标签:none max 精确 script tag correct 样本 distrib 工作流程
github上的tensorboard项目:https://github.com/tensorflow/tensorboard/blob/master/README.md
目录
一、基本介绍
tensorboard:一个网页应用,可以方便观察TensorFlow的运行过程和网络结构等(过程可视化)
工作流程
Ops是指tf.matmul、tf.nn.relu等,也就是在TensorFlow图中的操作
执行过程中的张量包含序列化的原始缓存,它会被写到磁盘并传给TensorBoard。然后需要执行summary op,来恢复这些结果,实现对TensorBoard中的数据可视化
summary ops包括:tf.summary.scalar, tf.summary.image, tf.summary.audio, tf.summary.text, tf.summary.histogram
当进行summary op时,也可以给一个tag。这个tag是该op记录的数据的名字,作为一种标识
summary.FileWriters从TensorFlow把summary 数据写到磁盘中特定的目录,也就是logDir。数据是以追加的方式写入,文件名中有"tfevents"。TensorBoard从一个完整的目录中读取数据,并组织成一次TensorFlow执行过程
说明
如果你用superviosr.py来跑模型,当TensorFlow崩溃,superviso将从一个checkpoint重新开始跑。因为重新开始,就会产生一个新的event 文件,然后TensorBoard就可以把这些不同的event文件组织成一个连续的历史
比如对某个超参数做了调整,想要比较该超参数不同值的执行效果。希望可视化的时候,可以同时展示这两个效果
实现方法:给TensorBoard传一个参数logdir,它将递归查找,每次遇到一个子目录,就会把它当成一个新的执行。
例:下面有run1和run2两个结果
|
/some/path/mnist_experiments/ /some/path/mnist_experiments/run1/ /some/path/mnist_experiments/run1/events.out.tfevents.1456525581.name /some/path/mnist_experiments/run1/events.out.tfevents.1456525585.name /some/path/mnist_experiments/run2/ /some/path/mnist_experiments/run2/events.out.tfevents.1456525385.name
/tensorboard --logdir /some/path/mnist_experiments |
二、基本操作
