标签:重复数据删除 笔记本 分享图片 acl 提交 特殊 str difficult 所有权
为寻找一个能够激励与这些特性相反的系统(通用设备、非浪费的工作及低功耗),开发者Bram Cohen提出了计算机存储所有权验证作为工作量证明的替代方案。
他提出的“空间证明(proof of space)”,认为这个建议是今天强化比特币的理念的自然迭代。
这一概念需要使用的唯一其他资源就是存储。所以,结果就证实了空间证明在理论上的可能性,利用空间证明你便能够分配存储容量去来做这些事情。在空间证明系统下,矿工将一定量未使用的磁盘空间分配给网络,成功挖掘区块的概率与分配的空间量除以网络总容量成比例。
比特币系统中使用的工作量证明函正是SHA256。
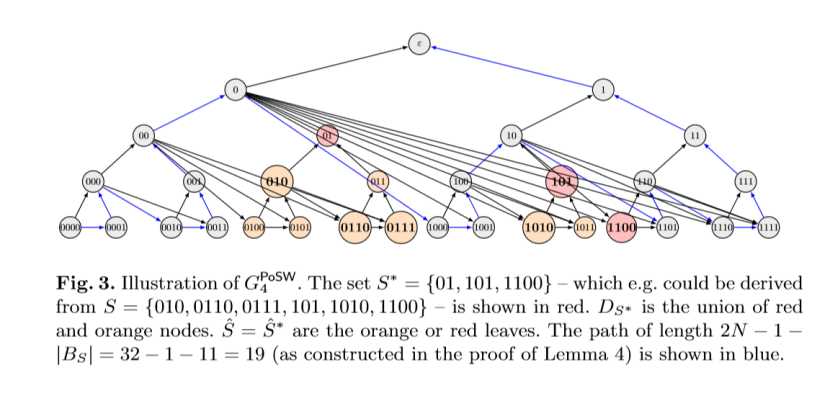
比特币的区块由区块头及该区块所包含的交易列表组成。区块头的大小为80字节,由4字节的版本号、32字节的上一个区块的散列值、32字节的Merkle Root Hash、4字节的时间缀(当前时间)、4字节的当前难度值、4字节的随机数组成。区块包含的交易列表则附加在区块头后面,其中的第一笔交易是coinbase交易,这是一笔为了让矿工获得奖励及手续费的特殊交易。
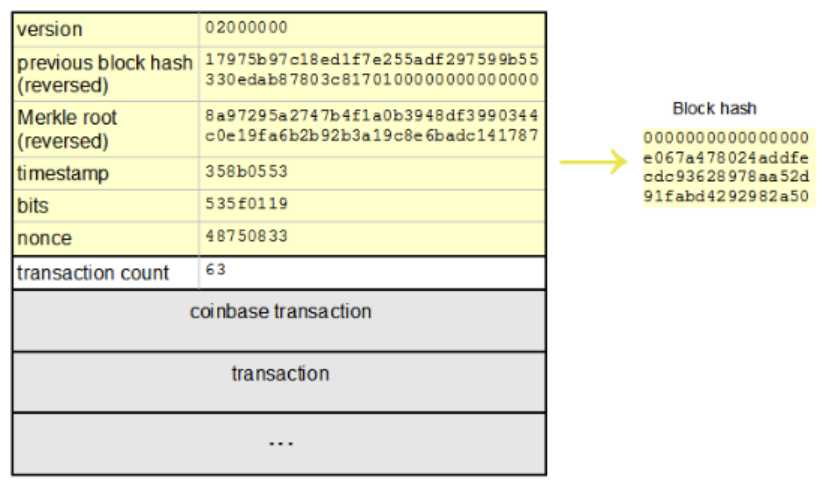
拥有80字节固定长度的区块头,就是用于比特币工作量证明的输入字符串。因此,为了使区块头能体现区块所包含的所有交易,在区块的构造过程中,需要将该区块要包含的交易列表,通过Merkle Tree算法生成Merkle Root Hash,并以此作为交易列表的摘要存到区块头中。其中Merkle Tree的算法图解如下:
- 这个公式可以总结为如下形式:
- 新难度值 = 旧难度值 * ( 过去2016个区块花费时长 / 20160 分钟 )
- 工作量证明需要有一个目标值。比特币工作量证明的目标值(Target)的计算公式如下:
- 目标值 = 最大目标值 / 难度值
- 其中最大目标值为一个恒定值:
- 0x00000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
