标签:除了 集中 color 简单 Oz 其他 工作 发行版 water
学习hadoop已经有很长一段时间了,好像是二三月份的时候朋友给了一个国产Hadoop发行版下载地址,因为还是在学习阶段就下载了一个三节点的学习版玩一下。在研究、学习hadoop的朋友可以去找一下看看(发行版 大快DKhadoop,去大快的网站上应该可以下载到的。)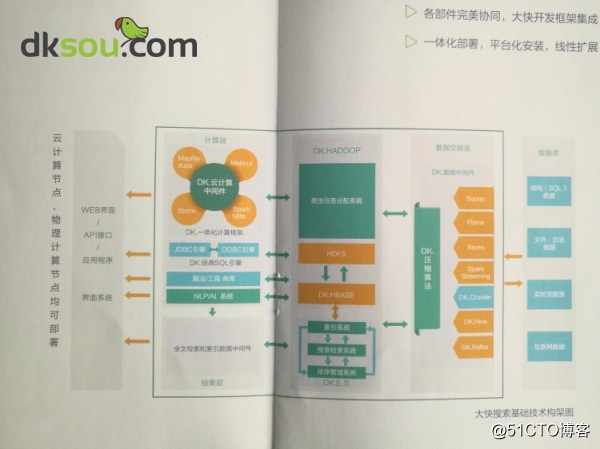
标签:除了 集中 color 简单 Oz 其他 工作 发行版 water
原文地址:http://blog.51cto.com/13636660/2131732