标签:描述 求导 这一 原因 需要 输出 增加 矩阵 tps
RNN(Recurrent Neural Networks,循环神经网络)不仅会学习当前时刻的信息,也会依赖之前的序列信息。由于其特殊的网络模型结构解决了信息保存的问题。所以RNN对处理时间序列和语言文本序列问题有独特的优势。递归神经网络都具有一连串重复神经网络模块的形式。在标准的RNNs中,这种重复模块有一种非常简单的结构。

那么S(t+1) = tanh( U*X(t+1) + W*S(t))。tanh激活函数图像如下:

RNN通过BPTT算法反向传播误差,它与BP相似,只不过与时间有关。RNN同样通过随机梯度下降(Stochastic gradient descent)算法使得代价函数(损失函数)值达到最小。


RNN的激活函数tanh可以将所有值映射到-1至1之间,以及在利用梯度下降算法调优时利用链式法则,那么会造成很多个小于1的项连乘就很快的逼近零。
依赖于我们的激活函数和网络参数,也可能会产生梯度爆炸(如激活函数是Relu,而LSTM采用的激活函数是sigmoid和tanh,从而避免了梯度爆炸的情况)。一般靠裁剪后的优化算法即可解决,比如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩)。
合适的初始化矩阵W可以减小梯度消失效应,正则化也能起作用。更好的方法是选择ReLU而不是sigmoid和tanh作为激活函数。ReLU的导数是常数值0或1,所以不可能会引起梯度消失。更通用的方案时采用长短时记忆(LSTM)或门限递归单元(GRU)结构。
那么,接下来我们来了解LSTM是如何解决梯度消失问题的
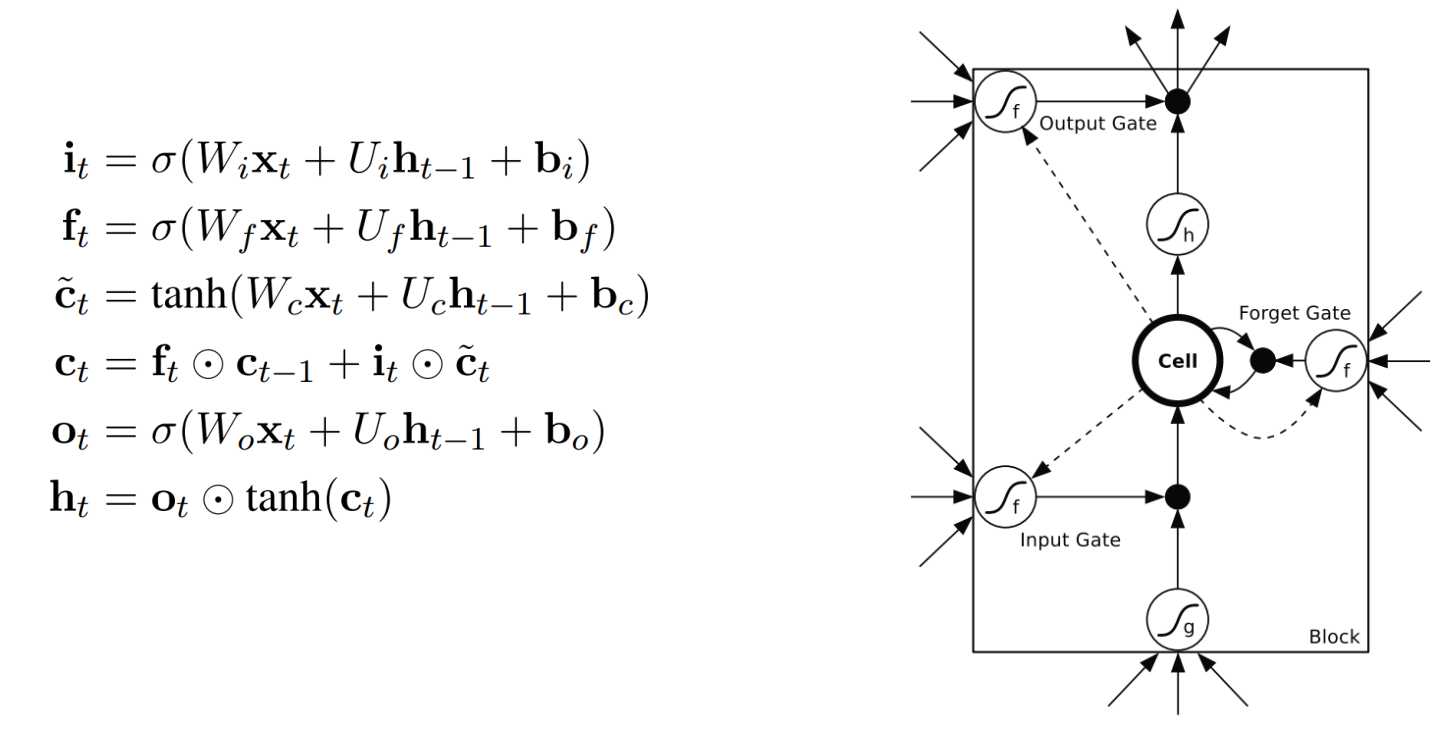
LSTM (Long Short Term Memory networks)的“门”结构可以截取“不该截取的信息”,结构如下:

LSTMs的关键点是细胞状态,就是穿过图中的水平线。
单元状态有点像是个传送带。它贯穿整个链条,只有一些线性相互作用。这很容易让信息以不变的方式向下流动。

LSTM有能力向单元状态中移除或添加信息,通过门结构来管理,包括“遗忘门”,“输出门”,“输入门”。通过门让信息选择性通过,来去除或增加信息到细胞状态. 模块中sigmoid层输出0到1之间的数字,描述了每个成分应该通过门限的程度。0表示“不让任何成分通过”,而1表示“让所有成分通过!”
第一步



表示现在的全部信息。


以确定要更新的信息,通过相加操作得到新的细胞状态Ct.

至此,我们在这里再次强调一下LSTM是如何解决长时依赖问题的:
在RNN中,当前状态值S(t)= tanh(x(t) * U + W * S(t-1)),正如上面所述在利用梯度下降算法链式求导时是连乘的形式,若其中只要有一个是接近零的,那么总体值就容易为0,导致梯度消失,不能解决长时依赖问题。
而LSTM更新状态值:

是相加的形式,所以不容易出现状态值逐渐接近0的情况。
TensorFlow(十一):递归神经网络(RNN与LSTM)
标签:描述 求导 这一 原因 需要 输出 增加 矩阵 tps
原文地址:https://www.cnblogs.com/felixwang2/p/9190656.html