标签(空格分隔): 大数据平台构建
- 一:安装及配置Phoenix
- 二:Phoenix的基本操作
- 三:使用Phoenix bulkload数据到HBase
- 四:使用Phoenix从HBase中导出数据到HDFS
Phoenix中文翻译为凤凰, 其最早是Salesforce的一个开源项目,Salesforce背景是一个搞ERP的,ERP软件一个很大的特点就是数据库操作,所以能搞出一个数据库中间件也是很正常的。而后,Phoenix成为Apache基金的顶级项目。
Phoenix具体是什么呢,其本质是用Java写的基于JDBC API操作HBase的开源SQL引擎下载地址:
http://archive.cloudera.com/cloudera-labs/phoenix/parcels/latest/
CLABS_PHOENIX-4.7.0-1.clabs_phoenix1.3.0.p0.000-el7.parcel
CLABS_PHOENIX-4.7.0-1.clabs_phoenix1.3.0.p0.000-el7.parcel.sha1
manifest.json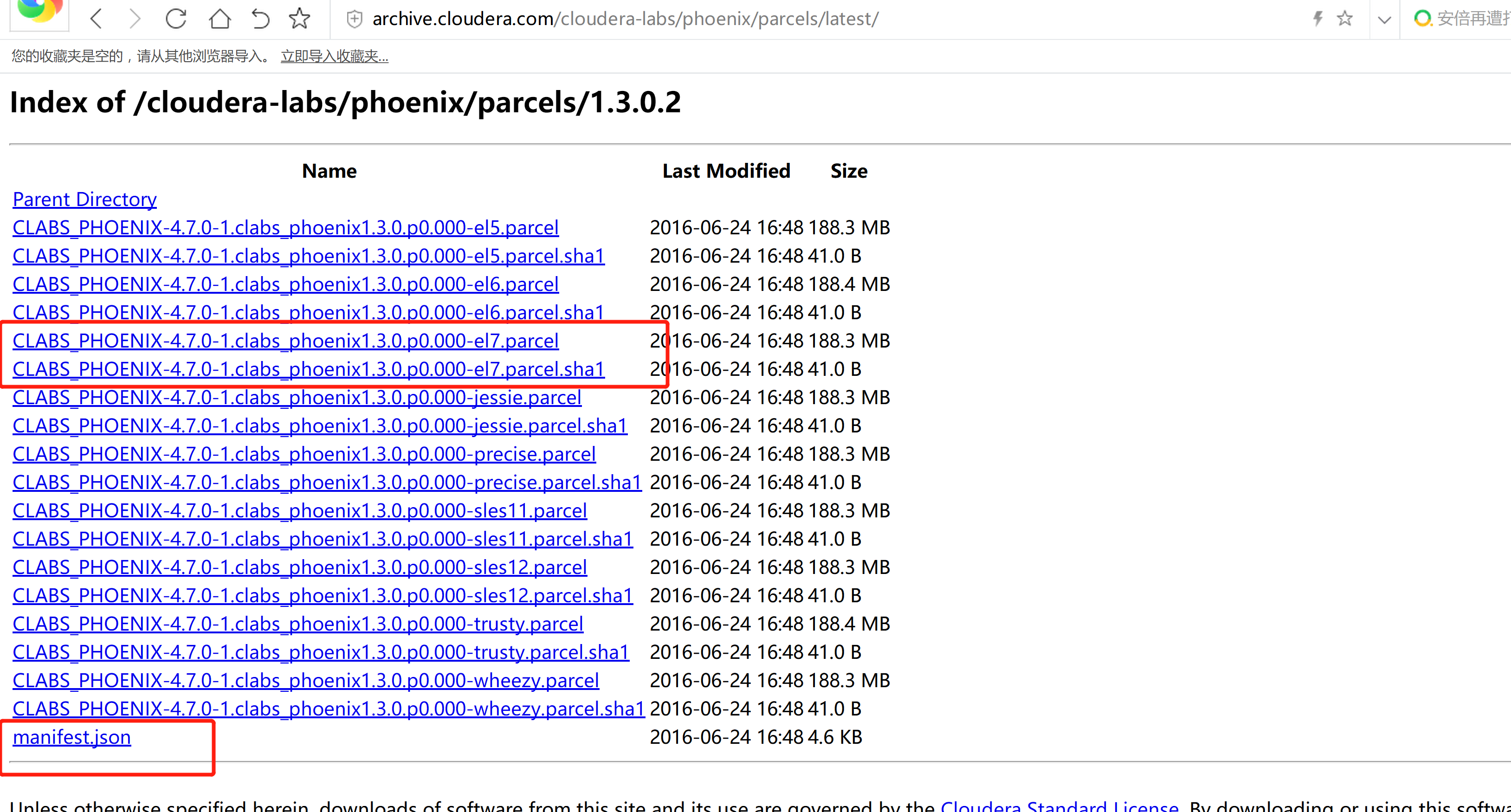
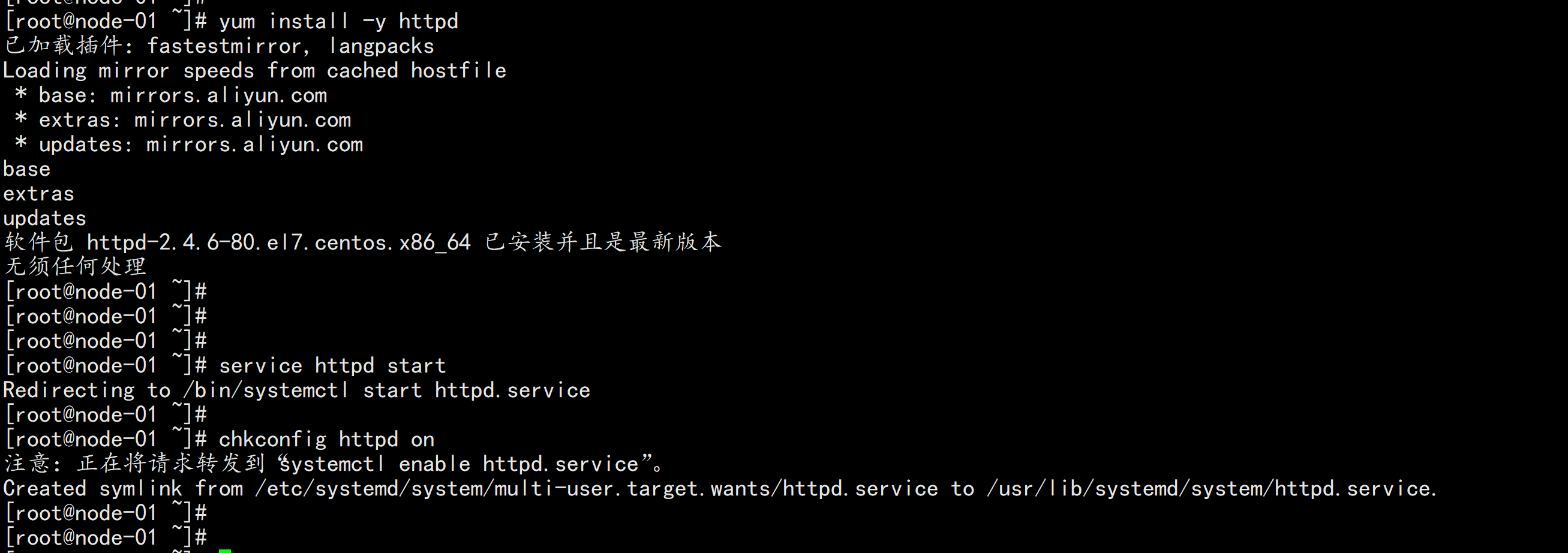
yum install -y httpd*
service httpd start
chkconfig httpd on
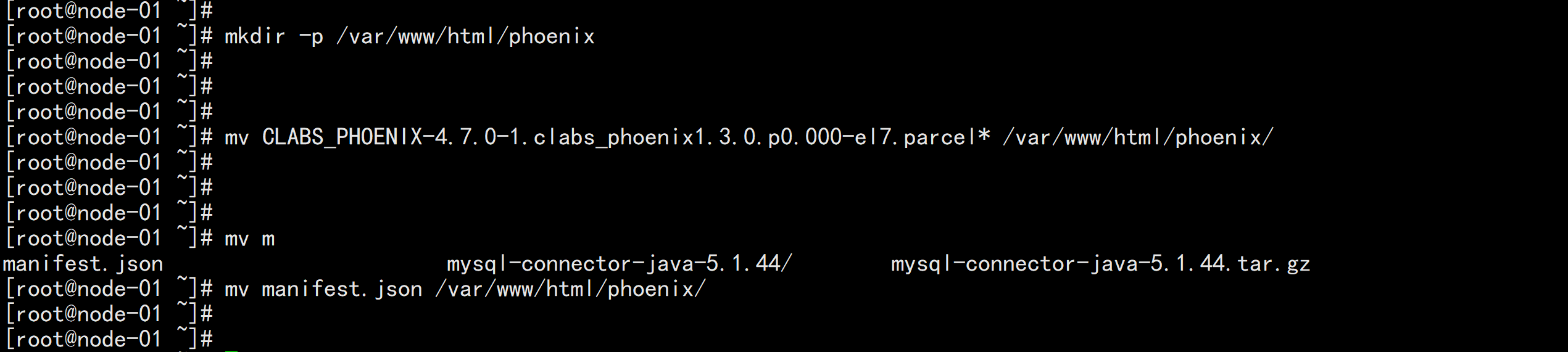
mkdir -p /var/www/html/phoenix
mv CLABS_PHOENIX-4.7.0-1.clabs_phoenix1.3.0.p0.000-el7.parcel* /var/www/html/phoenix/
mv manifest.json /var/www/html/phoenix/
cd /var/www/html/phoenix/
mv CLABS_PHOENIX-4.7.0-1.clabs_phoenix1.3.0.p0.000-el7.parcel.sha1 CLABS_PHOENIX-4.7.0-1.clabs_phoenix1.3.0.p0.000-el7.parcel.sha

