标签:har 变化 error: TE 正是 之间 == type idt
变量:将计算的中间结果储存起来,以便后续代码使用
问题来了:变量存在哪里呢,或许可以这样问:变量储存在内存哪里呢?
内存会进行分区,每个分区都有一个序号,而每个分区里面都储存着数据,变量就来自这里,而分区的序号就叫内存地址
python 这门语言不像 C 语言,C 语言是属于内存级别的语言,C 涉及到指针,内存。而 python 不同,它的内存级别的已经设计好了。所以 python 比 C 简单,也正是如此,虽然 python 也有内存地址这个概念,但是它的内存地址和真实的内存地址是不一样的,只是 python 解释器虚拟的一个地址
name = ‘alex‘ print(id(name)) #查询‘alex’的内存地址 2471424258264 name = ‘alex‘ print(id(name)) #再次查询 1648814026968 #id出现变化
一个等号 “=” 代表赋值,两个等号 “==” 代表比较是否相等
is 内存地址是否相同 【验证内存地址是否相等不能在pycharm中进行,必须在终端验证】
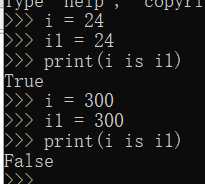
因为第一个是 True 所以 i 和 i1 在内存中用的是同一个值,第二个是 False 所以 i 和 i1 在内存中用的是两个值 这就引出来小数据池的概念
只存在于 int(整数) str(字符串)当中,在一定范围内,如果两个数值相同:为了节省内存,共用一个内存地址。

int的范围: -5 ~256
str的限制条件【不知道全不全】:
1.单个字母元素*个数(不能超过21)存在小数据池
2.自己设置的字符串(只包含数字字母),不管多大,都存在小数据池
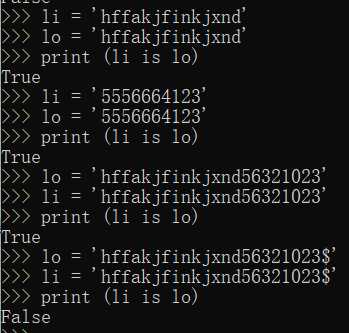
1.不同的密码本之间的二进制是不能全互相识别的,容易报错或者产生乱码

#gbk utf-8 #对于字母,数字,特殊符号的编码都是引用 ascii 码,所以可以直接转化。 s1 = ‘123asd*&^‘ b1 = s1.encode(‘utf-8‘) # 转化为 utf-8 的字节 s2 = b1.decode(‘gbk‘) #直接转化 gbk 的字符串 print(s2) 123asd*&^
2.计算机的文件存储和传输都是二进制 010101 (gbk , utf-8 , ascii , gb2312) 不能是unicode(万国码,造成资源浪费)
大前提:python3x ,编码
数据类型:
int
str
bytes (字节) : str 拥有的所有方法,bytes都有
bool
list
tupule (元组)
dict (字典)
set (集合)
str ; python3x 内存中的(字符串)编码方式是 Unicode (规定)
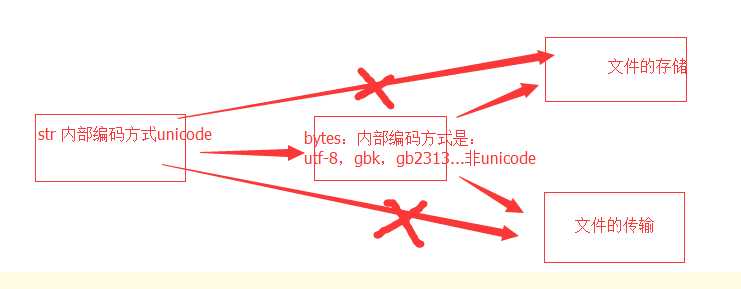
英文:
str:表现形式 name = ‘alex‘
内部编码: unicode
name = ‘alex‘ print(name,type(name)) alex <class ‘str‘>
bytes:表现形式: name1 = b‘alex‘
内部编码:非unicode
name1 = b‘alex‘ print(name1,type(name1)) b‘alex‘ <class ‘bytes‘>
中文:
str:表现形式: name = “中国”
内部编码: Unicode
name1 = ‘中国‘ print(name1,type(name1)) 中国 <class ‘str‘>
bytes:表现形式:b‘\xe4\xb8\xad\xe5\x9b\xbd‘
内部编码:非Unicode
name = ‘中国‘.encode(‘utf-8‘) print(name,type(name)) b‘\xe4\xb8\xad\xe5\x9b\xbd‘ <class ‘bytes‘> #\xe4 : 一个字节
四、str ---> bytes 转化 ‘字符串‘.encode(编码方式) # encode 编码
bytes--->str 转化 字节.decode(编码方式) # decode 解码
# 编码方式必须相同,否则会产生乱码或报错
name = ‘中国‘.encode(‘utf-8‘) print(name,type(name)) name1 = name.decode(‘gbk‘) print(name1,type(name1)) b‘\xe4\xb8\xad\xe5\x9b\xbd‘ <class ‘bytes‘> UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xad in position 2: illegal multibyte sequence #报错
标签:har 变化 error: TE 正是 之间 == type idt
原文地址:https://www.cnblogs.com/songzijian/p/8992610.html
