标签:des style http color io os 使用 ar java
问题导读:
1.ZooKeeper的数据模型是什么 ?
2.ZooKeeper应用有哪些陷阱 ?
3.每个节点(ZNode)中存储的是什么?
4.一个ZNode维护了一个状态结构都包含了什么?
5.ZNode组成结构是什么?
6.Watches的机制是什么?
7.ZooKeeper内置了哪4种方式实现ACL?

前言
ZooKeeper
是一个开源的分布式服务框架,它是ApacheHadoop
项目的一个子项目,主要用来解决分布式应用场景中存在的一些问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置管理等,它支持Standalone
模式和分布式模式,在分布式模式下,能够为分布式应用提供高性能和可靠地协调服务,而且使用ZooKeeper
可以大大简化分布式协调服务的实现,为开发分布式应用极大地降低了成本。
总体架构
ZooKeeper分布式协调服务框架的总体架构,如图所示:
<ignore_js_op>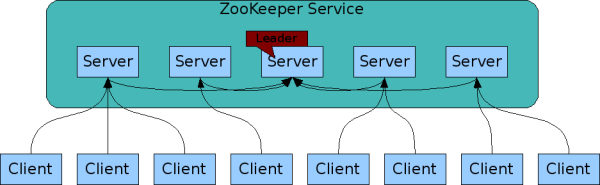
ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower。当客户端Client连接到ZooKeeper集群,并且执行写请求时,这些请求会被发送到Leader节点上,然后Leader节点上数据变更会同步到集群中其他的Follower节点。
Leader节点在接收到数据变更请求后,首先将变更写入本地磁盘,以作恢复之用。当所有的写请求持久化到磁盘以后,才会将变更应用到内存中。
ZooKeeper
使用了一种自定义的原子消息协议,在消息层的这种原子特性,保证了整个协调系统中的节点数据或状态的一致性。Follower
基于这种消息协议能够保证本地的ZooKeeper
数据与Leader
节点同步,然后基于本地的存储来独立地对外提供服务。当一个Leader
节点发生故障失效时,失败故障是快速响应的,消息层负责重新选择一个Leader
,继续作为协调服务集群的中心,处理客户端写请求,并将ZooKeeper
协调系统的数据变更同步(广播)到其他的Follower
节点。
设计要点
ZooKeeper是基于如下4个目标来进行权衡和设计的,我们从设计及其特性的角度来详细说明:
简单
分布式应用中的各个进程可以通过ZooKeeper的命名空间(Namespace)来进行协调,这个命名空间是共享的、具有层次结构的,更重要的是它的结构足够简单,像我们平时接触到的文件系统的目录结构一样容易理解,如图所示:
<ignore_js_op>
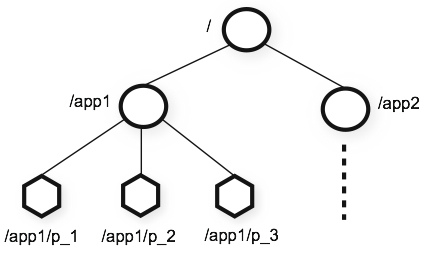
在ZooKeeper中每个命名空间(Namespace)被称为ZNode,你可以这样理解,每个ZNode包含一个路径和与之相关的元数据,以及继承自该节点的孩子列表。与传统文件系统不同的是,ZooKeeper中的数据保存在内存中,实现了分布式同步服务的高吞吐和低延迟。
在上图示例的ZooKeeper的数据模型中,有如下要点:
每个节点(ZNode)中存储的是同步相关的数据(这是ZooKeeper设计的初衷,数据量很小,大概B到KB量级),例如状态信息、配置内容、位置信息等。
一个ZNode维护了一个状态结构,该结构包括:版本号、ACL变更、时间戳。每次ZNode数据发生变化,版本号都会递增,这样客户端的读请求可以基于版本号来检索状态相关数据。
每个ZNode都有一个ACL,用来限制是否可以访问该ZNode。
在一个命名空间中,对ZNode上存储的数据执行读和写请求操作都是原子的。
客户端可以在一个ZNode
上设置一个监视器(Watch
),如果该ZNode
数据发生变更,ZooKeeper
会通知客户端,从而触发监视器中实现的逻辑的执行。
每个客户端与ZooKeeper
连接,便建立了一次会话(Session
),会话过程中,可能发生CONNECTING
、CONNECTED
和CLOSED
三种状态。
ZooKeeper支持临时节点(EphemeralNodes)的概念,它是与ZooKeeper中的会话(Session)相关的,如果连接断开,则该节点被删除。
冗余
ZooKeeper
被设计为复制集群架构,每个节点的数据都可以在集群中复制传播,使集群中的每个节点数据同步一致,从而达到服务的可靠性和可用性。前面说到,ZooKeeper
将数据放在内存中来提高性能,为了避免发生单点故障(SPOF
),支持数据的复制来达到冗余存储,这是必不可少的。
有序
ZooKeeper使用时间戳来记录导致状态变更的事务性操作,也就是说,一组事务通过时间戳来保证有序性。基于这一特性。ZooKeeper可以实现更加高级的抽象操作,如同步等。
快速
ZooKeeper包括读写两种操作,基于ZooKeeper的分布式应用,如果是读多写少的应用场景(读写比例大约是10:1),那么读性能更能够体现出高效。
数据模型
ZooKeeper有一个分层的命名空间,结构类似文件系统的目录结构,非常简单而直观。其中,ZNode是最重要的概念,前面我们已经描述过。另外,有ZNode有关的还包括Watches、ACL、临时节点、序列节点(Sequence Node)。
ZNode结构
ZooKeeper中使用Zxid(ZooKeeperTransaction Id)来表示每次节点数据变更,一个Zxid与一个时间戳对应,所以多个不同的变更对应的事务是有序的。下面是ZNode的组成结构,引用文档如下所示:
czxid – The zxid of the change that causedthis znode to be created.