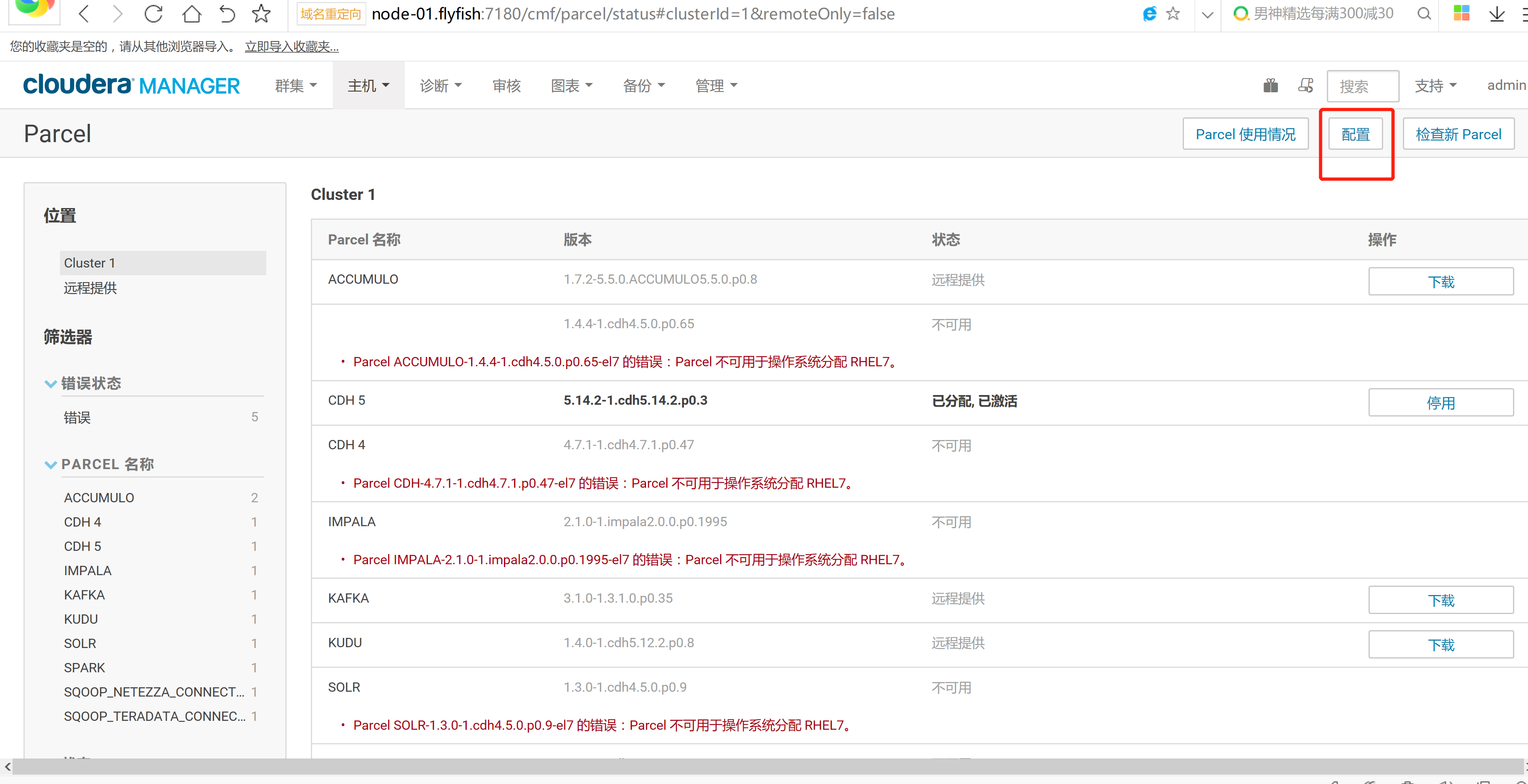
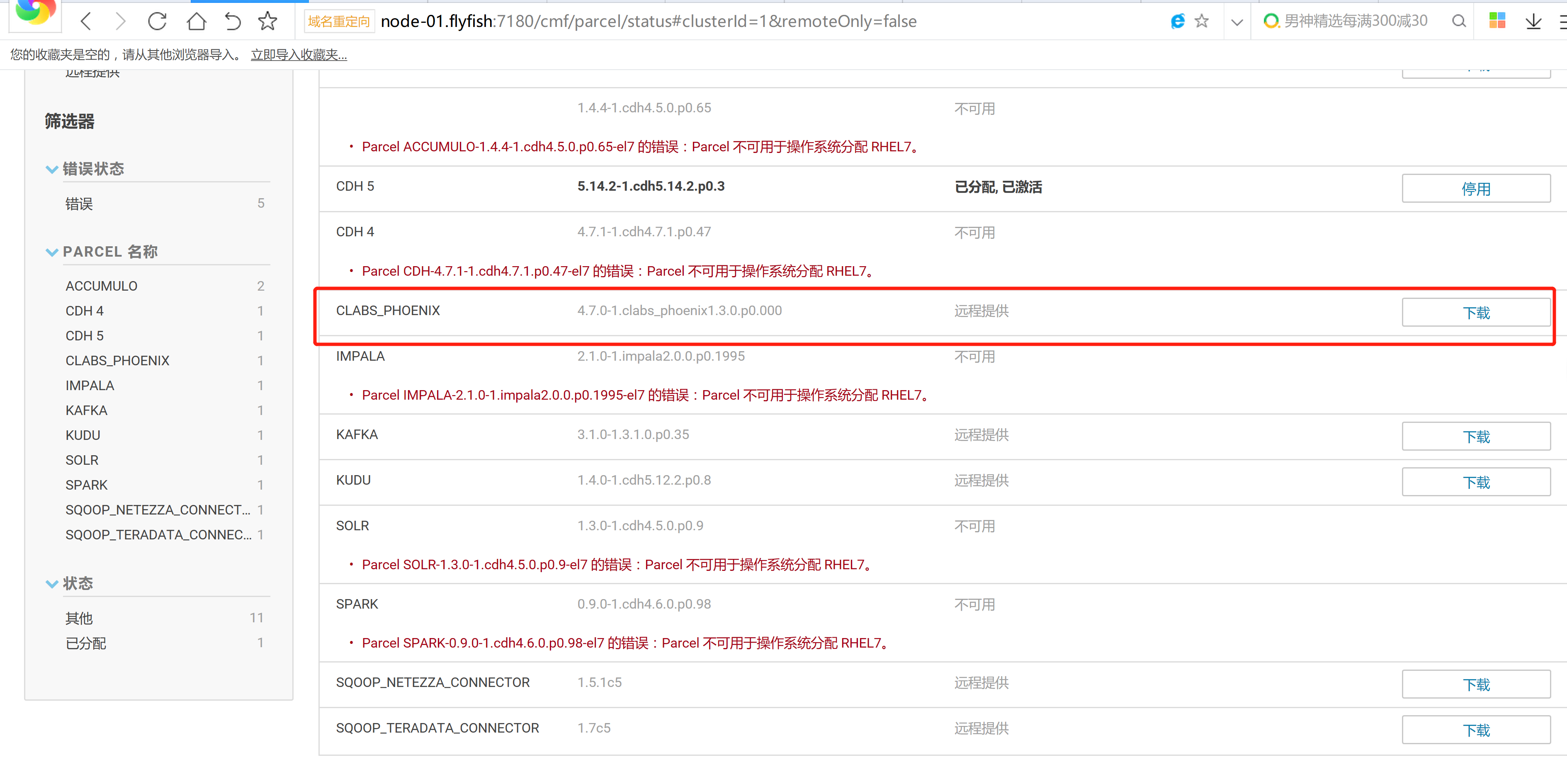
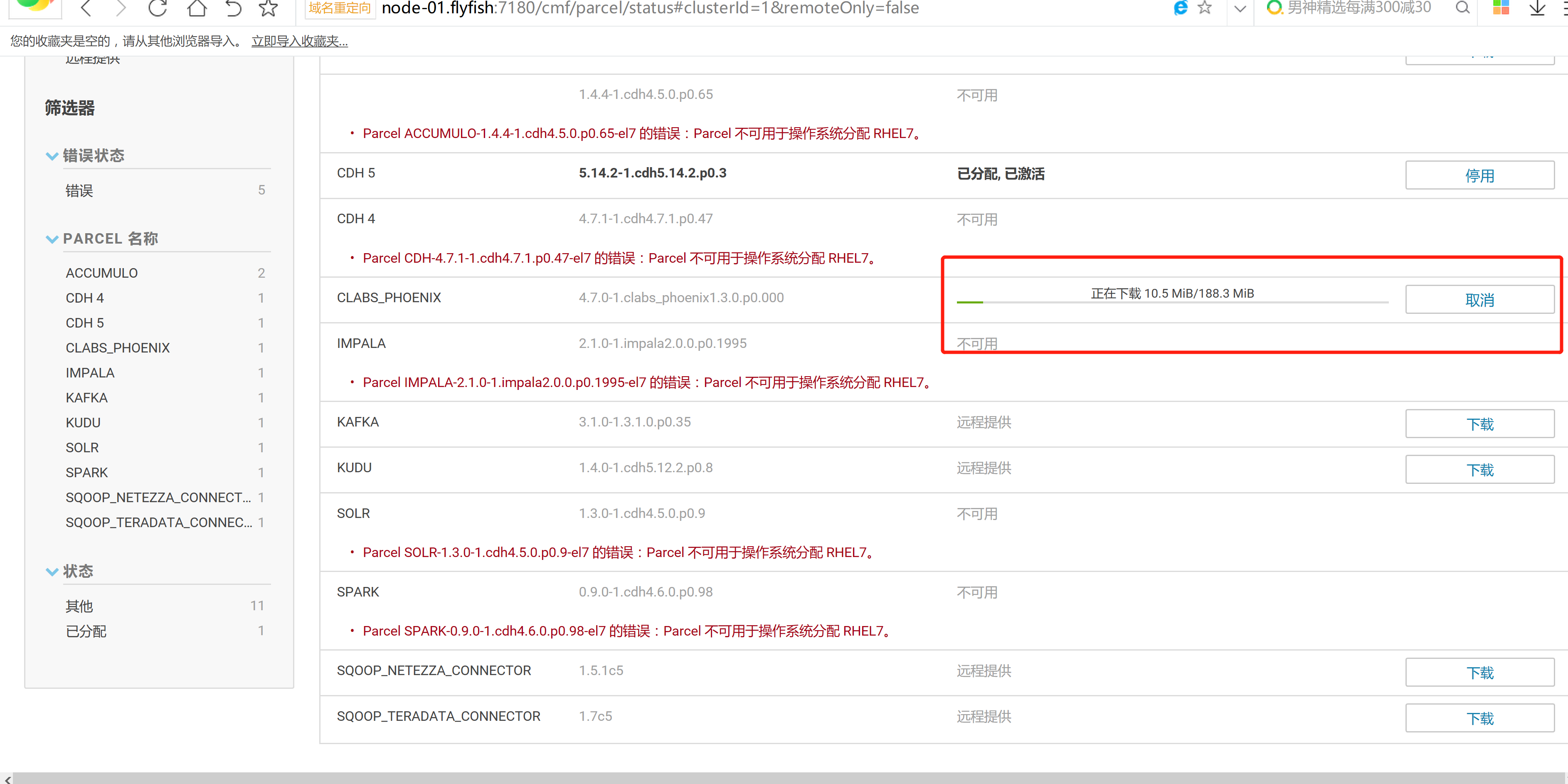


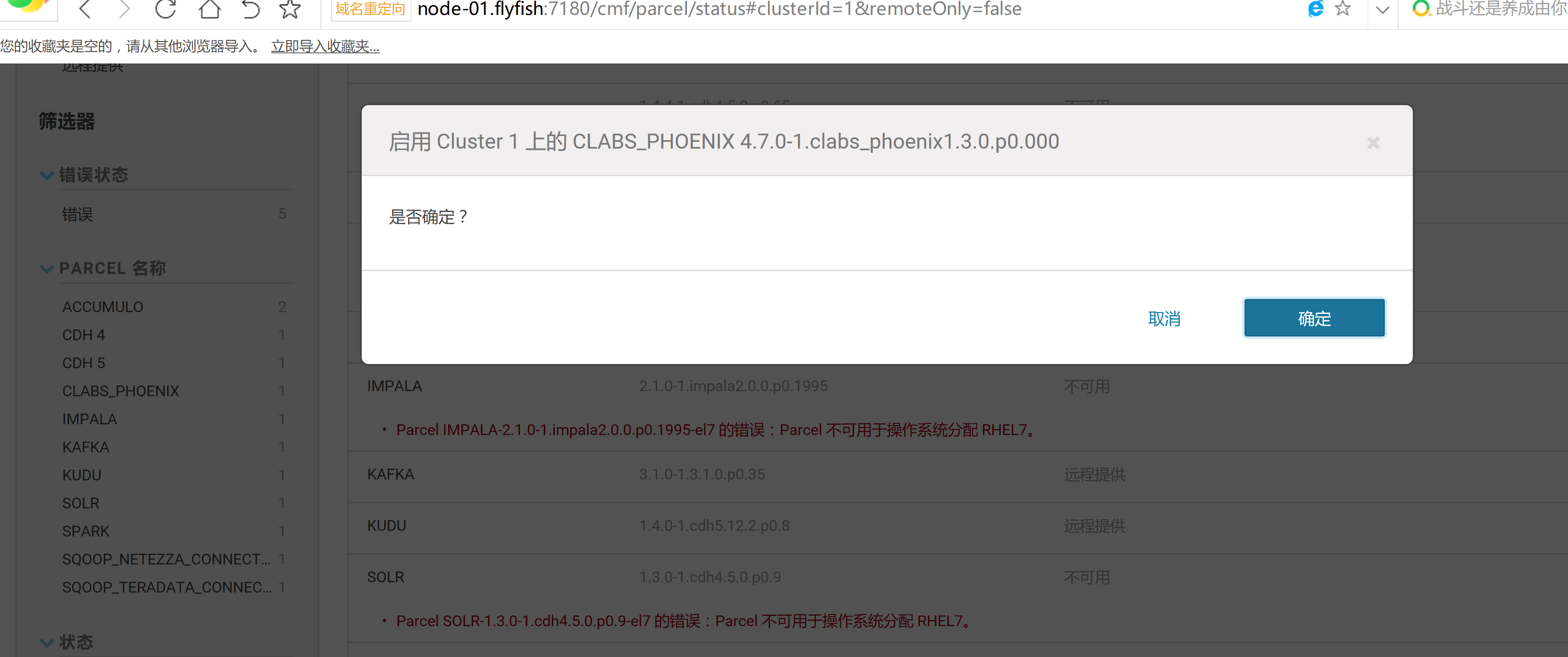
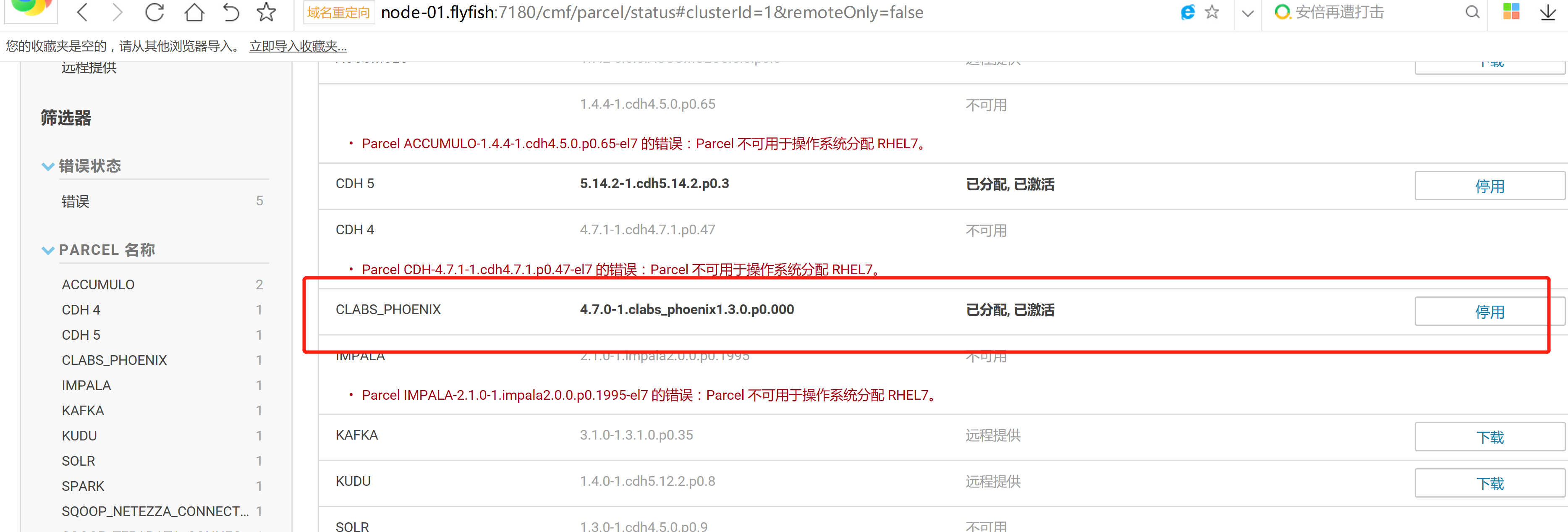
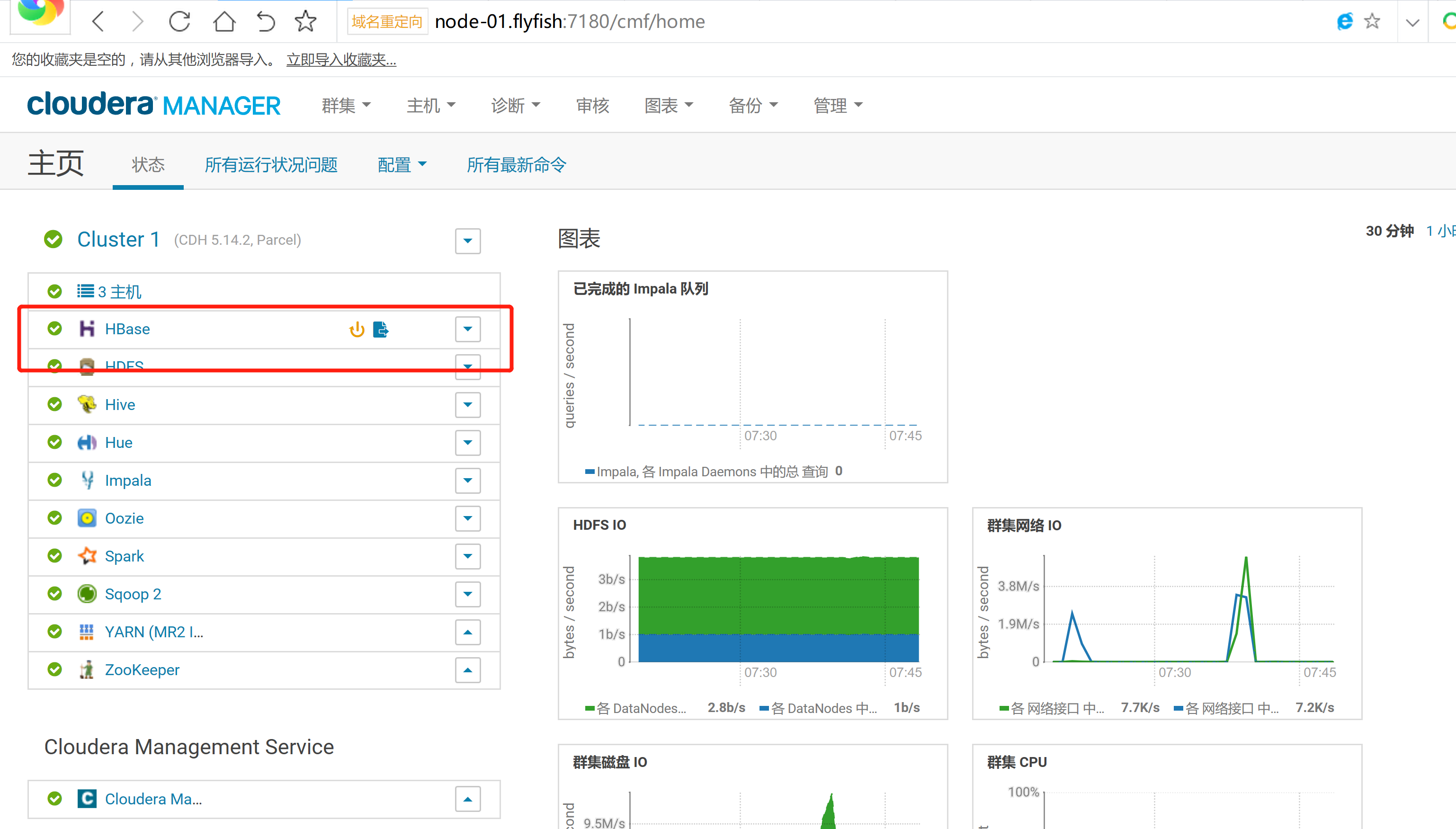
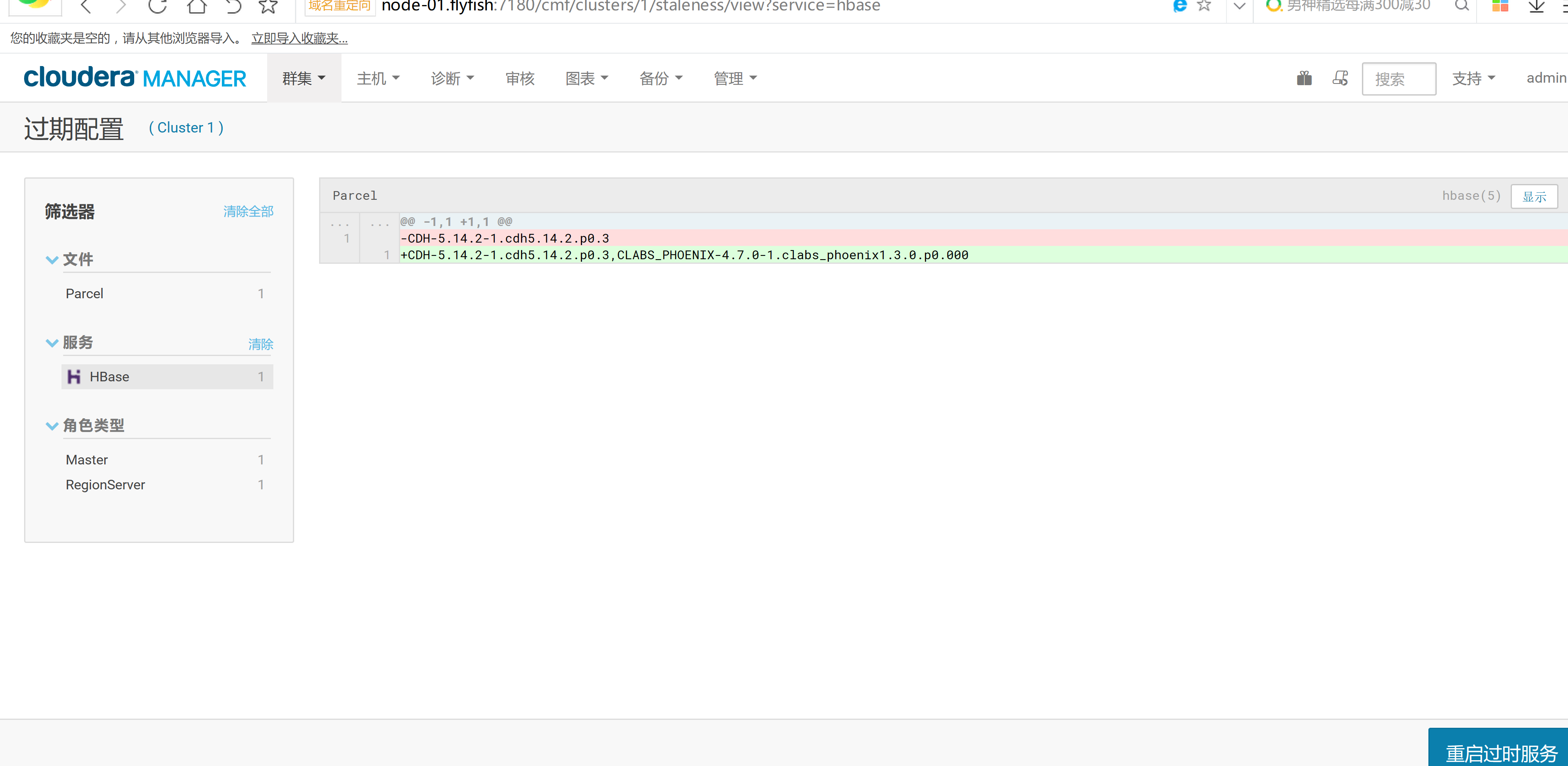
cd /opt/cloudera/parcels/CLABS_PHOENIX/bin
使用Phoenix登录HBase
./phoenix-sqlline.py

需要指定Zookeeper
./phoenix-sqlline.py node-01.flyfish:2181:/hbase
