标签:编写 网站 json 监测 scrapy bottom 问题 联系 ade
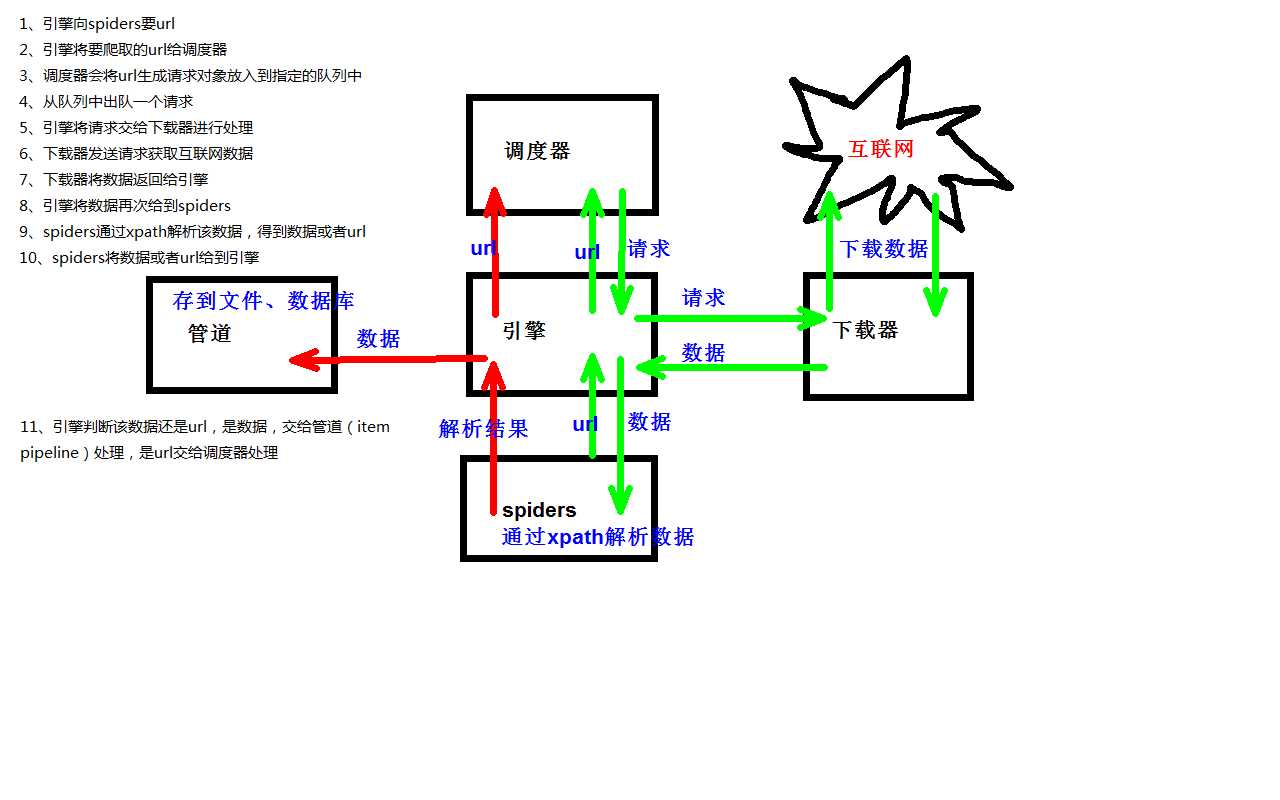
Scrapy由 Python 编写,是一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。

1、创建一个Scrapy项目
2、定义提取的Item
3、编写爬取网站的 spider 并提取 Item
4、编写 Item Pipeline 来存储提取到的Item(即数据)
1、 Scrapy Items :定义您想抓取的数据
import scrapy
class TorrentItem(scrapy.Item):
2、spiders:编写提取数据的Spider
1):定义初始URL根网址、 针对后续链接的规则以及从页面中提取数据的规则(即写正则或xpath等等)。
2)执行spider,获取数据
注:运行spider来获取网站的数据,并以JSON格式存入到scraped_data.json 文件中:
terminal:scrapy crawl mininova -o scraped_data.json
3、编写 item pipeline 将item存储到数据库中
注:
1)、Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理;
2)每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
3)item pipeline的一些典型应用:
a)清理HTML数据
b)验证爬取的数据(检查item包含某些字段)
c)查重(并丢弃)
4)将爬取结果保存到数据库中
4、编写自己的item pipeline
注:每个item pipiline组件是一个独立的Python类,同时必须实现以下方法:
1)process_item(item, spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的item将不会被之后的pipeline组件所处理。
参数:
item (Item 对象) – 被爬取的item
spider (Spider 对象) – 爬取该item的spider
2)open_spider(spider)
当spider被开启时,这个方法被调用。
参数:spider (Spider 对象) – 被开启的spider
3)close_spider(spider)
当spider被关闭时,这个方法被调用
参数:spider (Spider 对象) – 被关闭的spider
5、查看提取到的数据
执行结束后,查看 scraped_data.json , 将看到提取到的item:
注 :1)由于 selectors 返回list, 所以值都是以list存储的(除了 url 是直接赋值之外)。
2) Item Loaders :可以保存单个数据或者对数据执行额外的处理
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加QQ群:483766429 或联系作者本人 QQ :87605025
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事说三遍。。。。。。


标签:编写 网站 json 监测 scrapy bottom 问题 联系 ade
原文地址:https://www.cnblogs.com/xxtalhr/p/9170343.html