mzxid – The zxid of the change that lastmodified this znode.
ctime – The time in milliseconds from epochwhen this znode was created.
mtime – The time in milliseconds from epochwhen this znode was last modified.
version – The number of changes to the dataof this znode.
cversion – The number of changes to thechildren of this znode.
aversion – The number of changes to the ACLof this znode.
ephemeralOwner – The session id of theowner of this znode if the znode is an ephemeral node. If it is not anephemeral node, it will be zero.
dataLength – The length of the data fieldof this znode.
numChildren – The number of children ofthis znode.
Watches(监视)
ZooKeeper中的Watch是只能触发一次。也就是说,如果客户端在指定的ZNode设置了Watch,如果该ZNode数据发生变更,ZooKeeper会发送一个变更通知给客户端,同时触发设置的Watch事件。如果ZNode数据又发生了变更,客户端在收到第一次通知后没有重新设置该ZNode的Watch,则ZooKeeper就不会发送一个变更通知给客户端。
ZooKeeper异步通知设置Watch的客户端。但是ZooKeeper能够保证在ZNode的变更生效之后才会异步地通知客户端,然后客户端才能够看到ZNode的数据变更。由于网络延迟,多个客户端可能会在不同的时间看到ZNode数据的变更,但是看到变更的顺序是能够保证有序一致的。
ZNode可以设置两类Watch,一个是DataWatches(该ZNode的数据变更导致触发Watch事件),另一个是Child Watches(该ZNode的孩子节点发生变更导致触发Watch事件)。调用getData()和exists() 方法可以设置Data Watches,调用getChildren()方法可以设置Child Watches。调用setData()方法触发在该ZNode的注册的Data Watches。调用create()方法创建一个ZNode,将触发该ZNode的Data Watches;调用create()方法创建ZNode的孩子节点,则触发ZNode的Child Watches。调用delete()方法删除ZNode,则同时触发Data Watches和Child Watches,如果该被删除的ZNode还有父节点,则父节点触发一个Child Watches。
另外,如果客户端与ZooKeeper Server
断开连接,客户端就无法触发Watches
,除非再次与ZooKeeper Server
建立连接。
Sequence Nodes(序列节点)
在创建ZNode的时候,可以请求ZooKeeper生成序列,以路径名为前缀,计数器紧接在路径名后面,例如,会生成类似如下形式序列
qn-0000000001, qn-0000000002,qn-0000000003, qn-0000000004, qn-0000000005, qn-0000000006, qn-0000000007
对于ZNode
的父节点来说,序列中的每个计数器字符串都是唯一的,最大值为2147483647
。
ACLs(访问控制列表)
ACL可以控制访问ZooKeeper的节点,只能应用于特定的ZNode上,而不能应用于该ZNode的所有孩子节点上。它主要有如下五种权限:
CREATE 允许创建Child Nodes
READ 允许获取ZNode的数据,以及该节点的孩子列表