!table 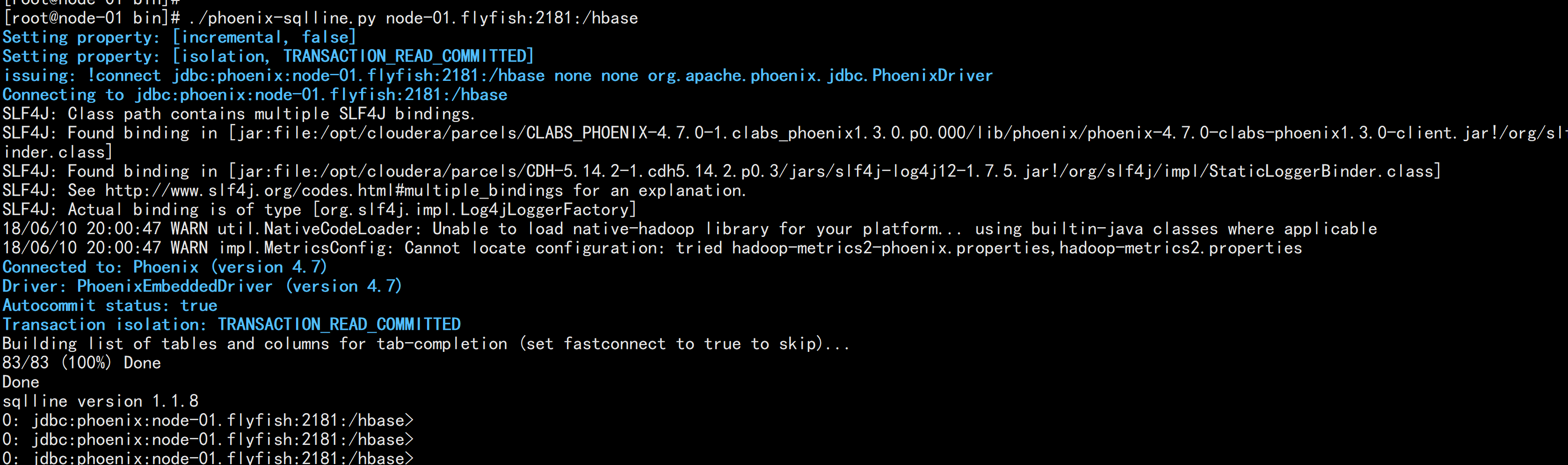

create table hbase_test
(
s1 varchar not null primary key,
s2 varchar,
s3 varchar,
s4 varchar
);

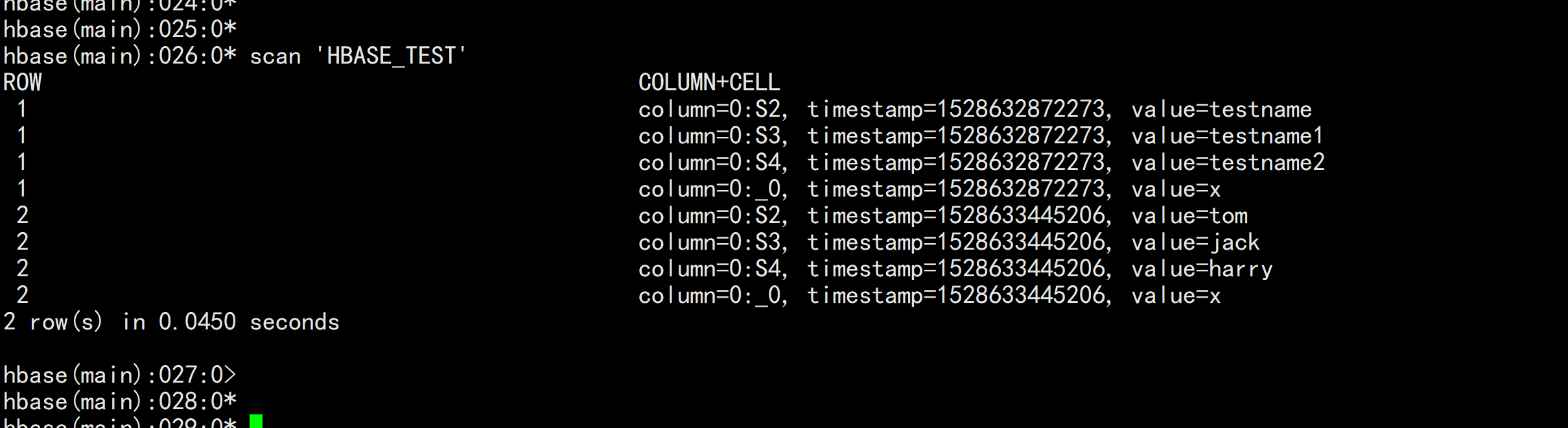
hbase 的接口登录
hbase shell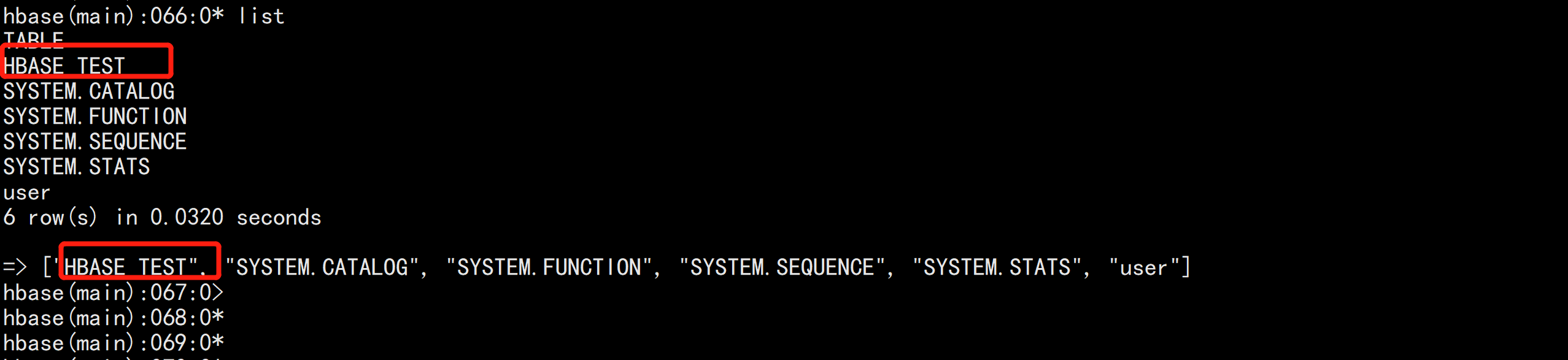

upsert into hbase_test values(‘1‘,‘testname‘,‘testname1‘,‘testname2‘);
upsert into hbase_test values(‘2‘,‘tom‘,‘jack‘,‘harry‘);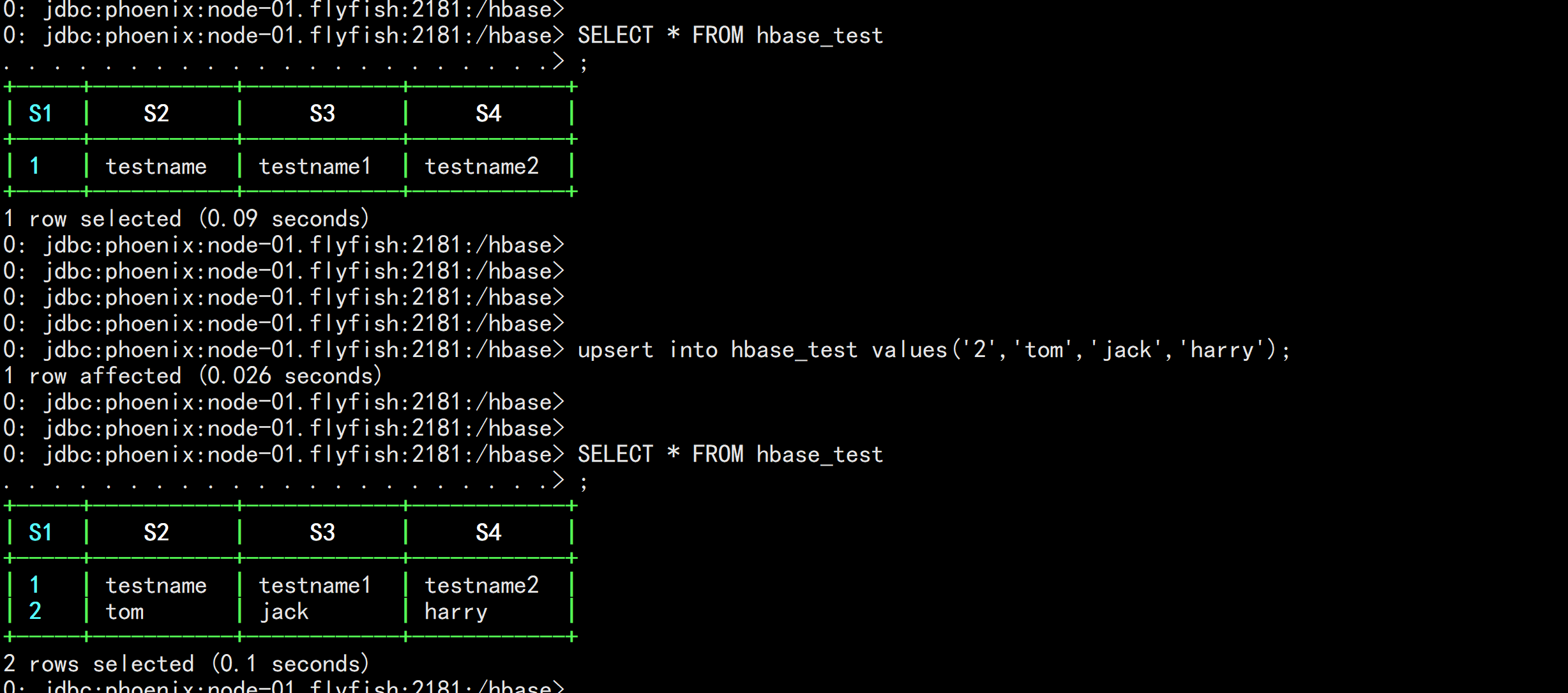
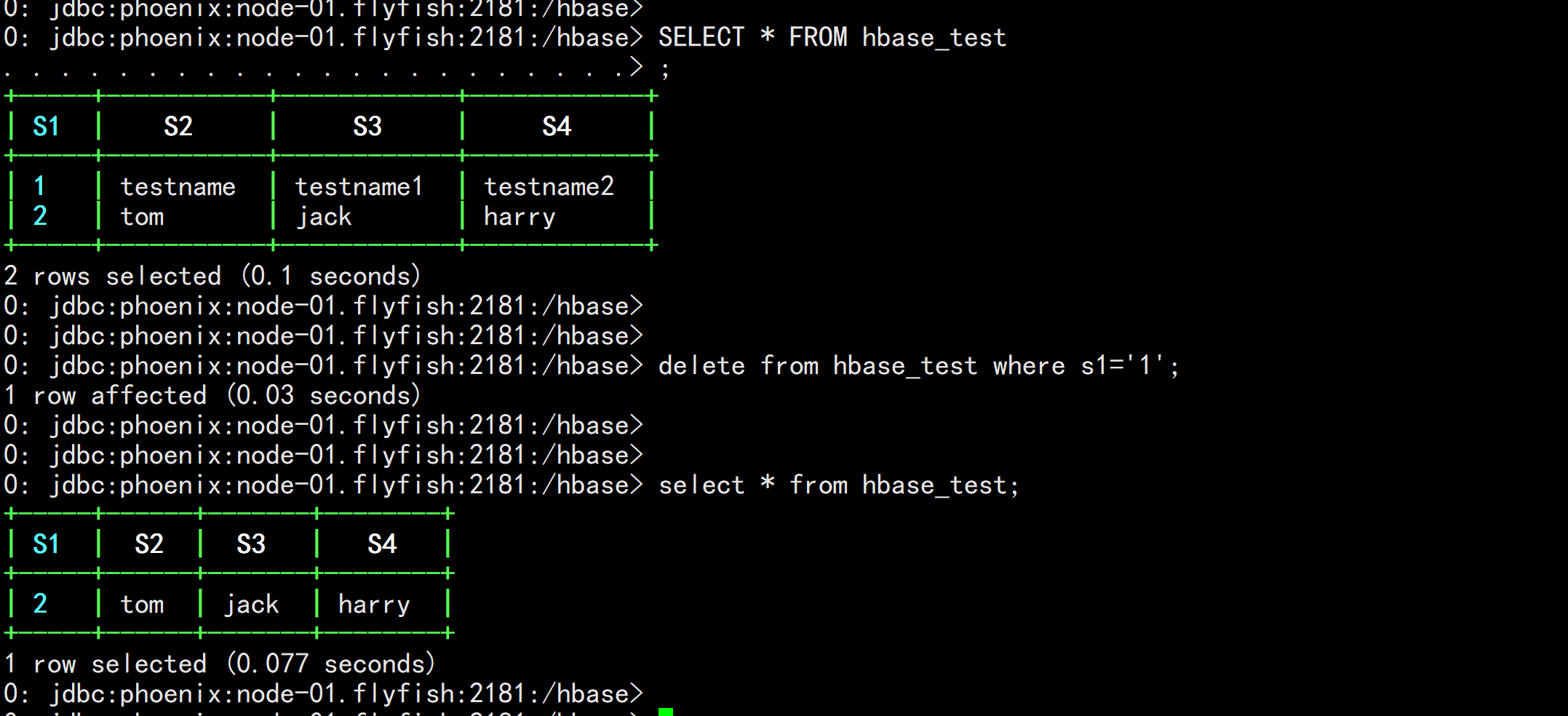
删除:
delete from hbase_test where s1=‘1‘; (删除是按rowkey)

upsert into hbase_test values(‘1‘,‘hadoop‘,‘hive‘,‘zookeeper‘);
upsert into hbase_test values(‘2‘,‘oozie‘,‘hue‘,‘spark‘);
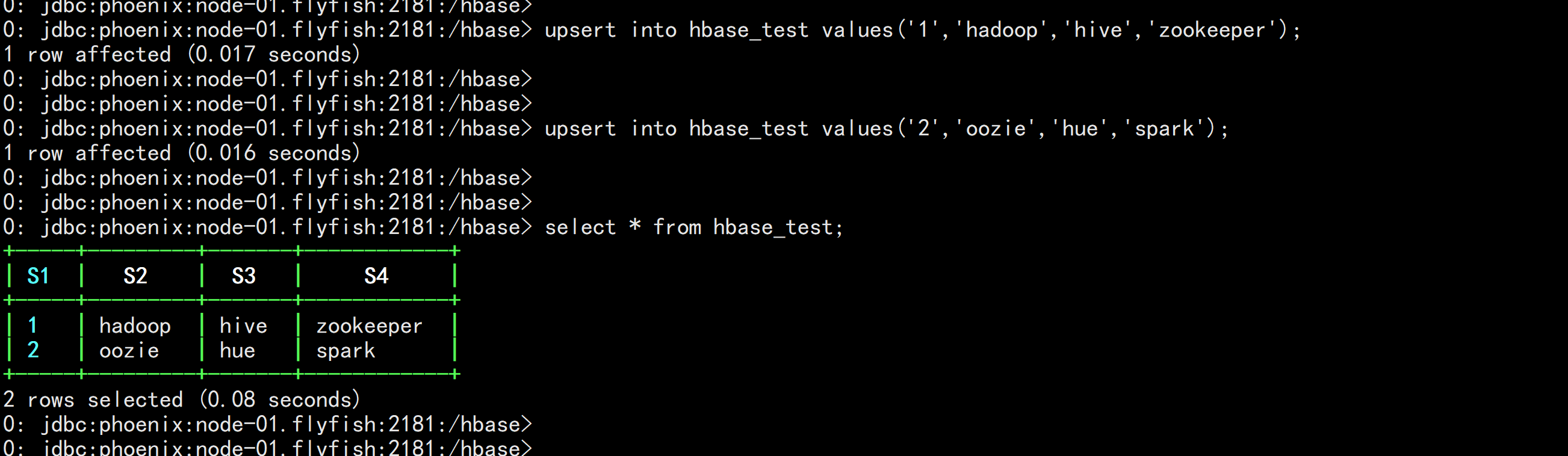
更新数据测试,注意Phoenix中没有update语法,用upsert代替。插入多条数据需要执行多条upsert语句,没办法将所有的数据都写到一个“values”后面。
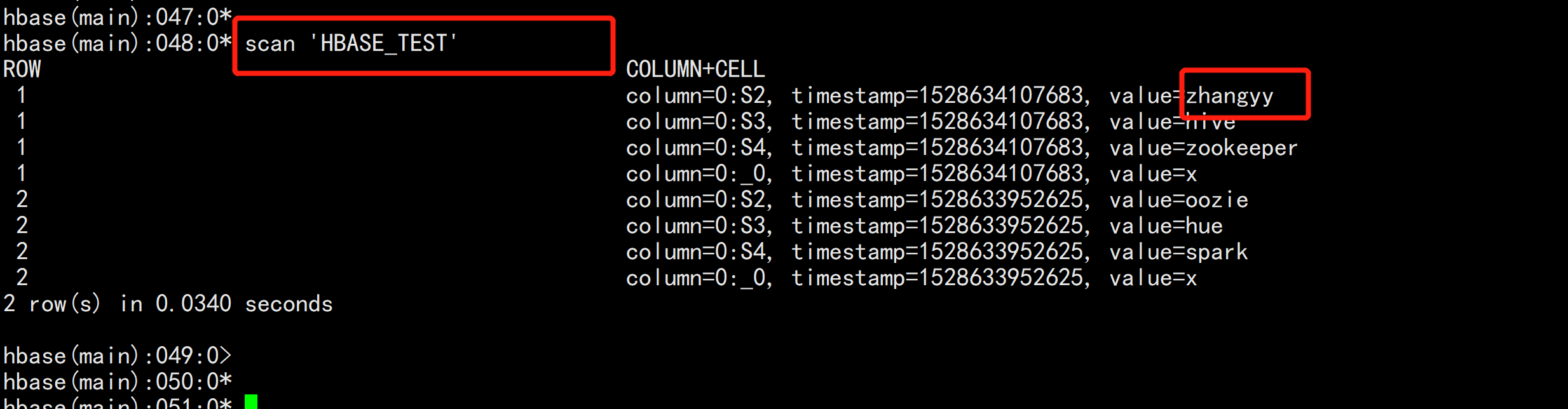
upsert into hbase_test values(‘1‘,‘zhangyy‘,‘hive‘,‘zookeeper‘);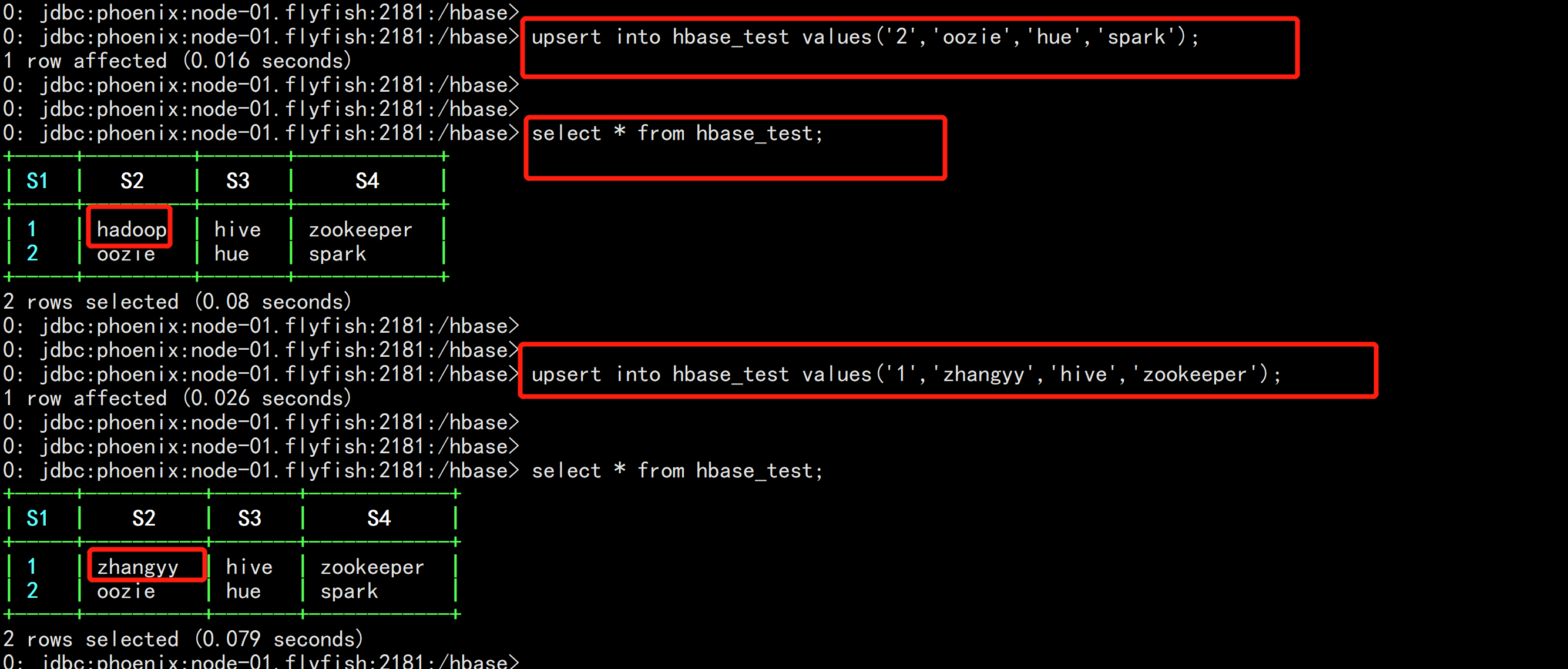
准备 导入的 测试文件
ls -ld ithbase.csv