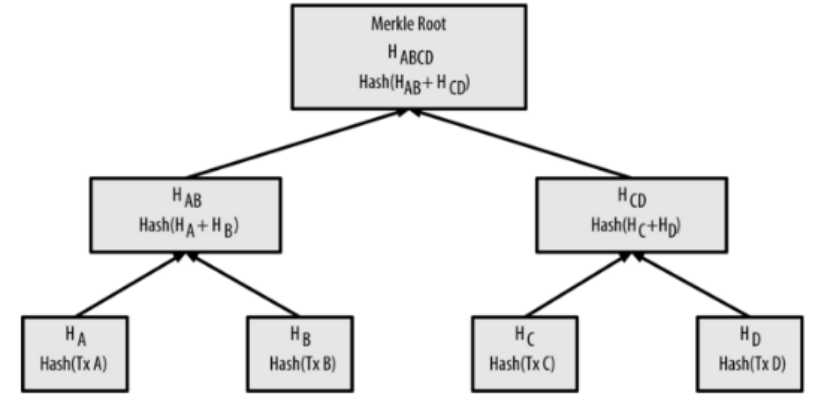
我们可以把比特币矿工解这道工作量证明迷题的步骤大致归纳如下:
- 1、生成Coinbase交易,并与其他所有准备打包进区块的交易组成交易列表,通过Merkle Tree算法生成Merkle Root Hash
- 2、把Merkle Root Hash及其他相关字段组装成区块头,将区块头的80字节数据(Block Header)作为工作量证明的输入
- 3、不停的变更区块头中的随机数即nonce的数值,并对每次变更后的的区块头做双重SHA256运算(即SHA256(SHA256(Block_Header))),将结果值与当前网络的目标值做对比,如果小于目标值,则解题成功,工作量证明完成。
该过程可以用下图表示:
符号O(x)指RO对于输入x的输出, L代表O(x)的长度。(L是安全参数n的函数)
- 1.RO一开始维护一张空表,表有两列,一列是输入,一列是输出
- 2.如果访问者第一次的输入为x, 则RO均匀随机从中选一个值O(x), 把x记录在表里。
- 3.对于第二个以及之后的访问y,如果y没有在输入这一列出现,则RO均匀随机从选出O(y), 反之,即y出现过,则把输出这一列中,y对应的O(y)再次输出。
- 这也就是“真正均匀随机”和“对重复值输出相同”的意思。
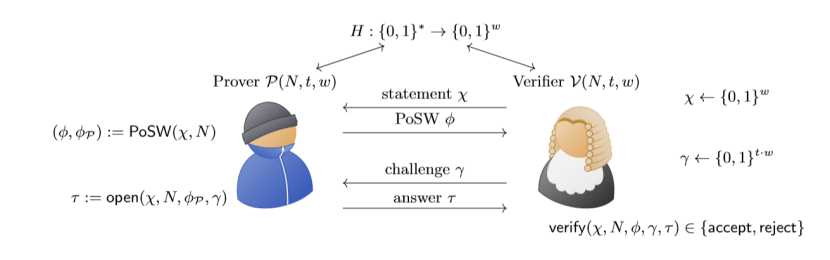
- N:时间参数 ,即 PoSW(χ,N) ,在收到w位的x 声明后N时间以及过去,计算得到φ。
- t是一个统计安全参数,较大的t的稳健性越好
- w是哈希函数的位数
- 公用输入P 和 V 获得相同的输入两个统计安全参数w, t 和时间参数N 。所有各方都可以访问随机 oracle H : {0,1}? → {0,1}w.
- 语句V 随机抽样χ ← {0,1}w 并将其发送到 P.
- 计算 PoSW P 计算 (理想情况下, 使N查询 H 顺序) 一个证明 (φ, φP): =PoSWH (χ, N)。P 将φ发送到 V 和本地存储φP.
