标签:树莓派 data nis log form 展示 tar .com mbg
前言:
前段时间我在树莓派上通过KNN,SVM等机器学习的算法实现了门派识别的项目,所用到的数据集是经典的MNIST。可能是因为手写数字与印刷体存在一些区别,识别率并是很不高。基于这样的情况,我打算在PC端用CNN试一试MNIST上的识别率。
正文:
一张图展示CNN
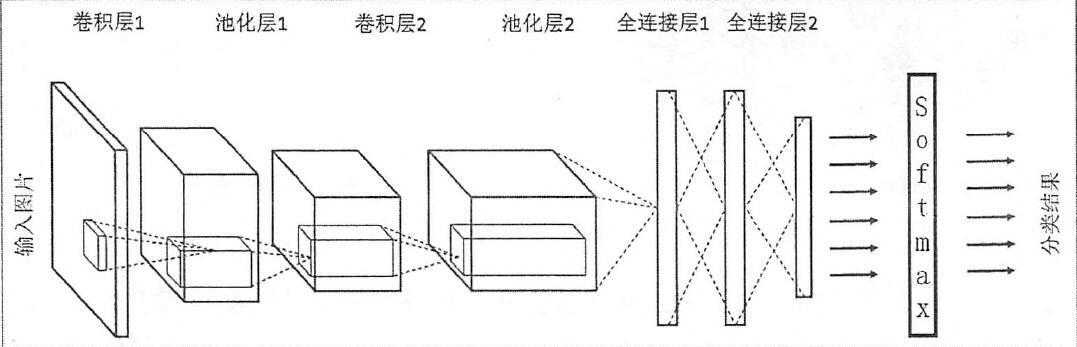
导入基础包
import tensorflow as tf from sklearn.datasets import load_digits import numpy as np
导入数据集
digits = load_digits() X_data = digits.data.astype(np.float32) Y_data = digits.target.astype(np.float32).reshape(-1,1)
预处理
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X_data = scaler.fit_transform(X_data) from sklearn.preprocessing import OneHotEncoder Y = OneHotEncoder().fit_transform(Y_data).todense() X = X_data.reshape(-1,8,8,1)
MinMaxScaler(将数据归一化)
公式:X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) ;
X_scaler = X_std/ (max - min) + min
OneHotEncoder(将数据二值化)
MBGD(小批量梯度下降)
batch_size = 8 def generatebatch(X,Y,n_examples, batch_size): for batch_i in range(n_examples // batch_size): start = batch_i*batch_size end = start + batch_size batch_xs = X[start:end] batch_ys = Y[start:end] yield batch_xs, batch_ys
输入层
tf.reset_default_graph() tf_X = tf.placeholder(tf.float32,[None,8,8,1]) tf_Y = tf.placeholder(tf.float32,[None,10]
卷积,激活和池化层
conv_filter_w1 = tf.Variable(tf.random_normal([3, 3, 1, 10])) conv_filter_b1 = tf.Variable(tf.random_normal([10])) relu_feature_maps1 = tf.nn.relu( tf.nn.conv2d(tf_X, conv_filter_w1,strides=[1, 1, 1, 1], padding=‘SAME‘) + conv_filter_b1)
max_pool1 = tf.nn.max_pool(relu_feature_maps1,ksize=[1,3,3,1],strides=[1,2,2,1],padding=‘SAME‘)
[3,3,1,10]前2个参数是卷积核大小,第三个是通道数,第四个是卷积核数量
strides是卷积的滑动步长
padding是图像边缘的填充方式,
’SAME‘不够核大小的填充0
‘VALID‘不够核大小的丢弃
[1,3,3,1]首尾2个参数常为1,保证不在batch和channels上做池化,中间2参数是池化窗口大小
再卷积一次
conv_filter_w2 = tf.Variable(tf.random_normal([3, 3, 10, 5])) conv_filter_b2 = tf.Variable(tf.random_normal([5])) conv_out2 = tf.nn.conv2d(relu_feature_maps1, conv_filter_w2,strides=[1, 2, 2, 1], padding=‘SAME‘) + conv_filter_b2
BN归一化+激活层
batch_mean, batch_var = tf.nn.moments(conv_out2, [0, 1, 2], keep_dims=True) shift = tf.Variable(tf.zeros([5])) scale = tf.Variable(tf.ones([5])) epsilon = 1e-3 BN_out = tf.nn.batch_normalization(conv_out2, batch_mean, batch_var, shift, scale, epsilon)
池化层
max_pool2 = tf.nn.max_pool(relu_BN_maps2,ksize=[1,3,3,1],strides=[1,2,2,1],padding=‘SAME‘)
展开特征
max_pool2_flat = tf.reshape(max_pool2, [-1, 2*2*5])
全连接层
fc_w1 = tf.Variable(tf.random_normal([2*2*5,50])) fc_b1 = tf.Variable(tf.random_normal([50])) fc_out1 = tf.nn.relu(tf.matmul(max_pool2_flat, fc_w1) + fc_b1)
输出层
out_w1 = tf.Variable(tf.random_normal([50,10])) out_b1 = tf.Variable(tf.random_normal([10])) pred = tf.nn.softmax(tf.matmul(fc_out1,out_w1)+out_b1)
损失函数
loss = -tf.reduce_mean(tf_Y*tf.log(tf.clip_by_value(pred,1e-11,1.0)))
训练(迭代1000个周期)
train_step = tf.train.AdamOptimizer(1e-3).minimize(loss) y_pred = tf.arg_max(pred,1) bool_pred = tf.equal(tf.arg_max(tf_Y,1),y_pred) accuracy = tf.reduce_mean(tf.cast(bool_pred,tf.float32)) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for epoch in range(1000): for batch_xs,batch_ys in generatebatch(X,Y,Y.shape[0],batch_size): sess.run(train_step,feed_dict={tf_X:batch_xs,tf_Y:batch_ys}) if(epoch%100==0): res = sess.run(accuracy,feed_dict={tf_X:X,tf_Y:Y}) print (epoch,res) res_ypred = y_pred.eval(feed_dict={tf_X:X,tf_Y:Y}).flatten() print (res_ypred)
大功告成(ノ?`?′?)ノ︵
训练的最终结果在0.998附近
彩蛋:
现在正直世界杯,在端午节期间写下这篇随笔(′-ω-`)
未来暑假将写2篇关于faster RCNN 和 Mask RCNN的随笔(? ??_??)?
标签:树莓派 data nis log form 展示 tar .com mbg
原文地址:https://www.cnblogs.com/zhabendejqxx/p/9192569.html