标签:写入 日期转换 user put 路径 tin div input init
PS C:\Users\GoFree> workon Pass a name to activate one of the following virtualenvs: ============================================================================== ArticleSpider_Env env_python2.7 env_python3.6 PycharmProjects PS C:\Users\GoFree>
C:\Users\GoFree>workon ArticleSpider_Env
(ArticleSpider_Env) C:\Users\GoFree>
Installing collected packages: attrs, pyasn1, pyasn1-modules, six, idna, asn1crypto, pycparser, cffi, cryptography, pyOpenSSL, service-identity, w3lib, lxml, cssselect, parsel, queuelib, PyDispatcher, zope.interface, constantly, incremental, Automat, hyperlink, Twisted, scrapy Successfully installed Automat-0.6.0 PyDispatcher-2.0.5 Twisted-18.4.0 asn1crypto-0.24.0 attrs-18.1.0 cffi-1.11.5 constantly-15.1.0 cryptography-2.2.2 cssselect-1.0.3 hyperlink-18.0.0 idna-2.7 incremental-17.5.0 lxml-4.2.1 parsel-1.4.0 pyOpenSSL-18.0.0 pyasn1-0.4.3 pyasn1-modules-0.2.1 pycparser-2.18 queuelib-1.5.0 scrapy-1.5.0 service-identity-17.0.0 six-1.11.0 w3lib-1.19.0 zope.interface-4.5.0 (ArticleSpider_Env) C:\Users\GoFree>
(ArticleSpider_Env) E:\myGit>scrapy startproject ArticleSpider New Scrapy project ‘ArticleSpider‘, using template directory ‘c:\\users\\gofree\\.virtualenvs\\articlespider_env\\lib\\site-packages\\scrapy\\templates\\project‘, created in: E:\myGit\ArticleSpider You can start your first spider with: cd ArticleSpider scrapy genspider example example.com (ArticleSpider_Env) E:\myGit>dir 驱动器 E 中的卷是 新加卷 卷的序列号是 D609-D119 E:\myGit 的目录 2018/06/11 18:59 <DIR> . 2018/06/11 18:59 <DIR> .. 2018/06/11 18:59 <DIR> ArticleSpider 2018/06/05 20:28 <DIR> ArticleSpider_origion 2018/06/08 18:46 <DIR> machine-learning-lxr 2018/06/08 22:48 <DIR> Search-Engine-Implementation-Using-Python 0 个文件 0 字节 6 个目录 197,621,055,488 可用字节 (ArticleSpider_Env) E:\myGit>