- 打开挑战V 采样随机挑战γ ← {0,1}t·w 并将其发送到 P
- 打开P 计算τ : =打开H (χ、N、φP、γ) 并将其发送到 v.
- 验证V 计算和输出验证H (χ, N, φ, γ, τ) ∈ {接受,拒绝}.
- 我们需要完美正确性: 如果 V 与一个诚实的 P 交互, 那么它将输出接受以概率1。稳健属性要求任何潜在的恶意证明人 P , 如果以良好的概率进行 V 接受, 则必须按顺序查询H "几乎" N次数。即使在每一轮 Pe 都可以并行地在许多输入中查询 H, 而诚实 P 只需要使一个小 (在我们的构造1中, 在 [MMV13] 2 中) 每回合查询数.
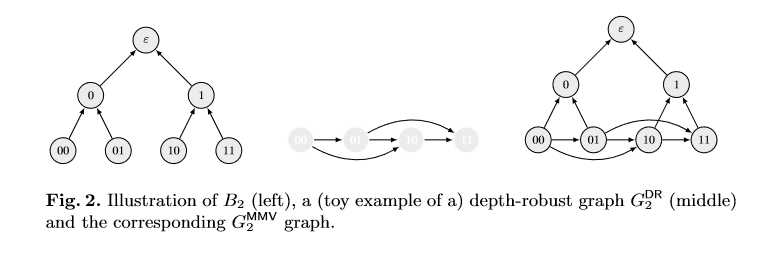
- 主要用于比特币设计,结合空间证明完成工作证明,作为一个更加环保更加经济的工作证明方式。
- 优点 提出了一个更简单,更有效,并取得更好的具体界限的顺序工作证明。最重要的是,所需的空间只要logn(使用多一些点的内存就会具有更好的健壮性)
- 改进点:The PoSW,open and verify algorithms
论文完成了一个连续工作的证明,它比[MMV13]中的原始结构更简单并且参数更好。 并对[MMV13]论文中提出的三个问题有了解答。
1、规划求解的空间复杂性。在我们构建时间戳和时间锁谜题的时候, 求解器保留 n 个顶点图的哈希标签。是否有其他使用 o (N) 存储的解决方案?或者有任何内在的原因, ? (N) 存储是必要的?
2、深度稳健图的必要性。 我们构造的效率和安全性与深度文件图结构的参数密切相关:较低度的图给出了更多有效的解,而具有较高鲁棒性的图(在一些顶点之后剩余的最长路径的长度的下界是 移除)给我们带来较小对抗优势的谜题。 一个有趣的开放问题是逆向是否也持有:具有更好参数的时间锁定谜题还意味着存在具有更好参数的深度 - 稳健图表?
存储证明(POS)方案类似“数据持有性验证”(PDP)[2]和“可恢复性证明”(PoR)[3,4]方案。它允许一个将数据外包给服务器(既证明人P)的用户(既验证者V)可以反复检查服务器是否依然存储数据D。用户可以用比下载数据还高效的方式来验证他外包给服务器的数据的完整性。服务器通过对一组随机数据块进行采样和提交小量数据来生成拥有的概率证明作为给用户的响应协议。
PDP和PoR方案只保证了证明人在响应的时候拥有某些数据。在Filecoin中,我们需要更强大的保障能阻止作恶矿工利用不提供存储却获得奖励的三种类型攻击:女巫攻击(Sybil attack)、外包攻击(outsourcing attacks)、代攻击(generation attacks)。
女巫攻击:作恶矿工可能通过创建多个女巫身份假装物理存储很多副本(从中获取奖励),但实际上只存储一次。
外包攻击:依赖于可以快速从其他存储提供商获取数据,作恶矿工可能承诺能存储比他们实际物理存储容量更大的数据。
代攻击:作恶矿工可能宣称要存储大量的数据,相反的他们使用小程序有效地生成请求。如果这个小程序小于所宣称要存储的数据,则作恶矿工在Filecoin获取区块奖励的可能性增加了,因为这是和矿工当前使用量成正比的。
