标签:查看 flag .com 服务 a标签 3.4 取值 模板文件 接下来
一、自动分配(redis)
数据放缓存了,为的是速度快
redis是支持持久化的,如果关机了以后,数据已经会放在文件里了
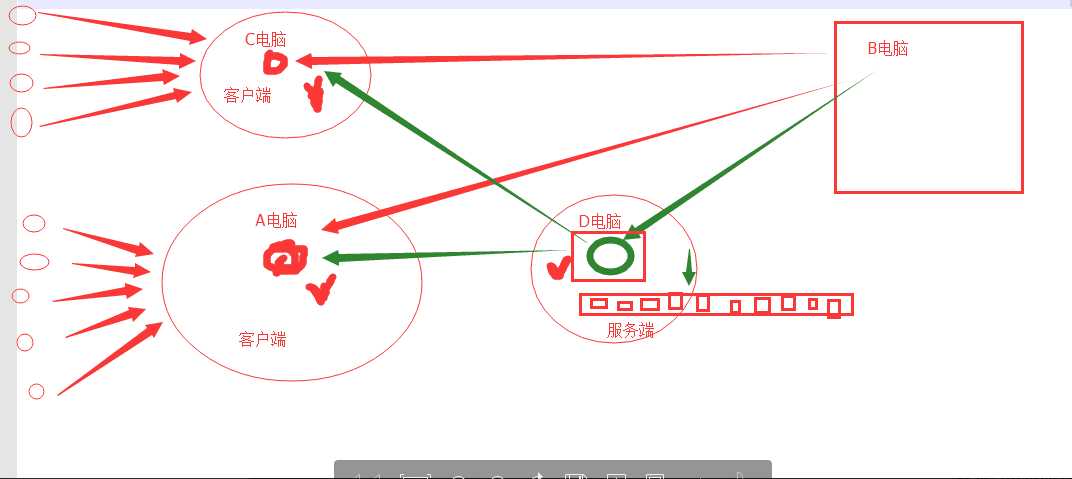
先买上一台电脑:装上redis服务器软件
- 这个服务器有个工网IP:47.93.4.198
- 端口:6379
我们的电脑:装上链接redis的模块
- pip instaill redis

redis:说白了就是一个服务器的一个软件,帮助我们在内存里面存数据
conn.lpush("names":"sss") #往里边放入值
conn.lpush("names":*[地方法规","dfgdf"]) #放多个值 ,从左边添加,相当于insert
conn.rpush("names":*[地方法规","dfgdf"]) #放多个值 ,从后面添加,相当于append
conn.lpop("names") #一个一个从里面取值 ,bytes类型
conn.rpop("names") #从里面取值 ,bytes类型
conn.llen("names") #查看长度
import redis
conn = redis.Redis(host="192.168.20.150",port=6379)
#===========对于字符串用set,get设置,得到值===========
conn.set("k13","v2") #向远程redis中写入了一个键值对
val = conn.get("k13") #获取键值对
print(val)
conn.set("names","ss")
val2 = conn.get("names")
print(val2)
#===========对于列表的操作: lpush操作和lpop操作,(从左边放值,从左边取值)=============
val4 = conn.lpush("names_s",*["海燕","刘伟"])
conn.lpush(‘names_s‘,*[‘把几个‘,‘鲁宁‘]) #‘鲁宁‘,‘把几个‘,"刘伟","海燕",
conn.delete("names_s")
v = conn.llen("names_s")
print(conn.llen("names_s")) #4
for i in range(v):
print(conn.lpop("names_s").decode("utf-8"))
# ==========对于列表的操作: rpush操作和rpop操作,(从右边放值,从右边取值)======
conn.rpush("abcd",[1,2,3])
conn.rpush("abcd",*["a","b","c"]) #[1,2,3],a,b,c #*代表是解包,如果不加*,放进去的就是一个列表
# conn.delete("abcd")
v = conn.llen("abcd")
# print(v) #
for i in range(v):
print(conn.rpop("abcd").decode("utf-8")) #c,b,a,[1,2,3]
在项目中应用
链接redis,吧所有的数据列表放在redis里,吧回滚的也放在redis里面