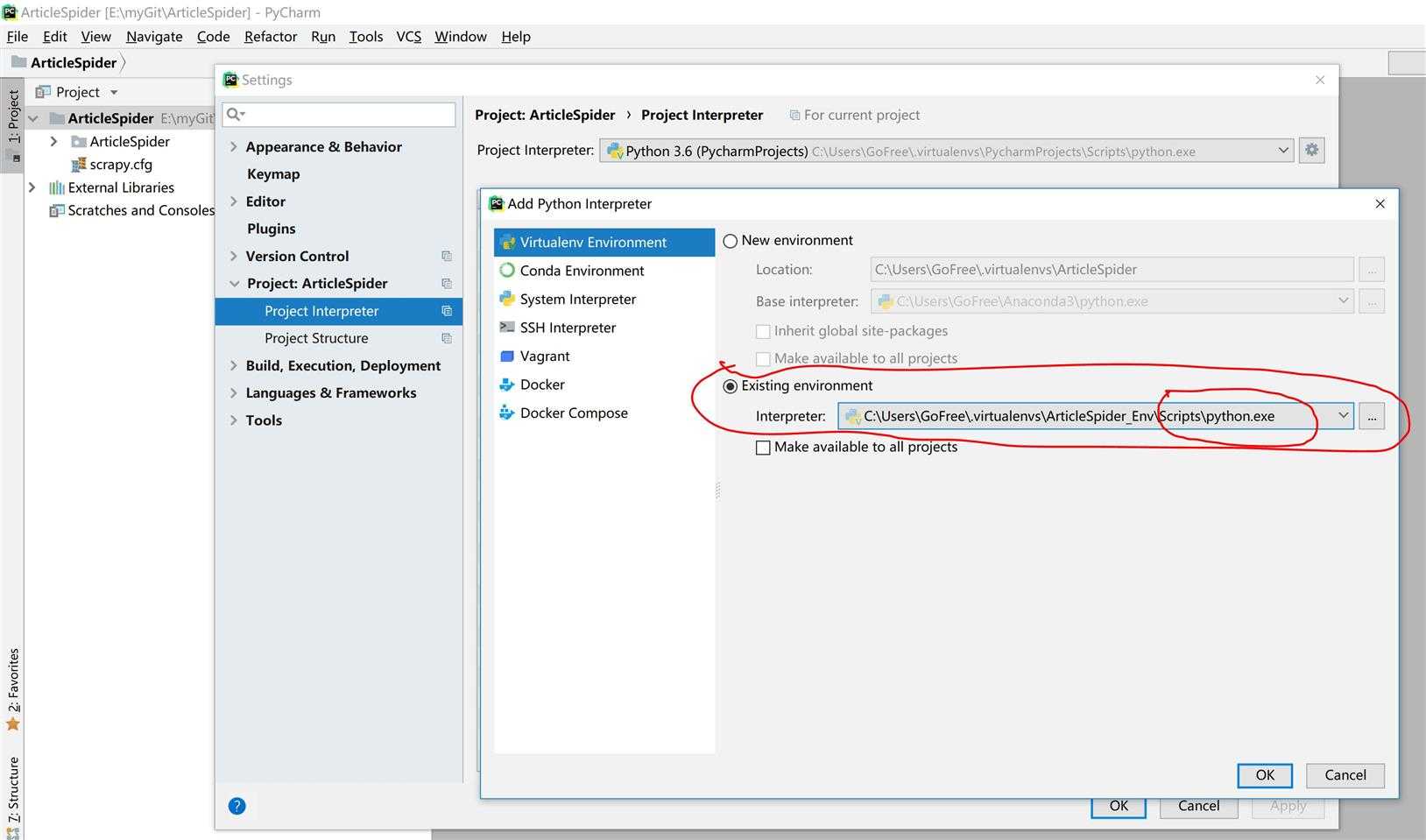
(ArticleSpider_Env) E:\myGit>cd ArticleSpider
(ArticleSpider_Env) E:\myGit\ArticleSpider>
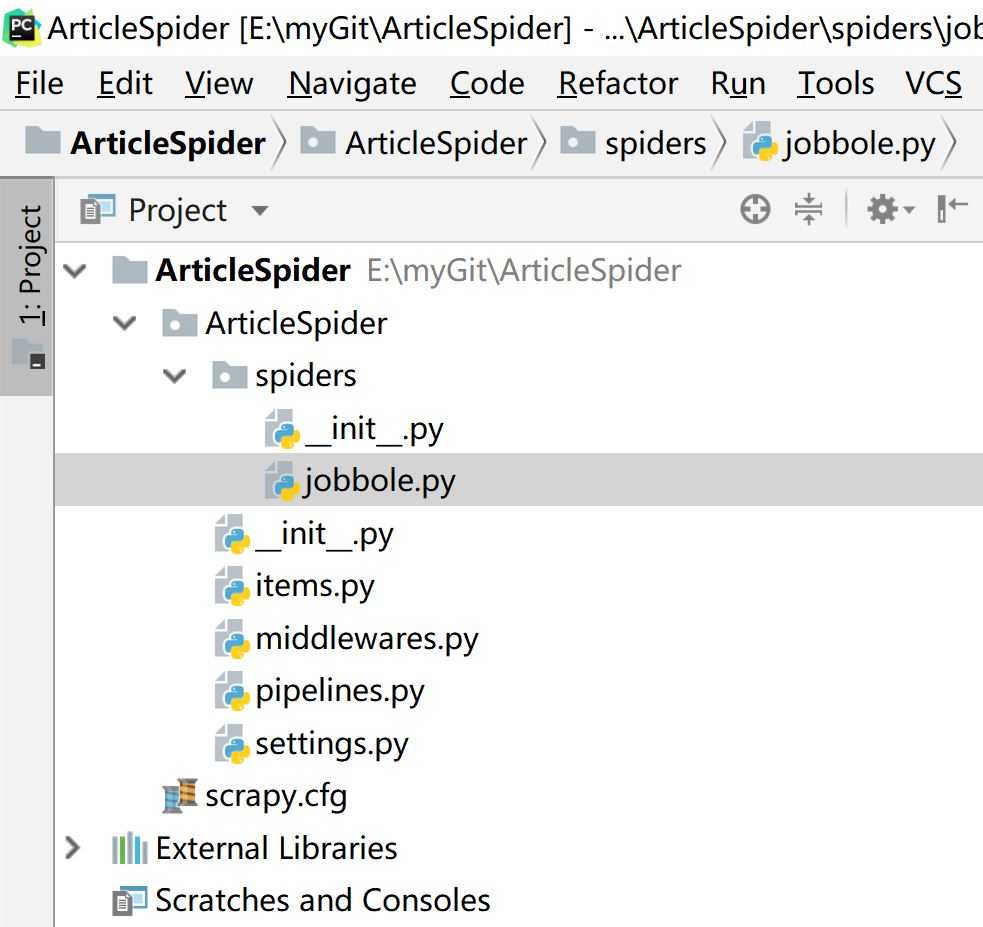
(ArticleSpider_Env) E:\myGit\ArticleSpider>scrapy genspider jobbole blog.jobbole.com
Created spider ‘jobbole‘ using template ‘basic‘ in module:
ArticleSpider.spiders.jobbole
(ArticleSpider_Env) E:\myGit\ArticleSpider>
(ArticleSpider_Env) E:\myGit\ArticleSpider>pip install pypiwin32 Collecting pypiwin32 Downloading https://files.pythonhosted.org/packages/d0/1b/2f292bbd742e369a100c91faa0483172cd91a1a422a6692055ac920946c5/pypiwin32-223-py3-none-any.whl Collecting pywin32>=223 (from pypiwin32) Downloading https://files.pythonhosted.org/packages/9f/9d/f4b2170e8ff5d825cd4398856fee88f6c70c60bce0aa8411ed17c1e1b21f/pywin32-223-cp36-cp36m-win_amd64.whl (9.0MB) 100% |████████████████████████████████| 9.0MB 5.9kB/s Installing collected packages: pywin32, pypiwin32 Successfully installed pypiwin32-223 pywin32-223 (ArticleSpider_Env) E:\myGit\ArticleSpider>
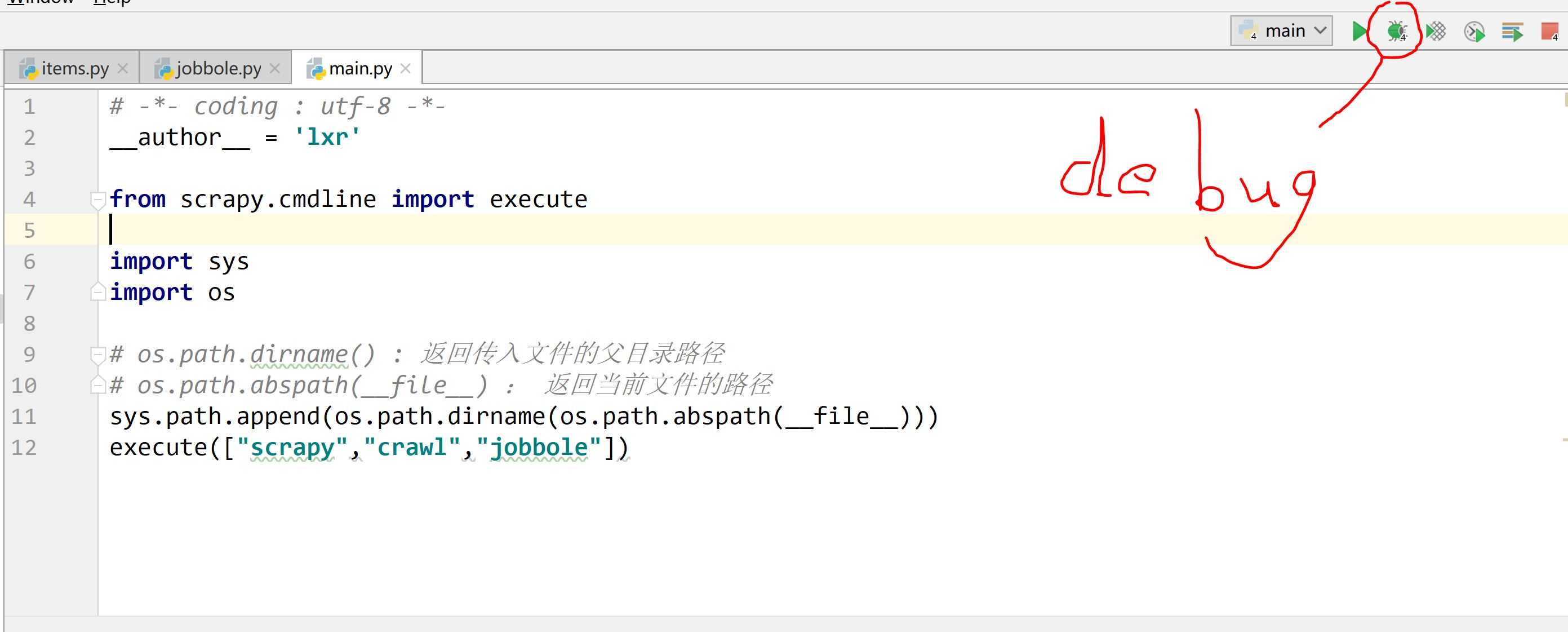
# -*- coding : utf-8 -*- __author__ = ‘lxr‘ from scrapy.cmdline import execute import sys import os # os.path.dirname() : 返回传入文件的父目录路径 # os.path.abspath(__file__) : 返回当前文件的路径 sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(["scrapy","crawl","jobbole"])



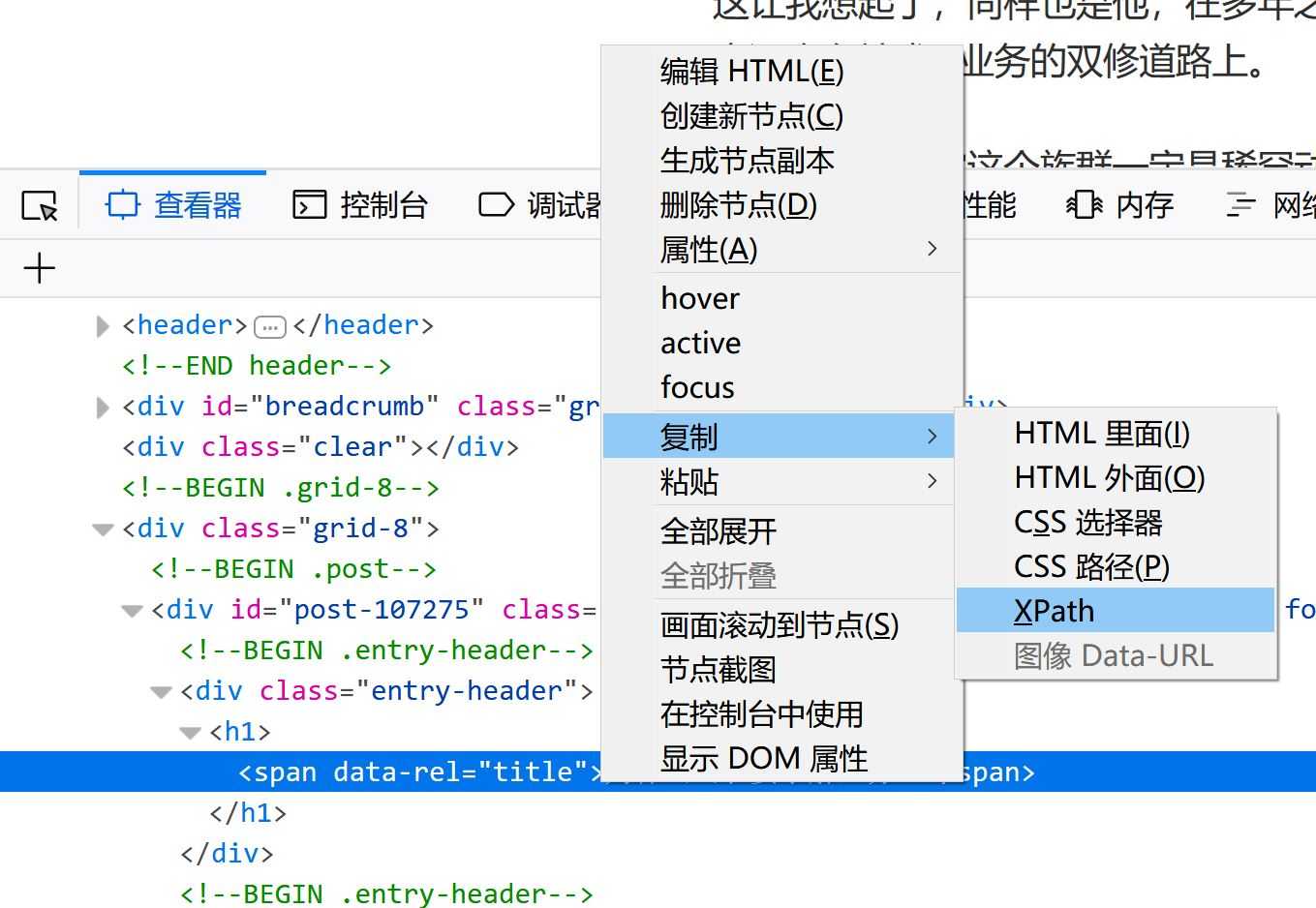 \
\