head -n 1 ithbase.csv
上传到hdfs
su - hdfs
hdfs dfs -mkdir /flyfish
hdfs dfs -put ithbase.csv /flyfish
hdfs dfs -ls /flyfish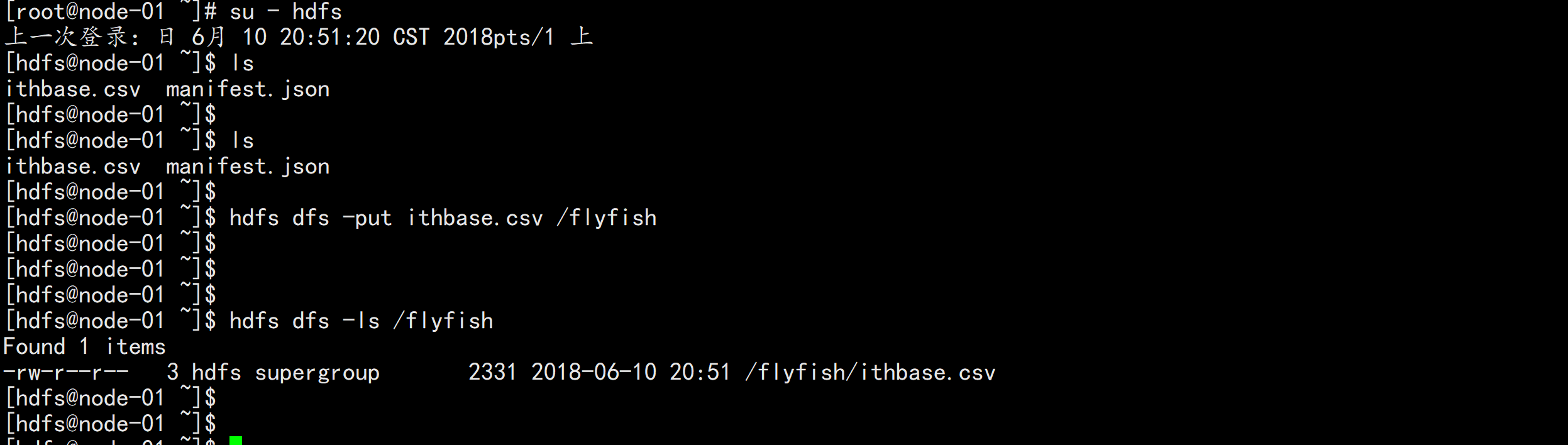
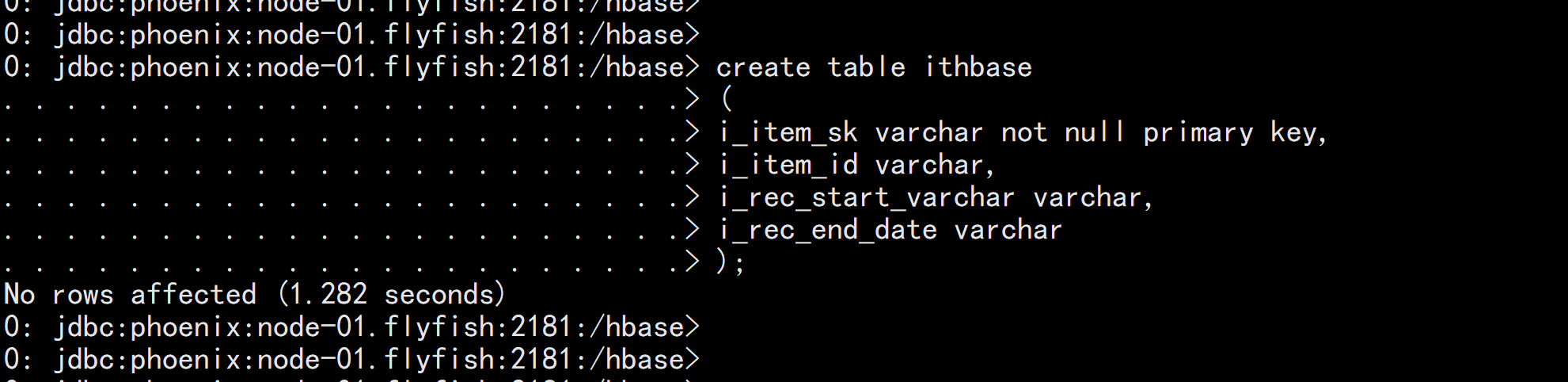
create table ithbase
(
i_item_sk varchar not null primary key,
i_item_id varchar,
i_rec_start_varchar varchar,
i_rec_end_date varchar
);
执行bulkload命令导入数据
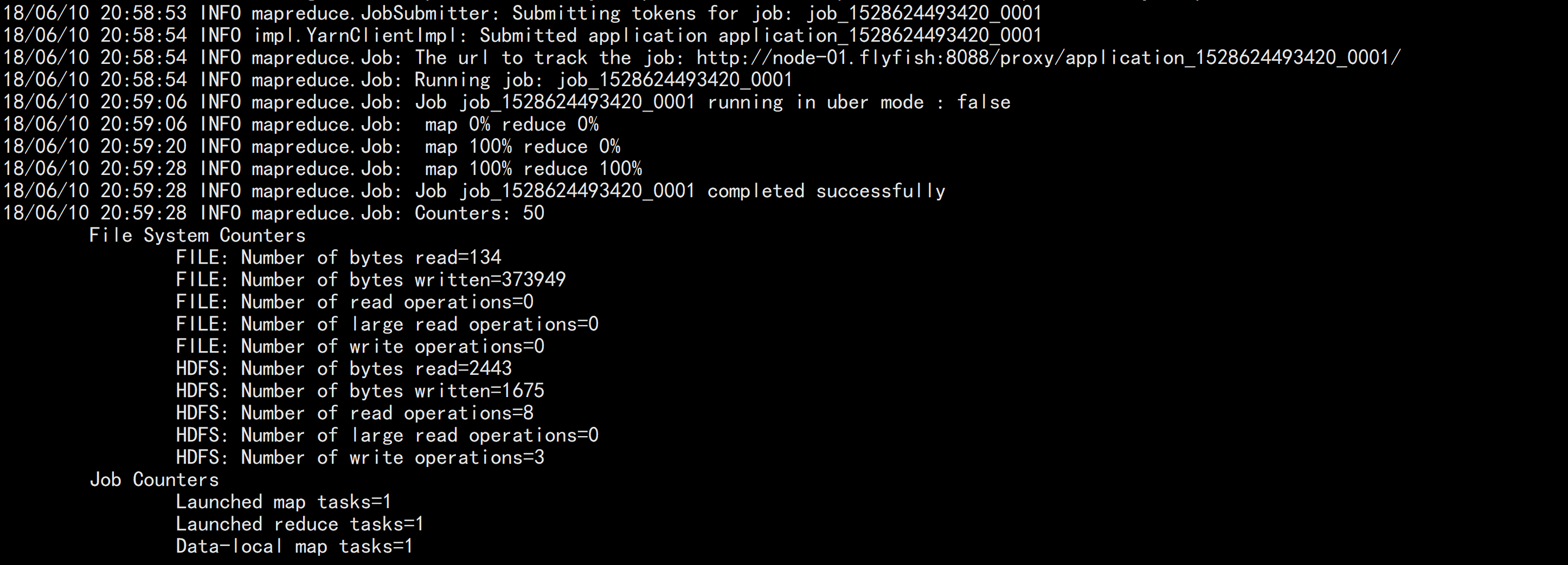
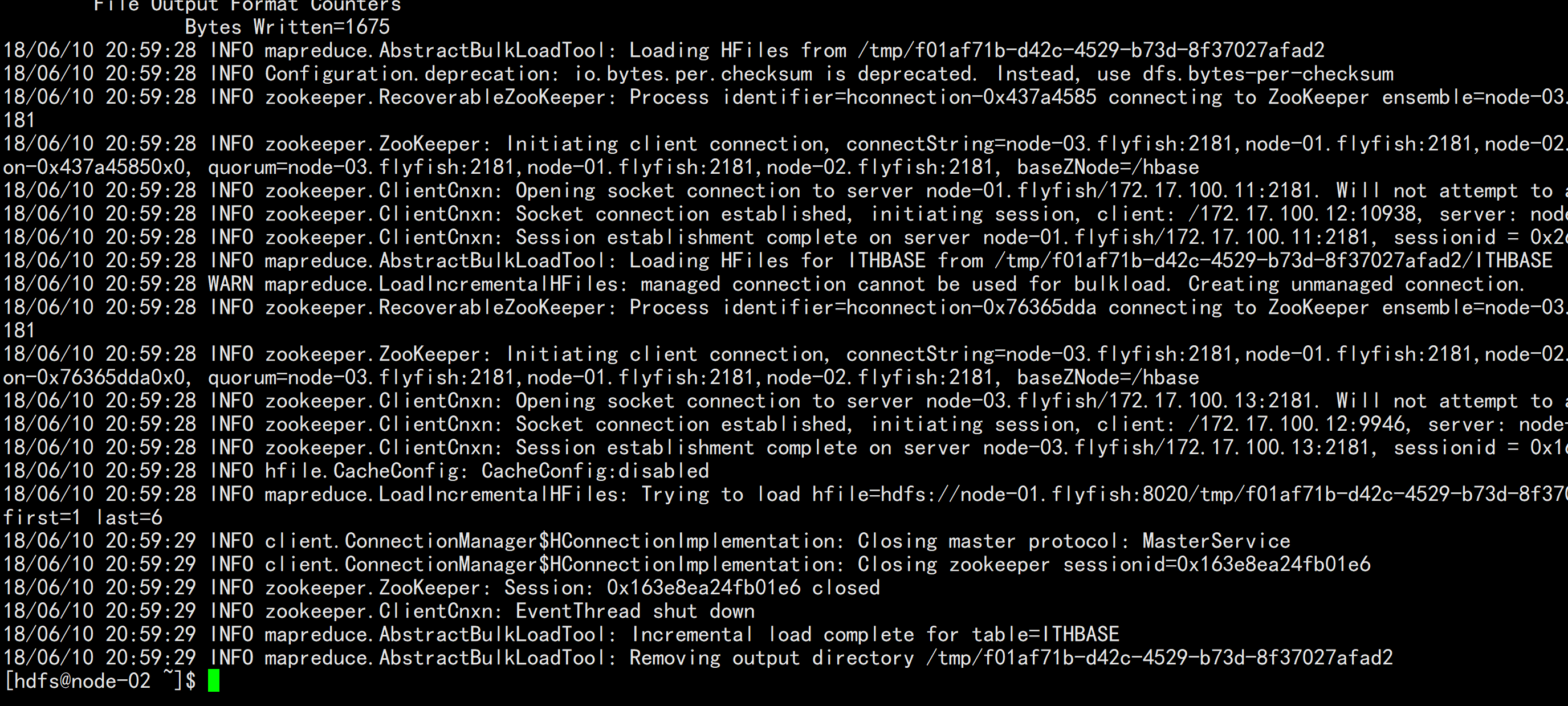