原来是迭代器一个一个取值,现在我们可以用链接redis,rpop一个一个取值
当出问题回滚的时候(或者没有使用),我们可以用rpush吧它再添加进去,然后在取出来
conn.lindex("said_id_list_origin",0) #查看索引0对应的值
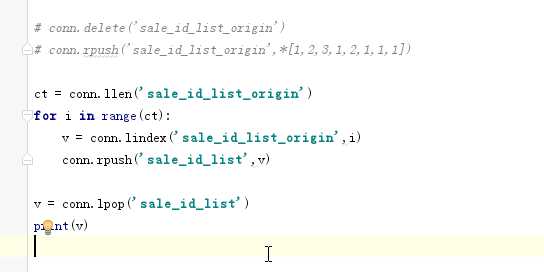
第一次运行,只有数据库有数据
如果数据库中没有取到值,那么直接返回None
接下来一个一个获取,如果取到了None,已经取完,再把备用的列表里面的数据在放回去
分配表里面的数据如果更新的话就需要重置了。
import redis
from crm import models
POOL = redis.ConnectionPool(host=‘47.93.4.198‘, port=6379, password=‘123123‘)
CONN = redis.Redis(connection_pool=POOL)
class AutoSale(object):
@classmethod
def fetch_users(cls):
# [obj(销售顾问id,num),obj(销售顾问id,num),obj(销售顾问id,num),obj(销售顾问id,num),]
sales = models.SaleRank.objects.all().order_by(‘-weight‘)
sale_id_list = []
count = 0
while True:
flag = False
for row in sales:
if count < row.num:
sale_id_list.append(row.user_id)
flag = True
count += 1
if not flag:
break
if sale_id_list:
CONN.rpush(‘sale_id_list‘, *sale_id_list) # 自动pop数据
CONN.rpush(‘sale_id_list_origin‘, *sale_id_list) # 原来的数据
return True
return False
@classmethod
def get_sale_id(cls):
# 查看原来数据是否存在
sale_id_origin_count = CONN.llen(‘sale_id_list_origin‘)
if not sale_id_origin_count:
# 去数据库中获取数据,并赋值给: 原数据,pop数据
status = cls.fetch_users()
if not status:
return None
user_id = CONN.lpop(‘sale_id_list‘)
if user_id:
return user_id
reset = CONN.get(‘sale_id_reset‘)
# 要重置
if reset:
CONN.delete(‘sale_id_list_origin‘)
status = cls.fetch_users()
if not status:
return None
CONN.delete(‘sale_id_reset‘)
return CONN.lpop(‘sale_id_list‘)
else:
ct = CONN.llen(‘sale_id_list_origin‘)
for i in range(ct):
v = CONN.lindex(‘sale_id_list_origin‘, i)
CONN.rpush(‘sale_id_list‘, v)
return CONN.lpop(‘sale_id_list‘)
@classmethod
def reset(cls):
CONN.set(‘sale_id_reset‘,1)
@classmethod
def rollback(cls,nid):
CONN.lpush(‘sale_id_list‘,nid)
总结:
1、什么是redis?
2、set,get对字符串做操作的,
3、lpush,rpush,lpop,rpop对于列表做操作的
lindex:取索引
llen() :长度
4、 delete :删除 :公共的
扩展:
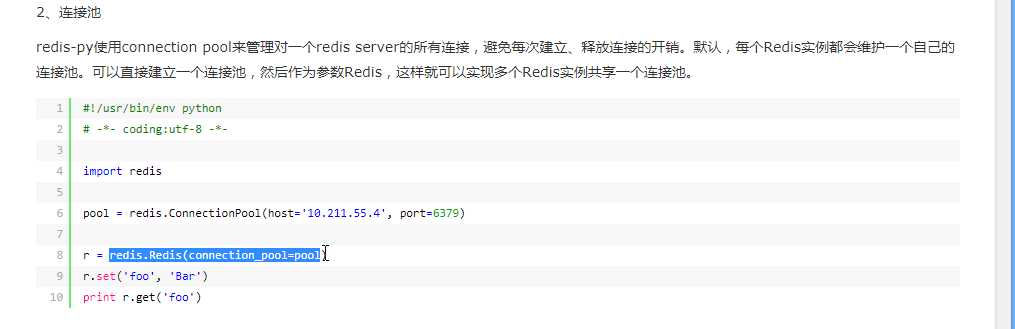
redis和我们的数据库一样,不能每次都链接,redis支持连接池
不推荐

推荐:
二、批量导入
上传excel文件,页面上显示
 上传文件
上传文件
1、拿到文件名和文件大小
file_obj.field_name: 文件名,
file_obj.size :文件大小
2、打开文件读取,以写的方式存起来
3、安装xlrd-1.1.0的两种方式
python setup.py build
pip instail xlrd
4、打开excle文件做操作。拿到每一个单元格的数据,写入数据库
吧第一行排除,可以吧列表转换成字典,录入到数据库
5、作业
自动获取ID
录入客户表
录入分配表
不在创建临时xlsx文件,写在内存里面,
写上一个模板文件,让用户去下载
6、文件,用户下载文件的两种方式
吧文件写在静态文件里面,用a标签去跳转。但是这种当是可能不行
设置响应头(搜索django如何实现文件下载)
三、微信自动绑定
前提:公司里的每一个人都得关注公众号,才可以给推送消息
=================================
1、自动分配、你在什么时候用到了自动分配?
答:市场部或运营部招来的新的客户,单条(批量)录入数据的时候,进行自动分配。
2、那你们是怎么自动分配的呢?
答:基于redis的列表实现的。相当于队列用了。
====================================
标签:查看 flag .com 服务 a标签 3.4 取值 模板文件 接下来
原文地址:https://www.cnblogs.com/jiangshanduojiao/p/9140697.html