标签:根据 roc 转换 ORC 一个 文件中 文本 txt 很多
在读取和处理图像、图像相关的机器学习以及创建图像等任务中,Python 一直都是非常出色的语言。虽然有很多库可以进行图像处理,在这里只重点介绍:Tesseract
Tesseract 是一个 OCR 库,目前由 Google 赞助(Google 也是一家以 OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源 OCR 系统。 除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体,也可以识别出任何 Unicode 字符。
你要处理的大多数文字都是比较干净、格式规范的。格式规范的文字通常可以满足一些需求,不过究竟什么是“格式混乱”,什么算“格式规范”,确实因人而异。 通常,格式规范的文字具有以下特点:
文字的一些格式问题在图片预处理时可以进行解决。例如,可以把图片转换成灰度图,调 整亮度和对比度,还可以根据需要进行裁剪和旋转(详情请关注图像与信号处理),但是,这些做法在进行更具扩展性的 训练时会遇到一些限制。

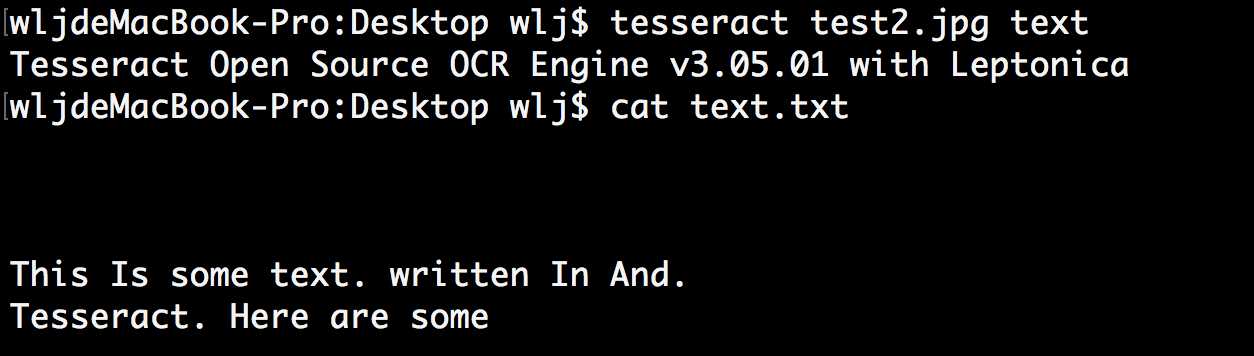
通过下面的命令运行 Tesseract,读取文件并把结果写到一个文本文件中: tesseract test.jpg text
cat text.txt 即可显示结果。

1 wljdeMacBook-Pro:Desktop wlj$ tesseract test.jpg text 2 Tesseract Open Source OCR Engine v3.05.01 with Leptonica 3 wljdeMacBook-Pro:Desktop wlj$ cat text.txt 4 This is some text, written in Arial, that will be read by 5 Tesseract. Here are some symbols: !@#$%"&*()
识别结果很准确,不过符号^分别被表示成了双引号。大体上可以让你很舒服地阅读。
1 import pytesseract 2 from PIL import Image 3 4 image = Image.open(‘test.jpg‘) 5 text = pytesseract.image_to_string(image) 6 print text
运行结果一样。
很多时候我们在网上会看到这样的图片:
Tesseract 不能完整处理这个图片,主要是因为图片背景色是渐变的,最终结果是这样:
随着背景色从左到右不断加深,文字变得越来越难以识别,Tesseract 识别出的 每一行的最后几个字符都是错的。
遇到这类问题,可以先用 Python 脚本对图片进行清理。利用 Pillow 库,我们可以创建一个 阈值过滤器来去掉渐变的背景色,只把文字留下来,从而让图片更加清晰,便于 Tesseract 读取:

除了一些标点符号不太清晰或丢失了,大部分文字都被读出来了。Tesseract 给出了最好的 结果:
This IS some text. written In Arial. that will be ,
Tesseract Here are some symbols: IW“ ’
图形验证码识别:

1 import tesserocr 2 from PIL import Image 3 4 image = Image.open(‘code.jpg‘) 5 result = tesserocr.image_to_text(image) 6 print(result)
在这里我们新建了一个Image对象,调用了tesserocr的image_to_text()方法。传入该Image对象即可完成识别,实现过程非常简单,结果如下所示:
JR42
另外,tesserocr有个更加简单的方法,这个方法可以直接将图片文件转为字符串,代码如下所示:
1 import tesserocr 2 3 print(tesserocr.file_to_text(‘code.jpg‘))
结果为:
.ll?42
此方法是别效果不如上一种方法好。
验证码处理

重新用如下代码测试:
1 import tesserocr 2 from PIL import Image 3 4 image = Image.open(‘code2.jpg‘) 5 result = tesserocr.image_to_text(image) 6 print(result)
输出结果为:
FFKT
这次是别与实际结果有偏差,这是因为验证码内的多余线条干扰了图片的识别。
对于这种情况,我们还需要做一些处理,如转灰度,二值化处理等操作。
我们可以利用Image对象的convert()方法参数传入L,即可将图像转化为灰度图像,代码如下所示:
1 image = image.convert(‘L‘) 2 image.show()
传入1即可将图片进行二值化处理,如下所示:
1 image = image.convert(‘1‘) 2 image.show()
我们还可以指定二值化的阈值,上面的方法采用的是默认阈值127。不过我们不能直接转化原图,要将原图先转化为灰度图像,然后再指定二值化阈值。代码如下:
1 import tesserocr 2 from PIL import Image 3 4 image = Image.open(‘code2.jpg‘) 5 6 image = image.convert(‘L‘) 7 threshold = 127 8 table = [] 9 for i in range(256): 10 if i < threshold: 11 table.append(0) 12 else: 13 table.append(1) 14 15 image = image.point(table, ‘1‘) 16 image.show() 17 18 result = tesserocr.image_to_text(image) 19 print(result)

这里threshold代表二值化阈值,图片验证码黑白分明,识别结果:
PFRT
标签:根据 roc 转换 ORC 一个 文件中 文本 txt 很多
原文地址:https://www.cnblogs.com/wanglinjie/p/9193897.html