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol-1.2.0-cdh5.12.1.jar:/opt/cloudera/parcels/CDH/lib/hbase/conf hadoop jar /opt/cloudera/parcels/CLABS_PHOENIX/lib/phoenix/phoenix-4.7.0-clabs-phoenix1.3.0-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool -t ithbase -i /flyfish/ithbase.csv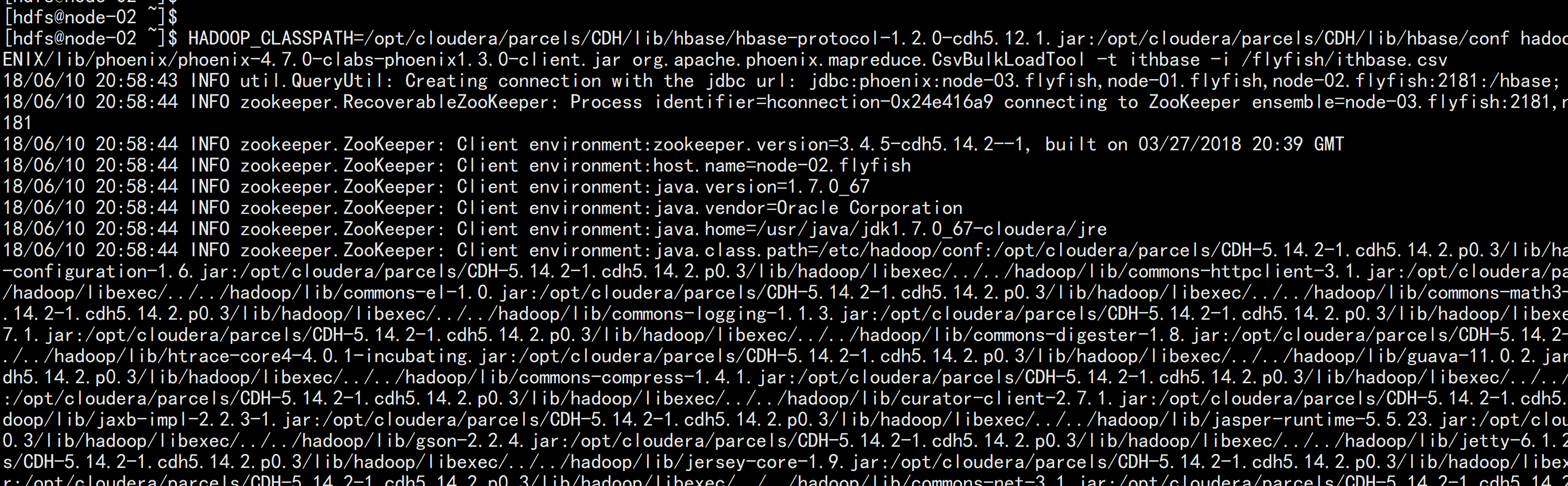
select * from ithbase 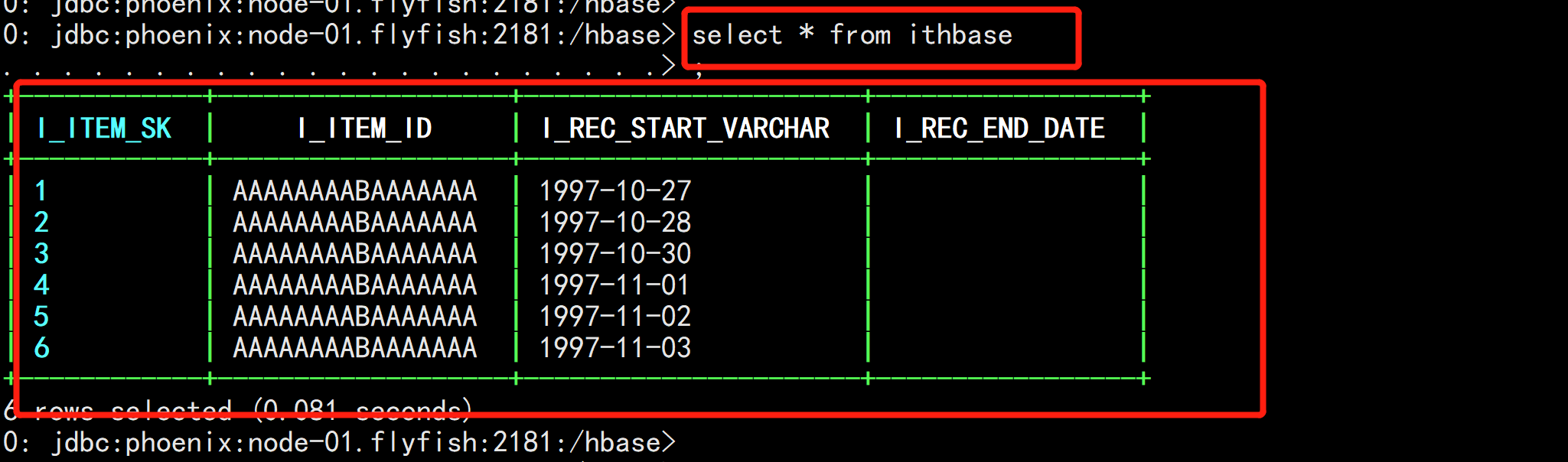

cat export.pig
----
REGISTER /opt/cloudera/parcels/CLABS_PHOENIX/lib/phoenix/phoenix-4.7.0-clabs-phoenix1.3.0-client.jar;
