标签:很多 目标 自动化测试 自动弹出 font 脚本 关闭 输入 ati
Selenium 的使用
在前面了解到,有些页面是直接由HTML代码组成的,有些网站则是通过Ajax技术局部刷新而渲染出新的局部,对于后者,我们可以通过分析Ajax请求返回的结果从中提取我们需要的数据,但是该方法并不适用于所有网站,因为有些网站的Ajax接口含有很多加密参数,我们无法直接找到规律;有些网站是直接用JavaScript计算后生成的,面对这样的问题,我们无法再通过分析Ajax去抓取数据了。为了解决这些问题,我们可以直接使用模拟浏览器运行的方式来实现,这样就可以做到在浏览器中看到什么,抓取的源码就是什么,也就是可见即可爬。Python提供了很多模拟浏览器运行的库,如 Selenium 、Splash、 PyV8、Ghost等,下面就来详细介绍 Selenium。
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,比如点击、下拉等,同时还可以获取浏览器当前呈现的页面的源代码,这就实现了可见即可爬了。废话不多说,下面来看 Selenium 的简单使用:
1 from selenium import webdriver 2 from selenium.webdriver.common.by import By 3 from selenium.webdriver.common.keys import Keys 4 from selenium.webdriver.support import expected_conditions as EC 5 from selenium.webdriver.support.wait import WebDriverWait 6 7 8 browser = webdriver.Chrome() 9 try: 10 browser.get(‘https://www.baidu.com‘) 11 input = browser.find_element_by_id(‘kw‘) 12 input.send_keys(‘python‘) 13 input.send_keys(Keys.ENTER) 14 wait = WebDriverWait(browser,10) 15 wait.until(EC.presence_of_element_located((By.ID,‘content_left‘))) 16 print(browser.current_url) 17 print(browser.get_cookies()) 18 print(browser.page_source) 19 finally: 20 browser.close()
运行上面的脚本后会发现自动弹出Chrome浏览器,浏览器首先自动跳转到百度,然后在搜素框中输入python,接着按下回车键进行搜索。最终控制台会输出当前的URL,Cookies和网页源码。除了Chrome浏览器以外,Selenium还支持很多浏览器,具体的使用基本一致,唯独在创建浏览器实例时有所区别:
1 from selenium import webdriver 2 3 browser = webdriver.Chrome() 4 browser = webdriver.Firefox() 5 browser = webdriver.Edge() 6 browser = webdriver.PhantomJS() 7 browser = webdriver.Safari()
(注:在使用PhantomJS时会有这么提示就是selenium会逐渐不支持PhantomJS)
这样就完成了浏览器对象的初始化,接下来要做的就是调用browser对象的属性和方法操作浏览器了。下面就来详细介绍常用的操作:
1. 访问页面
细心的你可能在前面的实例中也发现如何操作browser对象让其访问浏览器,就是直接调用get()方法,参数传入URL,比如这里访问京东:
1 from selenium import webdriver 2 3 4 browser = webdriver.Chrome() 5 browser.get(‘https://3.cn‘) 6 print(browser.page_source) 7 browser.close()
运行后发现,弹出了Chrome浏览器访问了京东(3.cn是京东的一个域名),然后控制台直接输出了京东的页面源代码,随后关闭浏览器。
2. 查找节点
Selenium 可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如需要向某个输入框输入文字的操作,这时候就需要知道这个输入框在哪里吧,而 Selenium 提供了一系列查找节点的方法。
比如:想要从淘宝页面中提取搜索框节点。
1 from selenium import webdriver 2 3 4 browser = webdriver.Chrome() 5 browser.get(‘https://www.taobao.com‘) 6 input_first = browser.find_element_by_id(‘q‘) 7 input_second = browser.find_element_by_css_selector(‘#q‘) 8 input_third = browser.find_element_by_xpath(‘//*[@id="q"]‘) 9 print(input_first,input_second,input_third) 10 browser.close()