(ArticleSpider_Env) E:\myGit\ArticleSpider>scrapy shell http://blog.jobbole.com/107275/ 2018-06-12 15:15:53 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: ArticleSpider) 2018-06-12 15:15:53 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.6.2 |Continuum Analytics, Inc.| (default, Jul 20 2017, 12:30:02) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Windows-10-10.0.17134-SP0 2018-06-12 15:15:53 [scrapy.crawler] INFO: Overridden settings: {‘BOT_NAME‘: ‘ArticleSpider‘, ‘DUPEFILTER_CLASS‘: ‘scrapy.dupefilters.BaseDupeFilter‘, ‘LOGSTATS_INTERVAL‘: 0, ‘NEWSPIDER_MODULE‘: ‘ArticleSpider.spiders‘, ‘SPIDER_MODULES‘: [‘ArticleSpider.spiders‘]} 2018-06-12 15:15:53 [scrapy.middleware] INFO: Enabled extensions: [‘scrapy.extensions.corestats.CoreStats‘, ‘scrapy.extensions.telnet.TelnetConsole‘] 2018-06-12 15:15:54 [scrapy.middleware] INFO: Enabled downloader middlewares: [‘scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware‘, ‘scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware‘, ‘scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware‘, ‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware‘, ‘scrapy.downloadermiddlewares.retry.RetryMiddleware‘, ‘scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware‘, ‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware‘, ‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware‘, ‘scrapy.downloadermiddlewares.cookies.CookiesMiddleware‘, ‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware‘, ‘scrapy.downloadermiddlewares.stats.DownloaderStats‘] 2018-06-12 15:15:54 [scrapy.middleware] INFO: Enabled spider middlewares: [‘scrapy.spidermiddlewares.httperror.HttpErrorMiddleware‘, ‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware‘, ‘scrapy.spidermiddlewares.referer.RefererMiddleware‘, ‘scrapy.spidermiddlewares.urllength.UrlLengthMiddleware‘, ‘scrapy.spidermiddlewares.depth.DepthMiddleware‘] 2018-06-12 15:15:54 [scrapy.middleware] INFO: Enabled item pipelines: [] 2018-06-12 15:15:54 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6026 2018-06-12 15:15:54 [scrapy.core.engine] INFO: Spider opened 2018-06-12 15:15:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/107275/> (referer: None) [s] Available Scrapy objects: [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) [s] crawler <scrapy.crawler.Crawler object at 0x0000020E3ED38FD0> [s] item {} [s] request <GET http://blog.jobbole.com/107275/> [s] response <200 http://blog.jobbole.com/107275/> [s] settings <scrapy.settings.Settings object at 0x0000020E41439898> [s] spider <JobboleSpider ‘jobbole‘ at 0x20e416e29e8> [s] Useful shortcuts: [s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed) [s] fetch(req) Fetch a scrapy.Request and update local objects [s] shelp() Shell help (print this help) [s] view(response) View response in a browser >>>
praise_nums = response.xpath(‘//div[@class="post-adds"]/span[1]/h10/text()‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, praise_nums) if match_re: praise_nums = int(match_re.group(1)) else: praise_nums = 0
fav_nums = response.xpath(‘//div[@class="post-adds"]/span[2]/text()‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘,fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0
