标签:分析 32bit 远程 str 网络环境 c中 遇到 copy www.
rsync作为一个简便的同步工具,在linux环境中应用较多。能够实现比较简单的文件或目录传输。至于配置相关部分这里不做过多的讲解。+++++++++++++++++++++++++++++++++++++++++++++++
这里说下rsync大文件时遇到的传输慢的问题,以及应该如何合理的解决这个问题。
现实场景如下,线上环境中需要同步一个15G的文件,服务器都是千兆网卡,正常同步也就150s左右。但是线上环境中同步有时候需要一个多小时,让人很崩溃。
分析过程:开始怀疑网络问题,查了网络环境 以及使用nc传输文件都没有问题,基本都在150s左右传输完成。也就考虑是同步软件rsync的导致慢。
然后找了下rsync的传输校验核心算法,大致扫了一遍,基本懂了。
问题原因:简单描述为:根据rsync传输原理,rsync传输文件是利用查找文件中不同的数据块进行传输(减少数控传输)。rsync校验已经存在的文件与原文件的差别,然后更新耗时较久。更为具体的参见详解 rsync传输算法。
解决办法1 :rsync忽略校验,直接传输覆盖,rsync --help 可以看到有这么个参数: -W, --whole-file copy files whole (without delta-xfer algorithm) 使用该参数。
该参数的优点节省时间不进行校验,直接覆盖本地或者远程文件。缺点,比较消耗带宽。
解决办法2 : 使用 nc 或者其他的传输方式,跳过校验。具体如何操作,参见。。 行我简单写一个吧:源: #nc -l 1.1.1.1 999 < bigfile 目的: #nc 1.1.1.1 999 > bigfile
优缺点,参见解决办法1 ,有利有弊。
+++++++++++++++++++++++++++++++++++++++++++++++
亲身实测有效:
图1 将文件删除,模拟初次同步,本地无文件,不需要进行校验,2分多同步完成。

图2 服务器带宽情况:

图3 模拟遇到的问题,将文件倒叙,制造文件更新的假象。然后同步,可以看到同步进行了57分钟。

图4 服务器网卡上流量远低于千兆:

图 5 模拟遇到的问题,将文件倒叙,制造文件更新的假象。跳过校验同步:

带宽不想贴了 参照图 2
+++++++++++++++++++++++++++++++++++++++++++
rsync的算法如下:(假设我们同步源文件名为fileSrc,同步目的文件叫fileDst)
1)分块Checksum算法。首先,我们会把fileDst的文件平均切分成若干个小块,比如每块512个字节(最后一块会小于这个数),然后对每块计算两个checksum,
一个叫rolling checksum,是弱checksum,32位的checksum,其使用的是Mark Adler发明的adler-32算法,
另一个是强checksum,128位的,以前用md4,现在用md5 hash算法。
为什么要这样?因为若干年前的硬件上跑md4的算法太慢了,所以,我们需要一个快算法来鉴别文件块的不同,但是弱的adler32算法碰撞概率太高了,所以我们还要引入强的checksum算法以保证两文件块是相同的。也就是说,弱的checksum是用来区别不同,而强的是用来确认相同。(checksum的具体公式可以参看这篇文章)
2)传输算法。同步目标端会把fileDst的一个checksum列表传给同步源,这个列表里包括了三个东西,rolling checksum(32bits),md5 checksume(128bits),文件块编号。
我估计你猜到了同步源机器拿到了这个列表后,会对fileSrc做同样的checksum,然后和fileDst的checksum做对比,这样就知道哪些文件块改变了。
但是,以下两个疑问:
如果我fileSrc这边在文件中间加了一个字符,这样后面的文件块都会位移一个字符,这样就完全和fileDst这边的不一样了,但理论上来说,我应该只需要传一个字符就好了。这个怎么解决?
如果这个checksum列表特别长,而我的两边的相同的文件块可能并不是一样的顺序,那就需要查找,线性的查找起来应该特别慢吧。这个怎么解决?
很好,让我们来看一下同步源端的算法。
3)checksum查找算法。同步源端拿到fileDst的checksum数组后,会把这个数据存到一个hash table中,用rolling checksum做hash,以便获得O(1)时间复杂度的查找性能。这个hash table是16bits的,所以,hash table的尺寸是2的16次方,对rolling checksum的hash会被散列到0 到 2^16 – 1中的某个整数值。(对于hash table,如果你不清楚,建议回去看大学时的数据结构教科书)
顺便说一下,网上看到很多文章说,“要对rolling checksum做排序”(比如这篇和这篇),这两篇文章都引用并翻译了原作者的这篇文章,但是他们都理解错了,不是排序,就只是把fileDst的checksum数据,按rolling checksum做存到2^16的hash table中,当然会发生碰撞,把碰撞的做成一个链表就好了。这就是原文中所说的第二步——搜索有碰撞的情况。
4)比对算法。这是最关键的算法,细节如下:
4.1)取fileSrc的第一个文件块(我们假设的是512个长度),也就是从fileSrc的第1个字节到第512个字节,取出来后做rolling checksum计算。计算好的值到hash表中查。
4.2)如果查到了,说明发现在fileDst中有潜在相同的文件块,于是就再比较md5的checksum,因为rolling checksume太弱了,可能发生碰撞。于是还要算md5的128bits的checksum,这样一来,我们就有 2^-(32+128) = 2^-160的概率发生碰撞,这太小了可以忽略。如果rolling checksum和md5 checksum都相同,这说明在fileDst中有相同的块,我们需要记下这一块在fileDst下的文件编号。
4.3)如果fileSrc的rolling checksum 没有在hash table中找到,那就不用算md5 checksum了。表示这一块中有不同的信息。总之,只要rolling checksum 或 md5 checksum 其中有一个在fileDst的checksum hash表中找不到匹配项,那么就会触发算法对fileSrc的rolling动作。于是,算法会住后step 1个字节,取fileSrc中字节2-513的文件块要做checksum,go to (4.1) – 现在你明白什么叫rolling checksum了吧。
4.4)这样,我们就可以找出fileSrc相邻两次匹配中的那些文本字符,这些就是我们要往同步目标端传的文件内容了。
上面的算法再做个示意图:
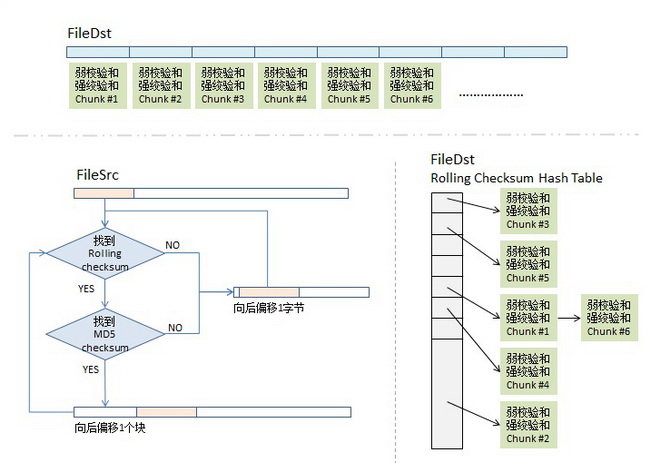
这样,最终,在同步源这端,我们的rsync算法可能会得到下面这个样子的一个数据数组,图中,红色块表示在目标端已匹配上,不用传输(注:我专门在其中显示了两块chunk #5,相信你会懂的),而白色的地方就是需要传输的内容(注意:这些白色的块是不定长的),这样,同步源这端把这个数组(白色的就是实际内容,红色的就放一个标号)压缩传到目的端,在目的端的rsync会根据这个表重新生成文件,这样,同步完成。

最后想说一下,对于某些压缩文件使用rsync传输可能会传得更多,因为被压缩后的文件可能会非常的不同。对此,对于gzip和bzip2这样的命令,记得开启 “rsyncalbe” 模式。
last : 看起来感觉rsync很简单,但是你确定你了解rsync的参数的意义么,在那些场景应该使用那些参数么
鸡汤一碗:学无止境,只要还有头发就继续搬砖!
标签:分析 32bit 远程 str 网络环境 c中 遇到 copy www.
原文地址:http://blog.51cto.com/welcomeweb/2131116