然后用LFV的某一维对每组的输出进行调制。该图显示了两种配置,"LFV 拼接"和"LFV 调制",但一次只应用一种方法。在初步实验中,我们得出在第二个LSTM层的输出处进行调制可以获得最佳性能。
标签:apt 因此 image 配置 自适应 lstm 关键点 单位 9.png
原文地址:https://www.cnblogs.com/JarvanWang/p/9152674.html
{kind=link}