comment_nums = response.xpath(‘//div[@class="post-adds"]/a/span/text()‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, comment_nums) if match_re: comment_nums = int(match_re.group(1)) else: comment_nums = 0
tag_list = response.xpath(‘//p[@class="entry-meta-hide-on-mobile"]/a/text()‘).extract() tag = ",".join(tag_list)
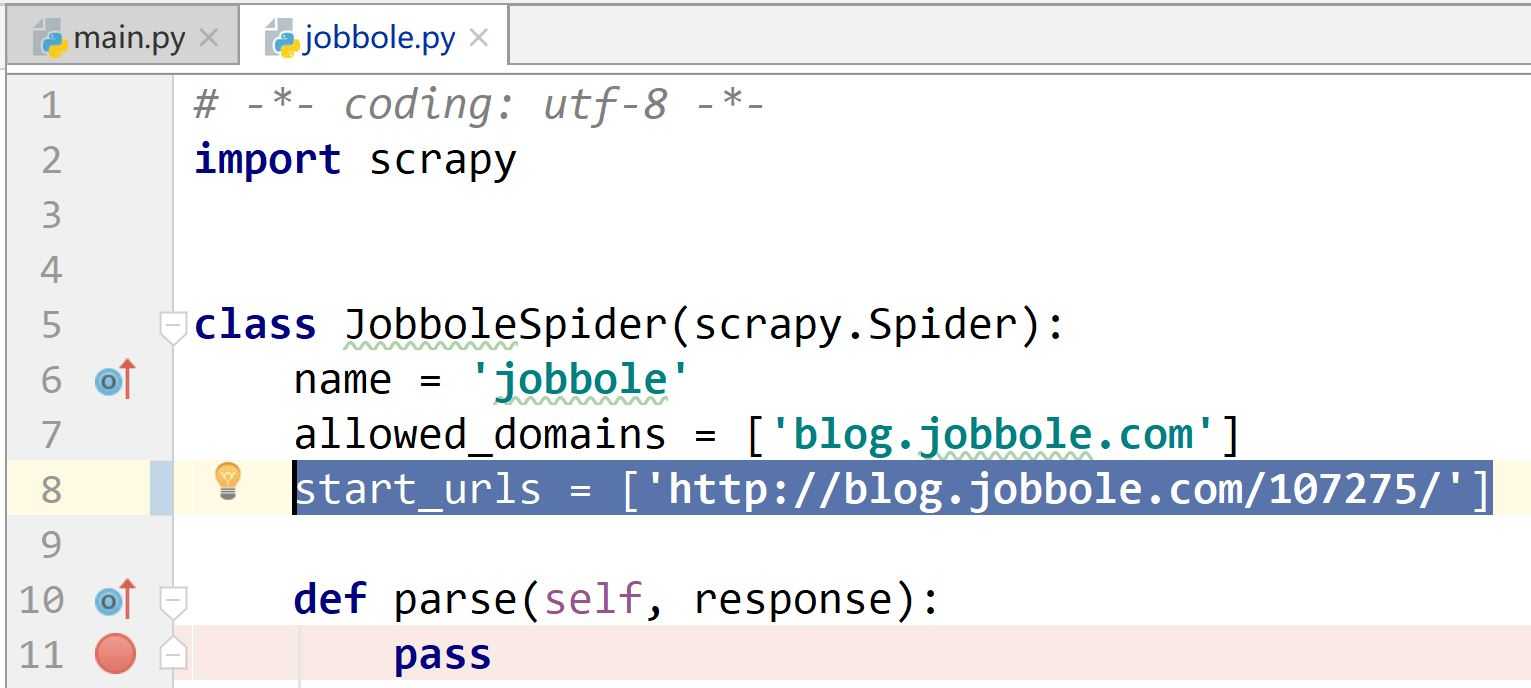
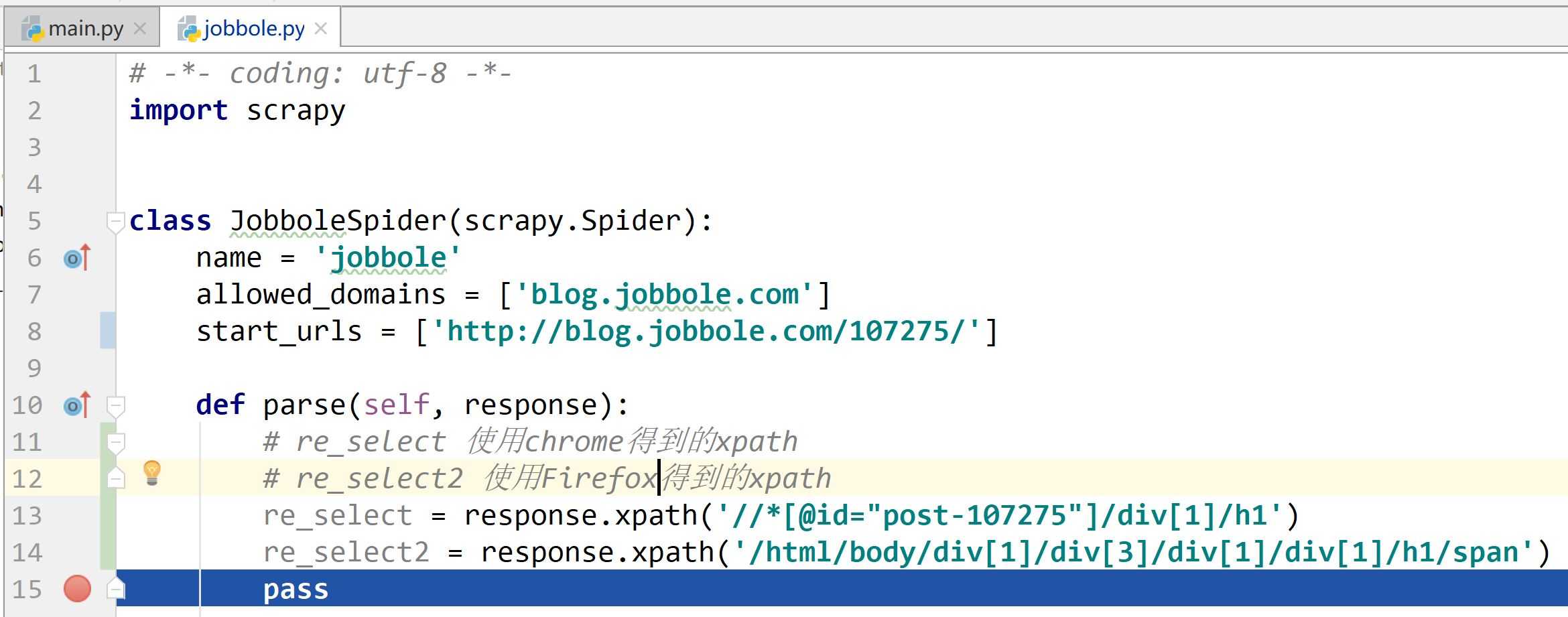
# -*- coding: utf-8 -*- import scrapy import re class JobboleSpider(scrapy.Spider): name = ‘jobbole‘ allowed_domains = [‘blog.jobbole.com‘] start_urls = [‘http://blog.jobbole.com/107275/‘] # start_urls = [‘http://blog.jobbole.com/114107/‘] def parse(self, response): #使用xpath #标题 title = response.xpath(‘//div[@class="entry-header"]/h1/text()‘).extract()[0] #发表日期 create_date = response.xpath(‘//div[@class="entry-meta"]/p/text()‘).extract()[0].strip().replace("·","").strip() #点赞数 praise_nums = response.xpath(‘//div[@class="post-adds"]/span[1]/h10/text()‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, praise_nums) if match_re: praise_nums = int(match_re.group(1)) else: praise_nums = 0 #收藏数 fav_nums = response.xpath(‘//div[@class="post-adds"]/span[2]/text()‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘,fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 #评论数 comment_nums = response.xpath(‘//div[@class="post-adds"]/a/span/text()‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, comment_nums) if match_re: comment_nums = int(match_re.group(1)) else: comment_nums = 0 #正文 content = response.xpath(‘//div[@class="entry"]‘).extract()[0] #标签 tag_list = [elem for elem in tag_list ] #在tag_list中有不是标签的项时,过滤使用 tag_list = response.xpath(‘//p[@class="entry-meta-hide-on-mobile"]/a/text()‘).extract() tag = ",".join(tag_list) pass
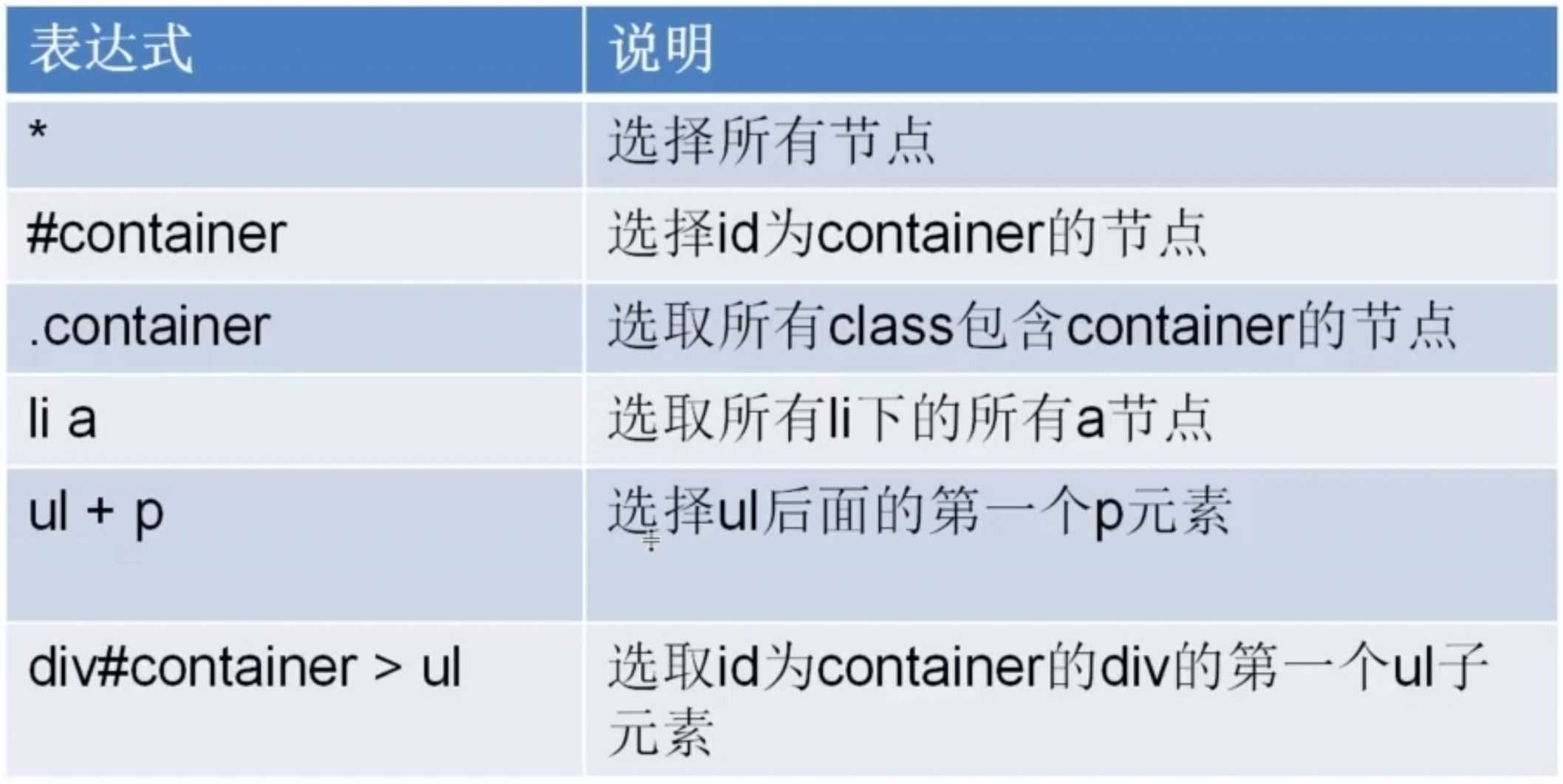