这里列出所有获取单个节点的方法:
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_class_name()
find_element_by_css_selector()
find_element_by_tag_name()
find_element(查找方式,value)
例如:find_element(By.ID,value)
以上方法只能获取到一个节点,如果需要获取多个,则需要使用下面的方法:
find_elements_by_xpath()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
find_elements()
3. 节点交互
Selenium 可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的有:输入文字使用 send_key()方法,清空文字使用 clear()方法,点击按钮使用 click()方法。示例如下:
1 from selenium import webdriver 2 import time 3 4 5 browser = webdriver.Chrome() 6 browser.get(‘https://www.taobao.com‘) 7 input = browser.find_element_by_id(‘q‘) 8 input.send_keys(‘ipad‘) 9 time.sleep(1) 10 input.clear() 11 input.send_keys(‘iPhone‘) 12 button = browser.find_element_by_class_name(‘btn-search‘) 13 button.click() 14 browser.close()
首先驱动浏览器打开淘宝,用find_element_by_id()方法获取输入框,然后用send_keys()方法输入ipad,等待一秒后将输入框清空,再次调用send_keys()方法输入iPhone,完了获取搜索按钮最后调用click()方法完成搜索动作。
4. 动作链
在上面示例中,一些交互动作都是针对某个节点执行的,比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法等等。其实,还有另外一些操作,他们没有特定的执行对象,不如鼠标拖拽,键盘按键等等,这些动作用另外一种方式来执行,这就是动作链。
示例:实现一个节点的拖拽操作,将某个节点从一处拖拽到另外一处。
1 from selenium import webdriver 2 from selenium.webdriver import ActionChains 3 4 5 browser = webdriver.Chrome() 6 url = ‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘ 7 browser.get(url) 8 browser.switch_to.frame(‘iframeResult‘) 9 source = browser.find_element_by_css_selector(‘#draggable‘) 10 target = browser.find_element_by_css_selector(‘#droppable‘) 11 actions = ActionChains(browser) 12 actions.drag_and_drop(source,target) 13 actions.perform()
首先,打开网页中的一个拖拽实例,然后依次选中要拖拽的节点和拖拽到的目标节点,接着声明ActionChains对象并将其赋值为actions,然后通过actions调用drag_and_drop()方法,再调用perform()方法执行动作,此时就完成了拖拽操作了。
当然,Selenium 的API并没有提供所有的方法,比如下拉进度条等,对于这些方法,我们可以自己定义,通过浏览器对象的execute(js字符串)方法来进行操作。
5. 获取节点信息
在最开始的实例中,通过page_source属性可以获取网页的源代码,接着就可以使用解析库来提取信息了。但是,既然Selenium已经提供了选择节点的方法(返回的是WebElement类型),那么它也有相关的方法和属性来直接提取节点信息,如文本、属性等等。这样的话我们就不用通过解析源码来提取信息了。
5.1 获取属性
通过get_attribute()方法可以获取节点的属性,但前提是先选中这个节点:
1 from selenium import webdriver 2 3 4 browser = webdriver.Chrome() 5 browser.get(‘https://www.zhihu.com/explore‘) 6 logo = browser.find_element_by_id(‘zh-top-link-logo‘) 7 print(logo) 8 print(logo.get_attribute(‘class‘)) 9 browser.close()
通过get_attribute()方法,然后传入想要的属性名,就可以拿到它的值了。
5.2 获取文本
每个WebElement节点都有text属性,直接调用这个属性就可以得到节点内部的文本信息了,这相当于Beautiful Soup 的get_text()方法,pyquery的text()方法。