WRITE 可以修改ZNode的数据
DELETE 可以删除一个孩子节点
ADMIN 可以设置权限
ZooKeeper内置了4种方式实现ACL:
world 一个单独的ID,表示任何人都可以访问
auth 不使用ID,只有认证的用户可以访问
digest 使用username:password生成MD5哈希值作为认证ID
ip 使用客户端主机IP地址来进行认证
ZooKeeper Session
当客户端连接到ZooKeeper集群时,建立了会话。会话过程中的状态变迁,如图所示:
<ignore_js_op>
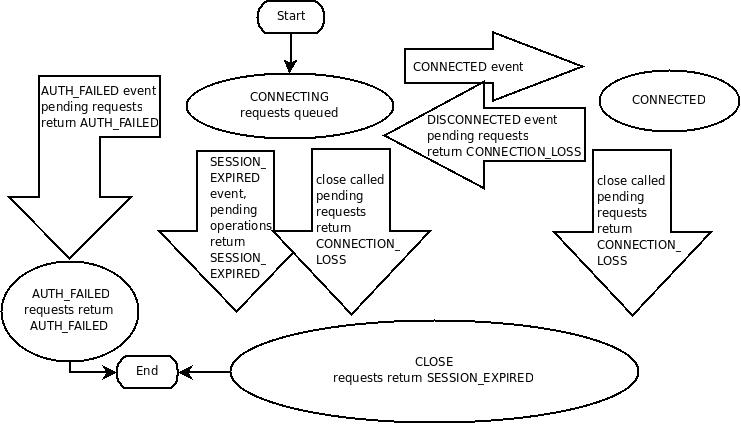
建立连接过程中,会话状态为CONNECTING;当连接建立成功后,会话状态变为CONNECTED。会话过程中,如果正常的话,会话的状态只能是CONNECTING和CONNECTED二者之一。如果在会话过程中连接断开,则变为CLOSED状态。
应用陷阱
并非任何分布式应用都适合使用ZooKeeper来构建协调服务,我们根据ZooKeeper提供的文档,给出哪些情况下使用会出现问题,又是如何应对这种问题的。总结如下:
丢失ZNode上的变更通知
客户端连接到ZooKeeper Server以后,会维护一个TCP连接。在CONNECTED状态下,客户端设置了某个ZNode的Watch监听器,可以收到来自该节点变更的通知(后续会触发一定的逻辑执行流程)。但是,如果由于网络异常,客户端断开了与ZooKeeper Server的连接,在断开的过程中,是无法收到ZooKeeper在ZNode上发送的节点数据变更通知的。
所以,如果使用ZooKeeper的Watch,必须要寻找保持CONNECTED的Watch,才能保证不会丢失该Watch监控的ZNode上的数据变更通知。
无效ZooKeeper集群节点列表
与ZooKeeper
集群交互时,一般情况下客户端会持有一个ZooKeeper
集群节点的列表,或者列表的子集,那么会存在如下两种情况:
一种情况是,如果客户端持有的列表或者列表子集,其中节点都处于Active状态,能够提供协调服务,那么客户端访问ZooKeeper集群没有任何问题。
另一种情况,客户端持有ZooKeeper集群节点列表或列表子集,如果列表中的某些节点因为故障退出了集群,如果客户端再次连接这一类失效的节点,就无法获取服务。
所以,我们在应用中使用ZooKeeper集群时,一定要明确这一点,或者跳过无效的节点,或者重新寻找有效的节点继续业务处理,或者检查ZooKeeper集群,使整个集群恢复正常。
配置导致的性能问题
如果设置Java堆内存(Heap)不合理,会导致ZooKeeper内存不足,会在内存与文件系统之间进行数据交换,导致ZooKeeper的性能极大地下降,从而可能会影响应用程序。
为了避免Swapping问题的出现,主要考虑设置足够的Java堆内存,同时减少被操作系统和Cache使用的内存,尽量避免在内存与文件系统之间发生数据交换,或者可以将交换限制在一定的范围之内。
事务日志存储设备性能
ZooKeeper
会同步事务到存储设备,如果存储设备不是专用的,而是和其他I/O
密集型应用共享同一磁盘,会导致ZooKeeper
的效率。因为客户端请求ZNode
数据变更而发生的事务,ZooKeeper
会在响应之前将事务日志写入存储设备,如果存储设备是专用的,那么整个服务以至外部应用都会获得极大地性能提升。
ZNode存储大量数据导致性能问题
ZooKeeper的设计初衷是,每个ZNode只存放少量的同步数据,如果存储了大量数据,导致ZooKeeper每次节点发生变更时需要将事务写入存储设备,同时还要在集群内部复制传播,这将导致不可避免的延迟和性能问题。
所以,如果需要与大量的数据相关,可以将大量数据存储在其他设备中,而只是在ZooKeeper
中存储一个简单的映射,如指针、引用等等。
文章转自:http://www.aboutyun.com/thread-7731-1-1.html
ZooKeeper架构设计及其应用要点
标签:des style http color io os 使用 ar java
原文地址:http://www.cnblogs.com/likehua/p/3999610.html