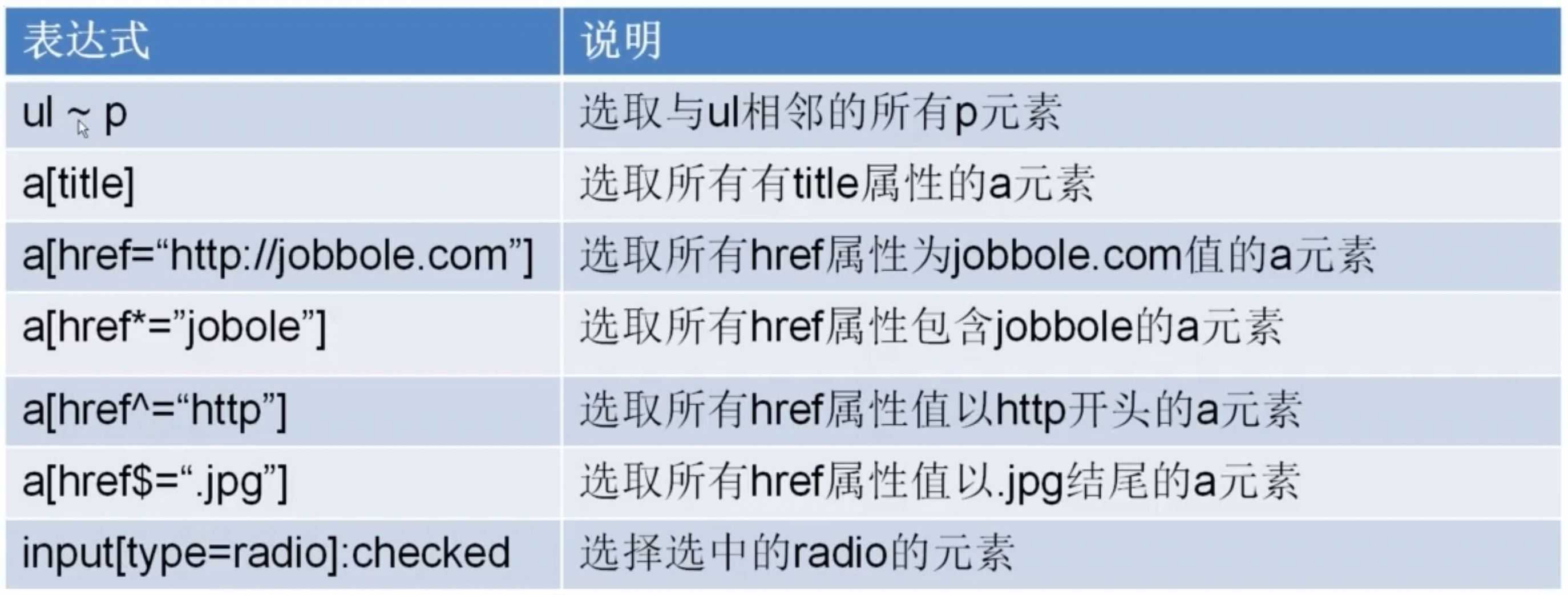

# -*- coding: utf-8 -*- import scrapy import re class JobboleSpider(scrapy.Spider): name = ‘jobbole‘ allowed_domains = [‘blog.jobbole.com‘] start_urls = [‘http://blog.jobbole.com/107275/‘] # start_urls = [‘http://blog.jobbole.com/114107/‘] def parse(self, response): #使用CSS选择器 #标题 title = response.css(‘.entry-header h1::text‘).extract()[0] #发表日期 create_date = response.css(‘.entry-meta-hide-on-mobile ::text‘).extract()[0].strip().replace("·","").strip() #点赞数 praise_nums = response.css(‘.vote-post-up h10::text‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, praise_nums) if match_re: praise_nums = int(match_re.group(1)) else: praise_nums = 0 #收藏数 fav_nums = response.css(‘.bookmark-btn::text‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘,fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 #评论数 comment_nums = response.css(‘a[href="#article-comment"] span ::text‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, comment_nums) if match_re: comment_nums = int(match_re.group(1)) else: comment_nums = 0 #正文 content = response.css(‘.entry‘).extract()[0] #标签 tag_list = response.css(‘.entry-meta-hide-on-mobile a ::text‘).extract() tag = ",".join(tag_list) pass
哪种方式适合自己就可以选择哪一种方式,两种方法没有高下之分。