PoRep方案使得有效的证明人P能说服验证者V,数据D的一个P专用的独立物理副本R已被存储。PoRep协议其特征是多项式时间算法的元组: (Setup, Prove, Verify)
1、PoRep.Setup(1λ, D) → R, SP , SV , 其中SP和SV是P和V的特点方案的设置变量,λ是一个安全参数。PoRep.Setup用来生成副本R,并且给予P和V必要的信息来运行PoRep.Prove 和 PoRep.Verify。一些方案可能要求证明人或者是有互动的第三方去运算PoRep.Setup。
2、PoRep.Prove(SP , R, c) → πc,其中c是验证人V发出的随机验证, πc是证明人产生的可以访问数据D的特定副本R的证明。PoRep.Prove由P(证明人)为V(验证者)运行生成πc。
3、PoRep.Verify(Sv , c, πc) → {0, 1},用来检测证明是否是正确。PoRep.Verify由V运行和说服V相信P已经存储了R。
存储证明方案允许用户请求检查存储提供商当时是否已经存储了外包数据。我们如何使用PoS方案来证明数据在一段时间内都已经被存储了?这个问题的一个自然的答案是要求用户重复(例如每分钟)对存储提供商发送请求。然而每次交互所需要的通信复杂度会成为类似Filecoin这样的系统的瓶颈,因为存储提供商被要求提交他们的证明到区块链网络。
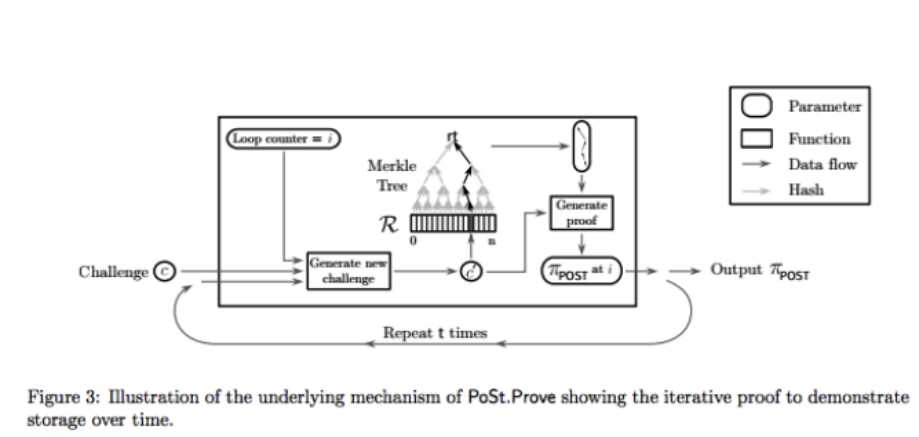
(时空证明)Post方案使得有效的证明人P能够说服一个验证者V相信P在一段时间内已经存储了一些数据D。PoSt其特征是多项式时间算法的元组: (Setup, Prove, Verify)
1、PoSt.Setup(1λ,D)->Sp,Sv,其中SP和SV是P和V的特点方案的设置变量,λ是一个安全参数。PoSt.Setup用来给予P和V必要的信息来运行PoSt.Prove 和 PoSt.Prove。一些方案可能要求证明人或者是有互动的第三方去运算PoSt.Setup。
2、PoSt.Prove(Sp , D, c, t) → πc,其中c是验证人V发出的随机验证, πc是证明人在一段时间内可以访问数据D的的证明。PoSt.Prove由P(证明人)为V(验证者)运行生成πc。
3、PoSt.Verify(Sv , c, t, πc) → {0, 1},用来检测证明是否是正确。PoSt.Verify由V运行和说服V相信P在一段时间内已经存储了R。
Filecoin是一个去中心化存储网络,它让云存储变成一个算法市场。随着云盘服务商的纷纷停摆,我们看到,中心化的云存储是多么的不靠谱。去中心化的存储是一个非常大的市场,也是刚需,如果能够很好的解决带宽的问题,它的价值将是巨大的,但同时这是一个新项目,还有很长的路要走。
标签:重复数据删除 笔记本 分享图片 acl 提交 特殊 str difficult 所有权
原文地址:https://www.cnblogs.com/lidong20179210/p/9153067.html