1 from selenium import webdriver 2 3 4 browser = webdriver.Chrome() 5 url = ‘https://www.zhihu.com/explore‘ 6 browser.get(url) 7 input = browser.find_element_by_class_name(‘zu-top-add-question‘) 8 print(input.text) 9 browser.close()
这里打开了知乎页面,然后获取了‘提问’按钮这个节点,然后将节点的文本内容输出。
5.3 获取id、位置、标签名和大小
除了上面提到的,WebElement还有其他属性,比如id属性可以获取节点的id,location属性可以获取该节点在页面中的相对位置,tag_name属性可以获取标签名称,size属性可以获取节点的大小,也就是宽高。
1 from selenium import webdriver 2 3 4 browser = webdriver.Chrome() 5 url = ‘https://www.zhihu.com/explore‘ 6 browser.get(url) 7 input = browser.find_element_by_class_name(‘zu-top-add-question‘) 8 print(input.id) 9 print(input.location) 10 print(input.tag_name) 11 print(input.size) 12 browser.close()
6. 切换 Frame
了解过HTML的可能会知道网页中有一种节点叫iframe,也就是字Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium打开页面后,它默认是在父级Frame里面操作,而此时如果页面中还有子Frame,它是不能获取到子Frame里面的节点的,这时就需要使用switch_to.frame()方法来切换Frame。
1 from selenium import webdriver 2 from selenium.common.exceptions import NoSuchElementException 3 4 5 browser = webdriver.Chrome() 6 url = ‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘ 7 browser.get(url) 8 browser.switch_to.frame(‘iframeResult‘) 9 try: 10 logo = browser.find_element_by_class_name(‘logo‘) 11 except NoSuchElementException: 12 print(‘NO LOGO‘) 13 browser.switch_to.parent_frame() 14 logo = browser.find_element_by_class_name(‘logo‘) 15 print(logo) 16 print(logo.text) 17 browser.close()
首先通过switch_to.frame()方法切换到子Frame里面,然后尝试获取父级Frame里面的logo节点(结果就是找不到的),如果找不到,就会抛出NoSuchElementException异常,异常捕获以后就输出NO LOGO。接着,重新切换到父级Frame,然后再次获取节点,发现此时就可以成功捕获了。所以,当页面中包含Frame时,如果想获取子Frame中的节点,需要先调用switch_to.frame()方法切换到对应的Frame,然后再进行操作。
7. 延时等待
在Selenium中,get()方法会在网页框架加载结束后结束执行,此时如果获取page_source,可能并不是浏览器完全加载完成的页面,如果某些页面额外的Ajax请求,我们在网页源代码中也不一定能成功获取到,所以,这里需要延时等待一定时间,确保节点已经加载出来。这里的等待有两种方式,分别是隐式等待和显式等待。
当使用隐式等待执行测试的时候,如果Selenium没有在DOM中找到节点,将继续等待,超出设定时间后,则抛出找不到节点异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认的时间是0,示例如下:
1 from selenium import webdriver 2 3 4 browser = webdriver.Chrome() 5 browser.implicitly_wait(10) 6 browser.get(‘https://www.zhihu.com/explore‘) 7 input = browser.find_element_by_class_name(‘zu-top-add-question‘) 8 print(input)
这里使用 implicitly_wait()方法实现了隐式等待。
隐式等待的效果其实并没有那么好,因为我们只规定了一个固定的时间,而页面的加载时间会受到网络条件的影响。更合适的方法应该是显示等待,它指定要查找的节点,然后指定一个最长等待时间,如果在规定时间内加载出来了这个节点,就返回查找节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。