def parse_detail(self, response): #提取文章具体字段 #使用CSS选择器 #标题 title = response.css(‘.entry-header h1::text‘).extract()[0] #发表日期 create_date = response.css(‘.entry-meta-hide-on-mobile ::text‘).extract()[0].strip().replace("·","").strip() #点赞数 praise_nums = response.css(‘.vote-post-up h10::text‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, praise_nums) if match_re: praise_nums = int(match_re.group(1)) else: praise_nums = 0 #收藏数 fav_nums = response.css(‘.bookmark-btn::text‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘,fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 #评论数 comment_nums = response.css(‘a[href="#article-comment"] span ::text‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, comment_nums) if match_re: comment_nums = int(match_re.group(1)) else: comment_nums = 0 #正文 content = response.css(‘.entry‘).extract()[0] #标签 tag_list = response.css(‘.entry-meta-hide-on-mobile a ::text‘).extract() tag = ",".join(tag_list) pass

if next_url: yield Request(url=parse.urljoin(response.url,next_url), callback=self.parse)
# -*- coding: utf-8 -*- import scrapy import re from scrapy.http import Request from urllib import parse class JobboleSpider(scrapy.Spider): name = ‘jobbole‘ allowed_domains = [‘blog.jobbole.com‘] start_urls = [‘http://blog.jobbole.com/all-posts/‘] def parse(self, response): """ 1.获取文章列表页中的文章url,并交给scrapy下载后并进行解析 2.获取下一页的URL并交给scrapy进行下载,下载完成后交给parse """ #获取文章列表页中的文章url,并交给scrapy下载后并进行解析 post_urls = response.css(‘#archive .floated-thumb .post-thumb a::attr(href)‘).extract() for post_url in post_urls: yield Request(url = parse.urljoin(response.url, post_url),callback = self.parse_detail) #提取下一页URL,并交给scrapy进行下载 next_url = response.css(".next.page-numbers ::attr(href)").extract_first("") if next_url: yield Request(url=parse.urljoin(response.url,next_url), callback=self.parse) def