rows = load ‘hbase://query/SELECT * FROM ITHBASE‘ USING org.apache.phoenix.pig.PhoenixHBaseLoader(‘node-01.flyfish:2181‘);
STORE rows INTO ‘flyfish1‘ USING PigStorage(‘,‘);
----
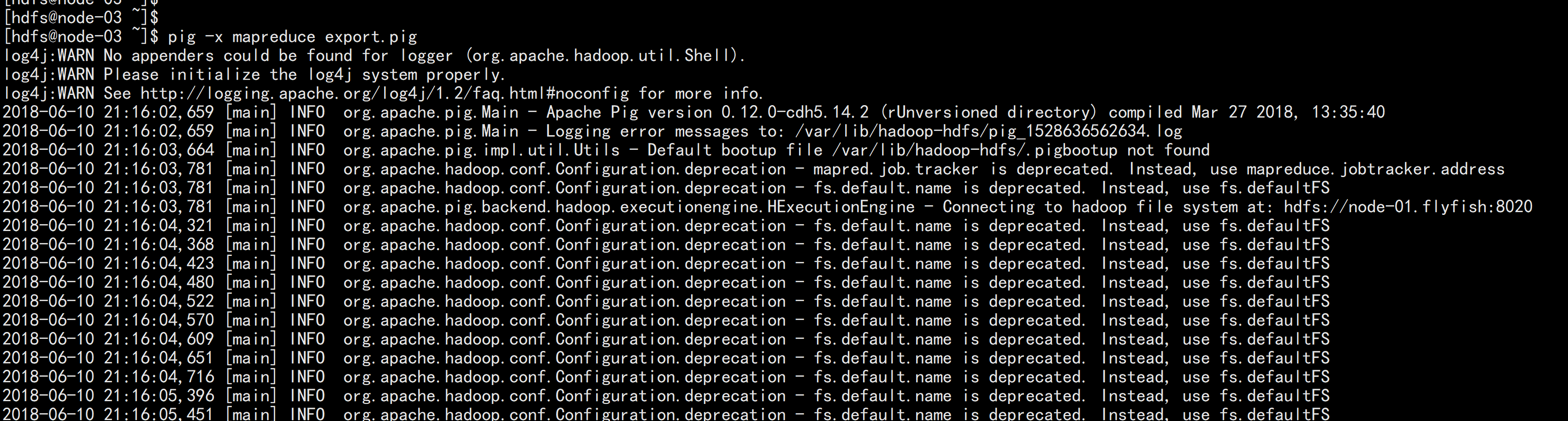
执行pig
pig -x mapreduce export.pig

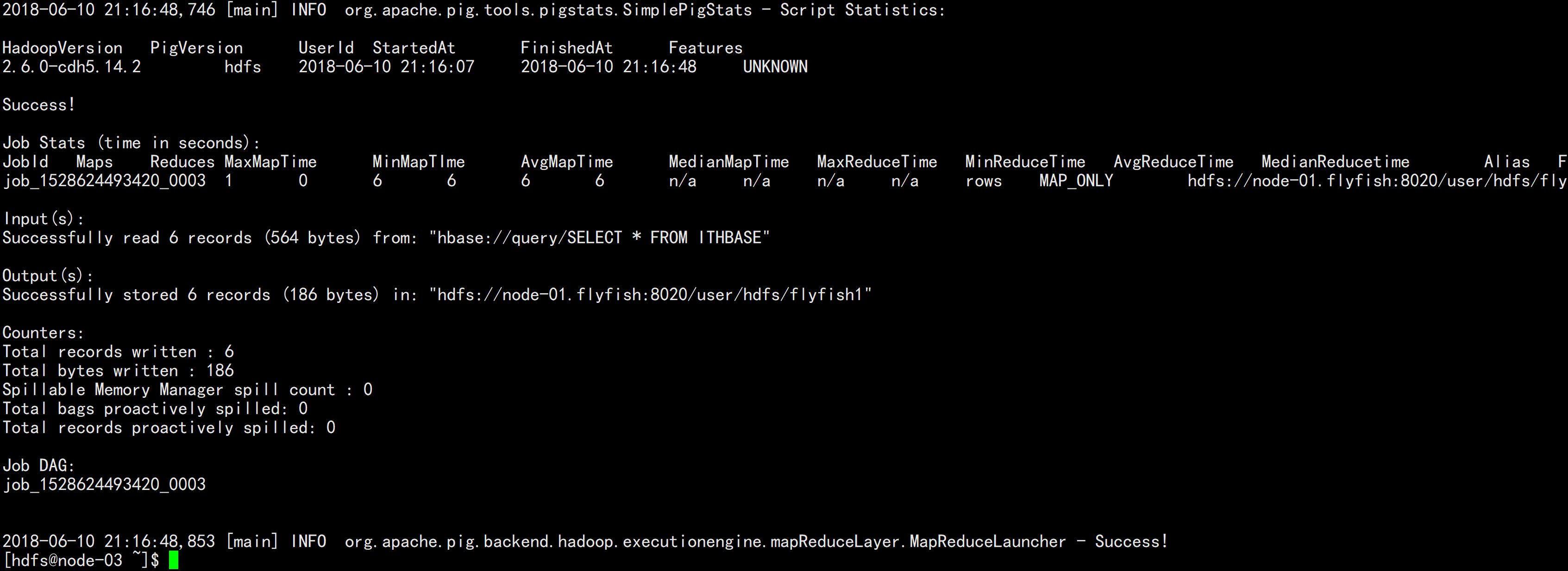
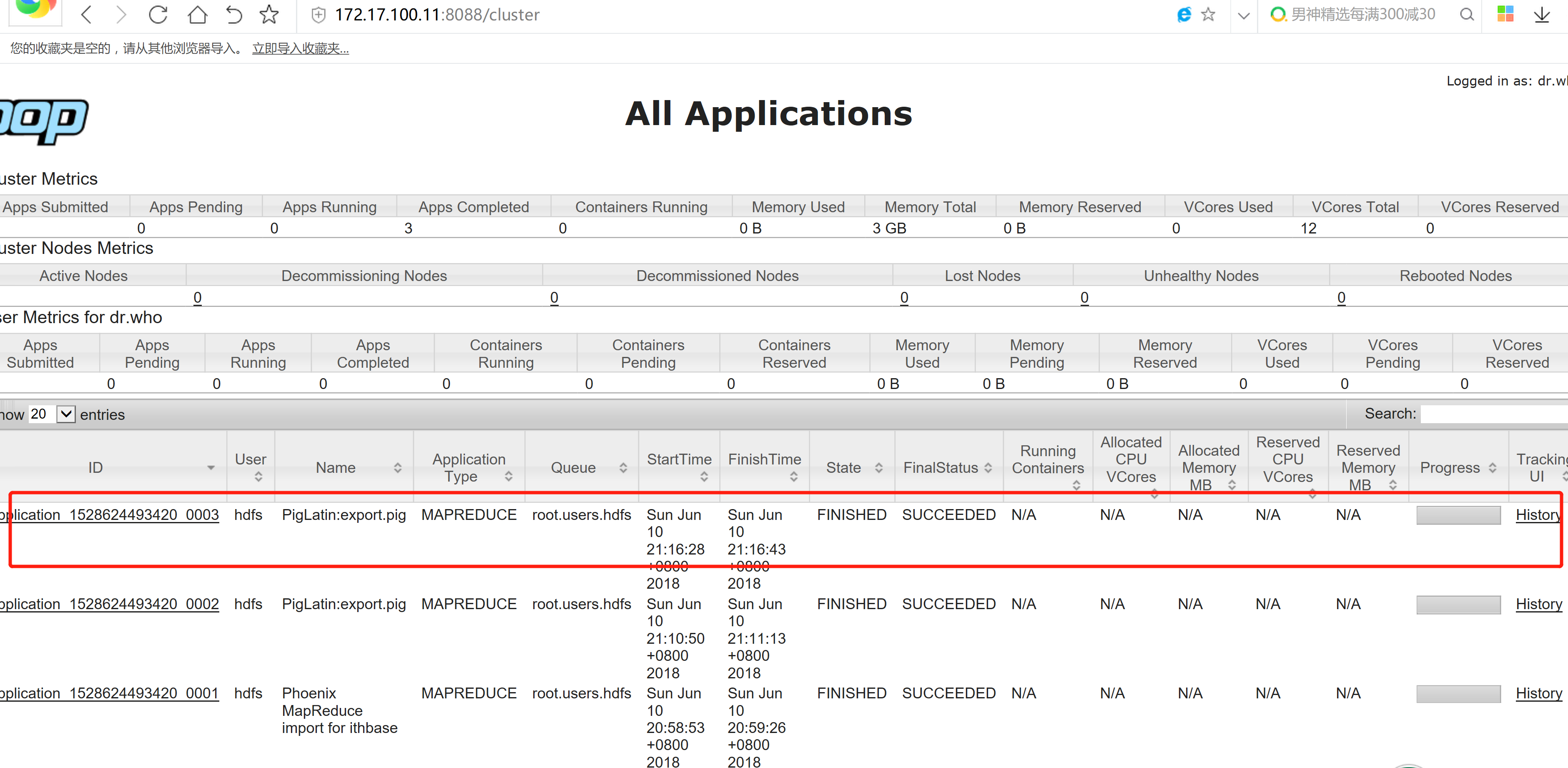
在hdfs 上面查看文件
hdfs dfs -ls /user/hdfs/flyfish1
hdfs dfs -cat /user/hdfs/flyfish1/part-m-00000
原文地址:http://blog.51cto.com/flyfish225/2127857