标签:分享 system print public 技术分享 出错 catch inf 字符
众所周知,字符编码很多 像UTF-8、GBK、GB2312、ISO8859-1等等 其中GBK是兼容GB2312的
重点是UTF-8编码下的中文占3个字节,GBK、GB2312编码下的中文占2个字节,当我们把一个字符串解析为UTF-8的字节时,
如果进行了业务处理,再转为GBK那么很容易就出现了乱码,很显然两种编码中文字节占用位数都不一样,
网上很多人说GBK转UTF-8的方法如下:
//以下代码是错误的
String str="双节棍爱好友h为太原"; byte[]tem=str.getBytes("GBK"); String result=new String(tem,"UTF-8");
我可以很负责的说这个是错误的 结果是乱码 这个我已经试过 是错误的
字符串就是个对象 你用什么编码去获取字节数组,那么你将字节数组重新还原字符串的时候就用对应的编码
希望下边的代码 能给大家 带来点启发
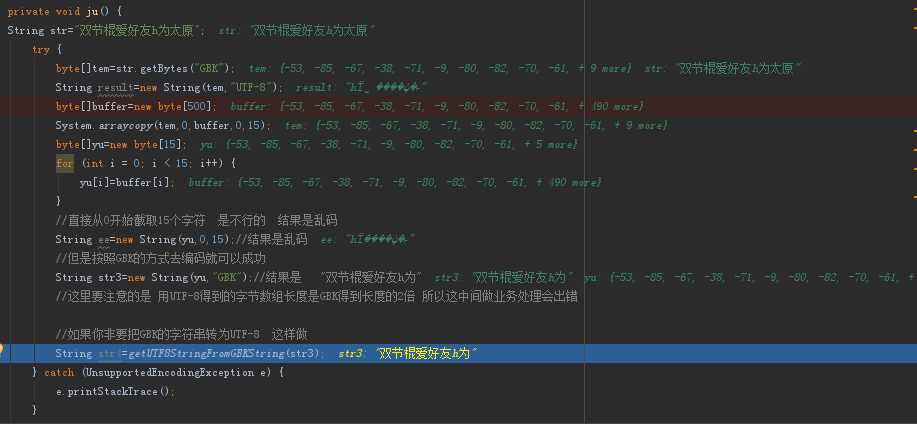
private void ju() {
String str="双节棍爱好友h为太原";
try {
byte[]tem=str.getBytes("GBK");
String result=new String(tem,"UTF-8");
byte[]buffer=new byte[500];
System.arraycopy(tem,0,buffer,0,15);
byte[]yu=new byte[15];
for (int i = 0; i < 15; i++) {
yu[i]=buffer[i];
}
//直接从0开始截取15个字符 是不行的 结果是乱码
String ee=new String(yu,0,15);//结果是乱码
//但是按照GBK的方式去编码就可以成功
String str3=new String(yu,"GBK");//结果是 "双节棍爱好友h为"
//这里要注意的是 用UTF-8得到的字节数组长度是GBK得到长度的1.5倍 所以这中间做业务处理会出错
//如果你非要把GBK的字符串转为UTF-8 这样做
String str4=getUTF8StringFromGBKString(str3);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
如果非要把GBK转为UTF-8 可以用以下方法
public static String getUTF8StringFromGBKString(String gbkStr) {
try {
return new String(getUTF8BytesFromGBKString(gbkStr), "UTF-8");
} catch (UnsupportedEncodingException e) {
throw new InternalError();
}
}
public static byte[] getUTF8BytesFromGBKString(String gbkStr) {
int n = gbkStr.length();
byte[] utfBytes = new byte[3 * n];
int k = 0;
for (int i = 0; i < n; i++) {
int m = gbkStr.charAt(i);
if (m < 128 && m >= 0) {
utfBytes[k++] = (byte) m;
continue;
}
utfBytes[k++] = (byte) (0xe0 | (m >> 12));
utfBytes[k++] = (byte) (0x80 | ((m >> 6) & 0x3f));
utfBytes[k++] = (byte) (0x80 | (m & 0x3f));
}
if (k < utfBytes.length) {
byte[] tmp = new byte[k];
System.arraycopy(utfBytes, 0, tmp, 0, k);
return tmp;
}
return utfBytes;
}
严禁盗版
转载请注明出处:https://www.cnblogs.com/bimingcong/p/9185472.html
标签:分享 system print public 技术分享 出错 catch inf 字符
原文地址:https://www.cnblogs.com/bimingcong/p/9185472.html