1 from selenium import webdriver 2 from selenium.webdriver.common.by import By 3 from selenium.webdriver.support.ui import WebDriverWait 4 from selenium.webdriver.support import expected_conditions as EC 5 6 7 browser = webdriver.Chrome() 8 browser.get(‘https://www.taobao.com‘) 9 wait = WebDriverWait(browser,10) 10 input = wait.until(EC.presence_of_element_located((By.ID,‘q‘))) 11 button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,‘.btn-search‘))) 12 print(input,button)
首先引入了WebDriverWait这个对象,指定最长等待时间,然后调用它的until()方法,传入要等待条件expected_conditions,比如,这里传入了presence_of_element_located这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是ID为q的节点搜索框。这样可以做到的效果是,在10秒内如果ID为q的节点成功加载出来,就返回该节点;如果超过10秒还没有加载出来,就抛出异常。对于按钮,可以更改一下等待条件,比如改为element_to_be_clickable,也就是可点击,所以查找按钮时查找CSS选择器为.btn-search的按钮,如果10秒内它是可点击的,也就是成功加载出来了,就返回这个节点,如果超过10秒还是不可点击的,也就是没有加载出来,那么就抛出异常。关于等待条件,其实还有很多,比如判断标题内容等等,以下列出了一部分等待条件:
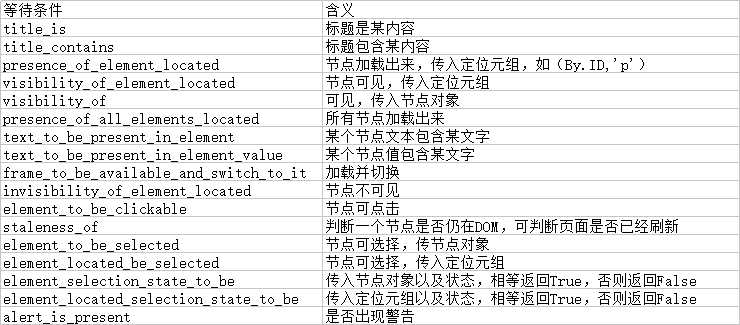
8. 前进和后退
我们平时使用的浏览器都有前进和后退的功能,Selenium 也可以完成这个操作,它使用 back() 方法后退,使用 forward() 方法前进。示例如下:
import time from selenium import webdriver browser = webdriver.Chrome() browser.get(‘https://www.baidu.com‘) browser.get(‘https://www.taobao.com‘) browser.get(‘https://www.python.org‘) browser.back() time.sleep(1) browser.forward() browser.close()
9. Cookies
使用Selenium还可以更方便的操作Cookies,例如获取,添加,删除等,示例如下:
1 from selenium import webdriver 2 3 4 browser = webdriver.Chrome() 5 browser.get(‘https://www.zhihu.com/explore‘) 6 print(browser.get_cookies()) 7 browser.add_cookie({‘name‘:‘jonas‘,‘domain‘:‘www.zhihu.com‘,‘value‘:‘germey‘}) 8 print(browser.get_cookies()) 9 browser.delete_all_cookies() 10 print(browser.get_cookies())
首先,我们访问了知乎,加载完成后,浏览器实际上已经生成了Cookies了,接着,调用get_cookies()方法获取所有Cookies。然后,通过add_cookie()方法添加一个Cookies,这里传入字典即可。接下来,再次获取所有的Cookies,此时可以发现我们刚刚添加的就在最后面。最后调用delete_all_cookies()方法删除所有Cookies,再获取时发现结果就为空了。
10. 异常处理
在使用 Selenium 的过程中,难免会遇到一些异常,例如超时、节点没有找到等错误,一旦出现此类错误,程序便不会继续运行了,下面主要介绍比较常见的异常:
1 from selenium import webdriver 2 from selenium.common.exceptions import TimeoutException,NoSuchElementException 3 4 5 browser = webdriver.Chrome() 6 try: 7 browser.get(‘https://www.baidu.com‘) 8 except TimeoutException: 9 print(‘Time Out‘) 10 try: 11 browser.find_element_by_id(‘hello‘) 12 except NoSuchElementException: 13 print(‘No Element‘) 14 finally: 15 browser.close()
也许你从异常的名称也可以知道TimeoutException是超时异常,NoSuchElementException是找不到节点的异常。
标签:很多 目标 自动化测试 自动弹出 font 脚本 关闭 输入 ati
原文地址:https://www.cnblogs.com/jonas-von/p/9205370.html