标签:shu crawler ima lin 网站 原理 正则表达式 site 技术分享
一 设计抓取策略
1 深度优先
2 广度优先
3 部分的PageRank策略
4 OPIC策略
5 大站优先策略
https://blog.csdn.net/a575553272/article/details/80265182
二 垂直搜索爬虫
垂直搜索与通用搜索不同之处在于,通用搜索不需要理会网站哪些资源是需要的,哪些是不需要的,一并抓取并将其文本部分做索引。而垂直搜索里,我们的目标网站往往在某一领域具有其专业性,其整体网站的结构相当规范,并且垂直搜索往往只需要其中一部分具有垂直性的资源,所以垂直爬虫相比通用爬虫更加精确。
垂直爬虫抓取数据分成三个步骤:list-crawling(列表url抓取),detail-crawling(详情url抓取),data-extract and store (数据抽取和存储),其实原理上并不复杂,以下是整体垂直搜索的架构及流程图:
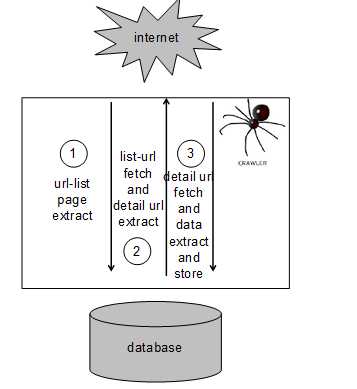
1. 首先运营人员会选定需要抓取的目标网站,录入数据库的站源表sitelist,即这些url作为爬虫的seed。同时,开发人员会在爬虫规则库中增加相应网站的规则解析。
2.crawler读取种子url,根据事先制定的规则(一般是正则表达式规则),从种子url中进行列表页url的抽取,并提取出来保存到数据库中(实际工作中,直接抽取出来放到调度队列中,继续抓取)。需要注意的是,很多网站的列表页的url都是通过js的方式处理的,因此制定规则时,需要懂得js分析。
3. 进行列表页url的请求,之后抽取出详情页的url列表
4. 进行详情页url的请求,之后抽取出具体的数据。
以上就是垂直爬虫的工作过程,为什么要分成三步走呢?这样能够将风险分化,不至于某个地方错了,必须整个重来。
三 改善调度算法
https://www.cnblogs.com/wangshuyi/p/6737389.html
四 增量爬取
https://blog.csdn.net/zcc_0015/article/details/50608063
五 监控流程
pass
标签:shu crawler ima lin 网站 原理 正则表达式 site 技术分享
原文地址:https://www.cnblogs.com/654321cc/p/9179388.html