标签:基本 必看 突发奇想 add int lis bs4 其他 更新
虎扑是广大jrs的家园,步行街是这个家园里最繁华的地段。据称广大jrs平均学历985,步行街街薪30w起步。
大学时经舍友安利,开始了解虎扑,主要是看看NBA的一些资讯。
偶尔也上上这个破街,看看jrs虐虐狗,说说家长里短等等,别的不说,jr们的三观都是特别正的。
不冷笑话基本是我每天必看的帖子,感觉楼主非常敬业,每天都会有高质量的输出,帖子下的热帖也很给力,福利满满。
正学python,突发奇想想把不冷笑话的图都爬下来。
但是虎扑在这块有限制,不登录无法查看用户的帖子,而我目前又懒得弄登陆认证(主要是还没学通-_-||)。
经过长期的观察验证,我发现不冷笑话每次都在首页主干道的固定位置,于是萌生出了直接从首页定位到帖子里的想法。
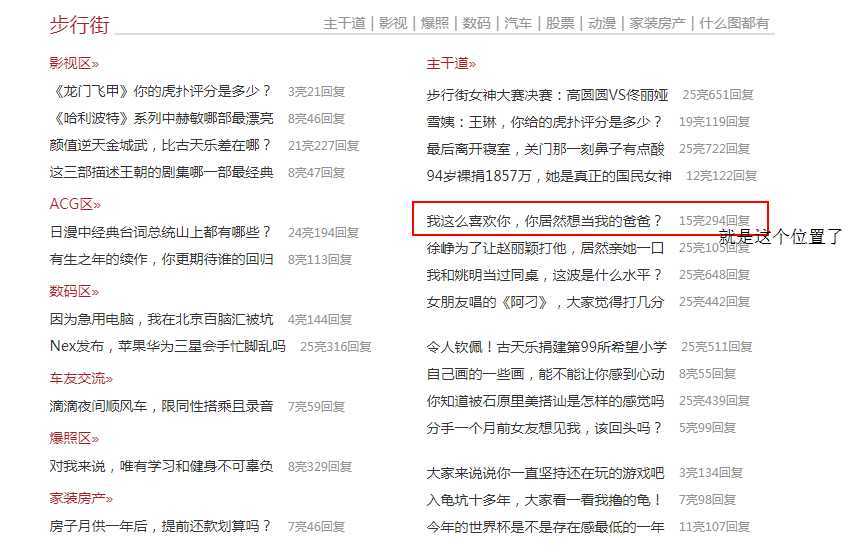
说干就干,经过我的一通分析,终于把程序写好了,爬虫的工作流程如下:
#-*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import os, time import re url = (r‘https://nba.hupu.com/‘) #获取不冷笑话在首页的位置,返回url和标题 def get_buleng_title_url(url): index_html = requests.get(url) index_html_s = BeautifulSoup(index_html.text,‘lxml‘) main_street = index_html_s.find(class_ = ‘gray-list main-stem max250‘) url_list = [] url_name_list = [] for dd in main_street.find_all(‘dd‘,limit = 5): url_list.append(dd.a.get(‘href‘)) url_name_list.append(dd.a.get_text()) return [url_list[4],url_name_list[4]] #获取不冷笑话正文中的图片列表,利用set去重 def get_pic_url(buleng_list): pic_url_list = set() buleng_html = requests.get(buleng_list[0]) buleng_html_s = BeautifulSoup(buleng_html.text,‘lxml‘) buleng_content = buleng_html_s.find(class_=‘quote-content‘) for pic_url in buleng_content.find_all(‘img‘): try: original_url = pic_url.get(‘data-original‘) pic_url_list.add(original_url.split(‘?‘)[0]) except: pic_url_list.add(pic_url.get(‘src‘)) return pic_url_list #创建以标题命名的文件夹,并返回是否创建成功 def makedir(buleng_list): path = (‘E:\\pic\\%s‘ % buleng_list[1]) if os.path.exists(path): return 0 else: os.makedirs(path) return path #获取亮贴中的图片列表,set去重 def get_comment_pic_url(buleng_list): comment_pic_url_list = set() buleng_html = requests.get(buleng_list[0]) buleng_html_s = BeautifulSoup(buleng_html.text,‘lxml‘) buleng_comment = buleng_html_s.find(id=‘readfloor‘) for floor in buleng_comment.find_all(‘table‘): for pic_url in floor.find_all(‘img‘): try: original_url = pic_url.get(‘data-original‘) comment_pic_url_list.add(original_url.split(‘?‘)[0]) except: comment_pic_url_list.add(pic_url.get(‘src‘)) return comment_pic_url_list #下载图片,可下载gif、jpg、png格式 def download_pic(pic_url_list,path,pic_from = ‘正文‘): a = 1 for url in pic_url_list : if url.endswith(‘.gif‘): pic = requests.get(url) with open((path+(‘\\%s-%s.gif‘ % (pic_from,a))),‘wb‘) as f: f.write(pic.content) f.close print(‘下载一张%s动图‘ % pic_from) a += 1 if url.endswith(‘.jpg‘): pic = requests.get(url) with open((path+(‘\\%s-%s.jpg‘ % (pic_from,a))),‘wb‘) as f: f.write(pic.content) f.close print(‘下载一张%sjpg图‘ % pic_from) a +=1 if url.endswith(‘.png‘): pic = requests.get(url) with open((path+(‘\\%s-%s.png‘ % (pic_from,a))),‘wb‘) as f: f.write(pic.content) f.close print(‘下载一张%spng图‘ % pic_from) a +=1 if __name__ == "__main__": buleng = get_buleng_title_url(url) path = makedir(buleng) if path != 0: pic_url_list = get_pic_url(buleng) comment_pic_url_list = get_comment_pic_url(buleng) download_pic(pic_url_list,path) download_pic(comment_pic_url_list,path,‘评论‘) else: print(‘目录已存在,等待虎扑更新‘)
这个程序的主要判定贴子位置的办法就是首页帖子顺序,稍微修改一下也可以爬取主干道的其他推荐热帖,代码就不放了。
爬取虎扑NBA首页主干道推荐贴的一只小爬虫,日常爬不冷笑话解闷
标签:基本 必看 突发奇想 add int lis bs4 其他 更新
原文地址:https://www.cnblogs.com/mathbox/p/9182388.html