标签:执行 .com object open title imp sci .sh item
创建项目
scrapy startproject dongguan
items.py
import scrapy class DongguanItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() content = scrapy.Field() url = scrapy.Field() number = scrapy.Field()
创建CrawSpider,使用模版crawl
scrapy genspider -t crawl sun wz.sun0769.com
sun.py
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from dongguan.items import DongguanItem class SunSpider(CrawlSpider): name = ‘sun‘ allowed_domains = [‘wz.sun0769.com‘] start_urls = [‘http://wz.sun0769.com/index.php/question/questionType?type=4&page=0‘] rules = ( Rule(LinkExtractor(allow=r‘type=4&page=\d+‘)), Rule(LinkExtractor(allow=r‘/html/question/\d+/\d+.shtml‘), callback = ‘parse_item‘), ) def parse_item(self, response): item = DongguanItem()
item[‘title‘] = response.xpath(‘//div[contains(@class, "pagecenter p3")]//strong/text()‘).extract()[0] # 编号 item[‘number‘] = item[‘title‘].split(‘ ‘)[-1].split(":")[-1] # 内容 item[‘content‘] = response.xpath(‘//div[@class="c1 text14_2"]/text()‘).extract()[0] # 链接 item[‘url‘] = response.url yield item
pipelines.py
import json class DongguanPipeline(object): def __init__(self): self.filename = open("dongguan.json", "w") def process_item(self, item, spider): text = json.dumps(dict(item), ensure_ascii = False) + ",\n" self.filename.write(text.encode("utf-8"))
#python3中需改为:self.filename.write(text)
return item def close_spider(self, spider): self.filename.close()
settings.py
BOT_NAME = ‘dongguan‘ SPIDER_MODULES = [‘dongguan.spiders‘] NEWSPIDER_MODULE = ‘dongguan.spiders‘ ROBOTSTXT_OBEY = True ITEM_PIPELINES = { ‘dongguan.pipelines.DongguanPipeline‘: 300, } LOG_FILE = "dg.log" LOG_LEVEL = "DEBUG"
执行
scrapy crawl sun
发现爬取内容有缺失
问题分析:
通过 print(response.url)分析:
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from dongguan.items import DongguanItem class SunSpider(CrawlSpider): name = ‘sun‘ allowed_domains = [‘wz.sun0769.com‘] start_urls = [‘http://wz.sun0769.com/index.php/question/questionType?type=4&page=0‘] rules = ( Rule(LinkExtractor(allow=r‘type=4&page=\d+‘),callback = ‘parse_item‘), #Rule(LinkExtractor(allow=r‘/html/question/\d+/\d+.shtml‘), callback = ‘parse_item‘), ) def parse_item(self, response): print(response.url) ‘‘‘ item = DongguanItem() item[‘title‘] = response.xpath(‘//div[contains(@class, "pagecenter p3")]//strong/text()‘).extract()[0] # 编号 item[‘number‘] = item[‘title‘].split(‘ ‘)[-1].split(":")[-1] # 内容 item[‘content‘] = response.xpath(‘//div[@class="c1 text14_2"]/text()‘).extract()[0] # 链接 item[‘url‘] = response.url yield item ‘‘‘

更改匹配规则:
rules = ( Rule(LinkExtractor(allow=r‘type=4‘),callback = ‘parse_item‘), )
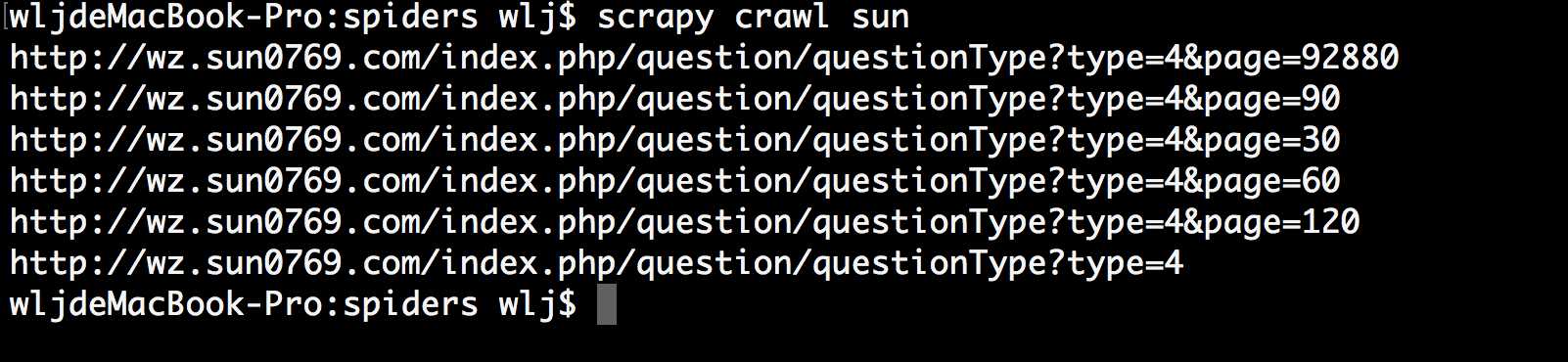
设置
follow=True
修改sun.py
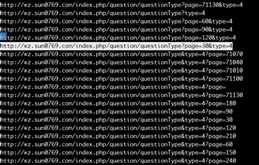
响应内容不一定是发送的url,后面的URL无效。
改写sun.py
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from newdongguan.items import NewdongguanItem class DongdongSpider(CrawlSpider): name = ‘dongdong‘ allowed_domains = [‘wz.sun0769.com‘] start_urls = [‘http://wz.sun0769.com/index.php/question/questionType?type=4&page=‘] # 每一页的匹配规则 pagelink = LinkExtractor(allow=("type=4")) # 每一页里的每个帖子的匹配规则 contentlink = LinkExtractor(allow=(r"/html/question/\d+/\d+.shtml")) rules = ( # 本案例的url被web服务器篡改,需要调用process_links来处理提取出来的url Rule(pagelink, process_links = "deal_links"), Rule(contentlink, callback = "parse_item") ) # links 是当前response里提取出来的链接列表 def deal_links(self, links): for each in links: each.url = each.url.replace("?","&").replace("Type&","Type?") return links def parse_item(self, response): item = NewdongguanItem() # 标题 item[‘title‘] = response.xpath(‘//div[contains(@class, "pagecenter p3")]//strong/text()‘).extract()[0] # 编号 item[‘number‘] = item[‘title‘].split(‘ ‘)[-1].split(":")[-1] # 内容,先使用有图片情况下的匹配规则,如果有内容,返回所有内容的列表集合 content = response.xpath(‘//div[@class="contentext"]/text()‘).extract() # 如果没有内容,则返回空列表,则使用无图片情况下的匹配规则 if len(content) == 0: content = response.xpath(‘//div[@class="c1 text14_2"]/text()‘).extract() item[‘content‘] = "".join(content).strip() else: item[‘content‘] = "".join(content).strip() # 链接 item[‘url‘] = response.url yield item
标签:执行 .com object open title imp sci .sh item
原文地址:https://www.cnblogs.com/wanglinjie/p/9211212.html