定一个writer(log位置),用来写summary结果:train_writer = tf.summary.FileWriter("./resource/logdir", sess.graph)启动tensorboard
根据提示,访问网页即可结果
三、几种图
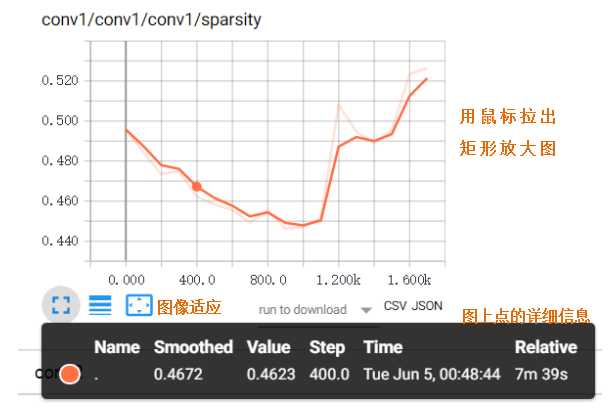
将标量值随时间时间变化进行可视化,如losss或学习率
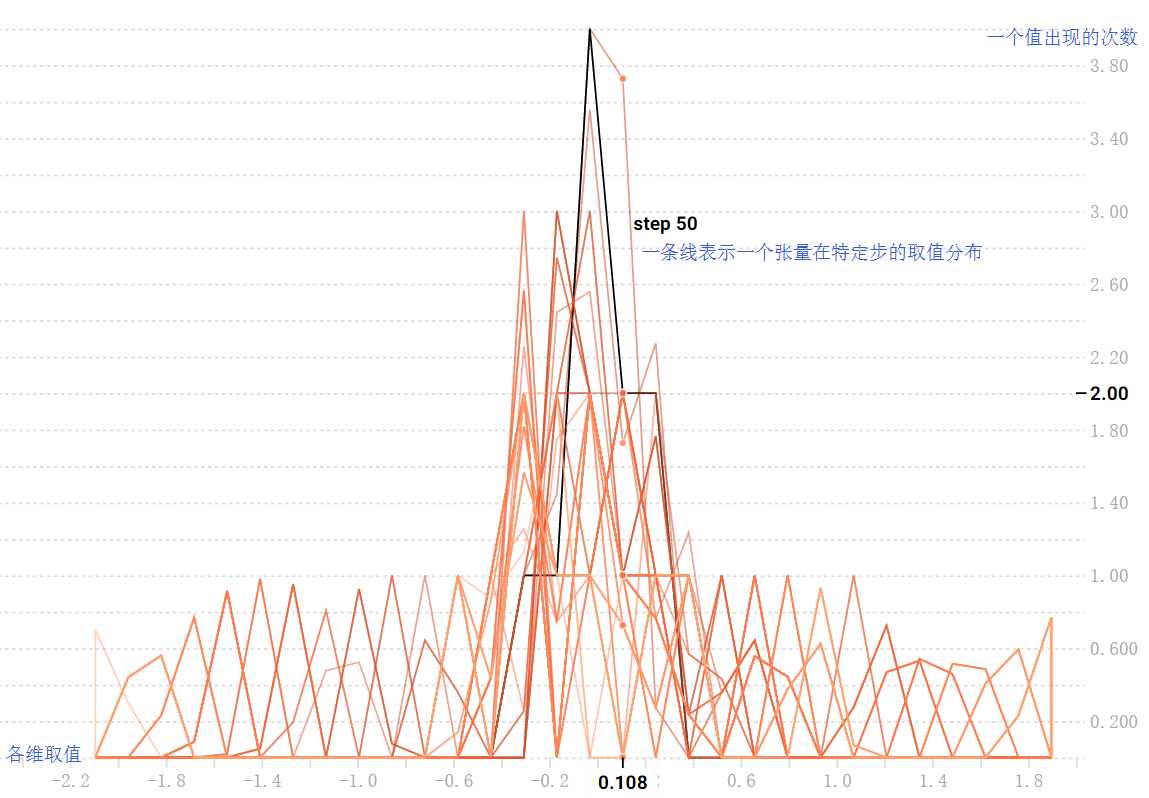
张量随时间变化的分布情况。每个图表是数据的临时切片,每个切片是特定一步的张量的柱状图。越早的时间步结果越靠后
overlay-step offset-step
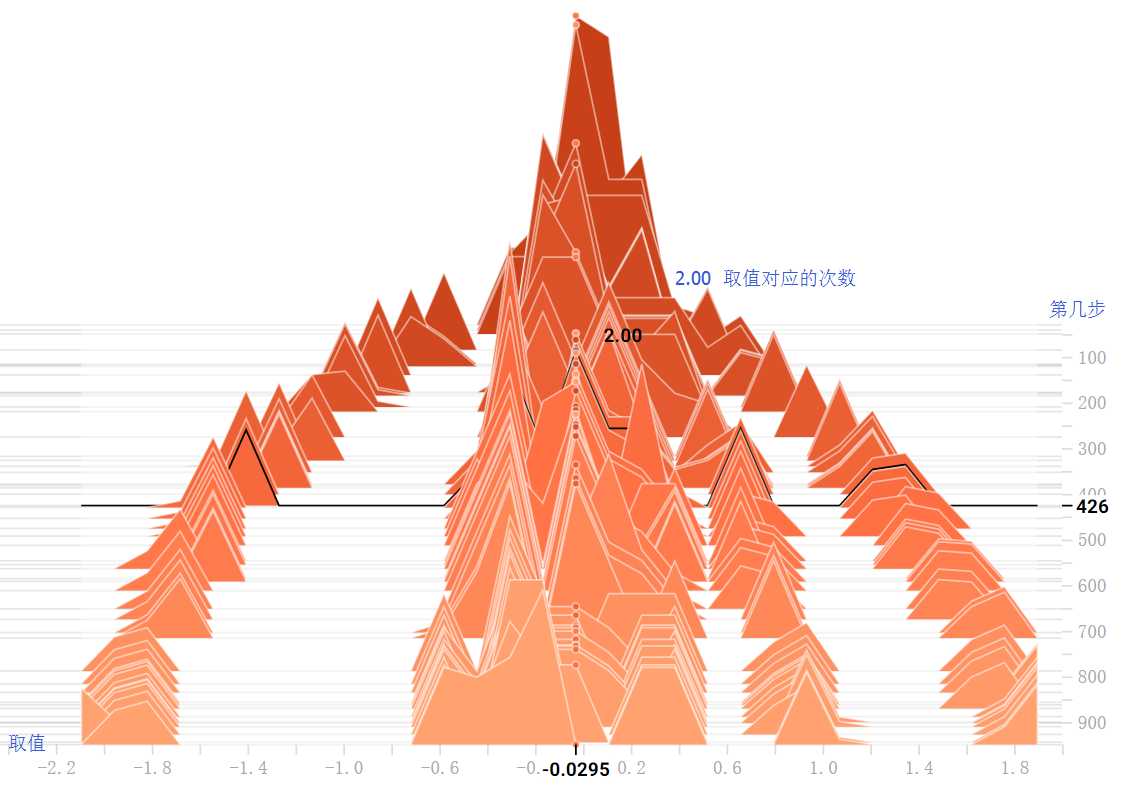
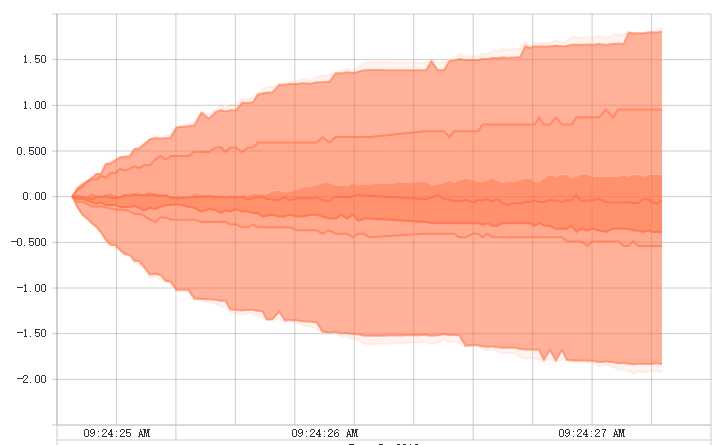
tf.summary.histogram的另一种展示方式。每一行代表一个值随时间步的变化情况。最下面是最小的值,向上值不断增大。每一列代表一个时间步中值的取值范围
展示png图像,每一行对应不同的tag,每一列是一个执行。tf.summary.image("images", tf.reshape(input_images, [100, 28, 28, 1]))

嵌入可播放的音频容器。每行对应不同的tag,每列是一次运行。总是嵌入最新的一次结果
对TensorFlow模型的可视化
展示高维度的数据。projector是从模型的checkpoint文件读取数据,也可以用其他metadata配置,比如词汇表或雪碧图
四、源码

1 def tensorboard(): 2 # None表示此张量的第一个维度可以是任何长度的 3 x = tf.placeholder("float", [None, 784]) 4 y_ = tf.placeholder("float", [None, 10]) # 标签,正确结果 5 6 # 初始化两个参数 7 W = tf.Variable(tf.zeros([784, 10])) 8 b = tf.Variable(tf.zeros([10])) 9 m = [1,2,3,4,5,6] 10 tf.summary.histogram("xx", b) 11 # softmax函数 12 y = tf.nn.softmax(tf.matmul(x, W) + b) # 执行结果 13 14 # 交叉熵,成本函数 15 # tf.reduce_sum 计算张量的所有元素的总和 16 cross_entropy = -tf.reduce_sum(y_ * tf.log(y)) 17 18 # 梯度下降法来优化成本函数 19 # 下行代码往计算图上添加一个新操作,其中包括计算梯度,计算每个参数的步长变化,并且计算出新的参数值 20 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) 21 22 init = tf.initialize_all_variables() 23 mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) 24 25 prediction_train = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) 26 accuracy_train = tf.reduce_mean(tf.cast(prediction_train, "float")) 27 tf.summary.scalar("accuarcy_train", accuracy_train) 28 29 # 显示图像 30 batch_xs, batch_ys = mnist.train.next_batch(100) 31 tf.summary.image(‘images‘, tf.reshape(batch_xs, [100, 28, 28, 1])) 32 33 # 用于tensorboard 34 merged = tf.summary.merge_all() 35 36 with tf.Session() as sess: 37 sess.run(init) 38 train_writer = tf.summary.FileWriter("./resource/mnist_logs", sess.graph) 39 40 # 循环遍历1000次训练模型 41 for i in range(1000): 42 # 每一步迭代加载100个训练样本,然后执行一次train_step,并通过feed_dict将x 和 y张量占位符用训练训练数据替代 43 summary, _ = sess.run([merged, train_step], feed_dict={x: batch_xs, y_: batch_ys}) 44 45 if i % 10 == 0: 46 train_writer.add_summary(summary, i) 47 for index, d in enumerate(m): 48 m[index] -= 0.1 49 batch_xs, batch_ys = mnist.train.next_batch(100) 50 train_writer.close() 51 52 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) 53 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) 54 print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
标签:none max 精确 script tag correct 样本 distrib 工作流程
原文地址:https://www.cnblogs.com/coolqiyu/p/9092807.html