parse_detail(self, response): #提取文章具体字段 #使用CSS选择器 #标题 title = response.css(‘.entry-header h1::text‘).extract()[0] #发表日期 create_date = response.css(‘.entry-meta-hide-on-mobile ::text‘).extract()[0].strip().replace("·","").strip() #点赞数 praise_nums = response.css(‘.vote-post-up h10::text‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, praise_nums) if match_re: praise_nums = int(match_re.group(1)) else: praise_nums = 0 #收藏数 fav_nums = response.css(‘.bookmark-btn::text‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘,fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 #评论数 comment_nums = response.css(‘a[href="#article-comment"] span ::text‘).extract()[0] match_re = re.match(‘.*?(\d+).*‘, comment_nums) if match_re: comment_nums = int(match_re.group(1)) else: comment_nums = 0 #正文 content = response.css(‘.entry‘).extract()[0] #标签 tag_list = response.css(‘.entry-meta-hide-on-mobile a ::text‘).extract() tag = ",".join(tag_list) # #使用xpath # #标题 # title = response.xpath(‘//div[@class="entry-header"]/h1/text()‘).extract()[0] # #发表日期 # create_date = response.xpath(‘//div[@class="entry-meta"]/p/text()‘).extract()[0].strip().replace("·","").strip() # #点赞数 # praise_nums = response.xpath(‘//div[@class="post-adds"]/span[1]/h10/text()‘).extract()[0] # match_re = re.match(‘.*?(\d+).*‘, praise_nums) # if match_re: # praise_nums = int(match_re.group(1)) # else: # praise_nums = 0 # #收藏数 # fav_nums = response.xpath(‘//div[@class="post-adds"]/span[2]/text()‘).extract()[0] # match_re = re.match(‘.*?(\d+).*‘,fav_nums) # if match_re: # fav_nums = int(match_re.group(1)) # else: # fav_nums = 0 # #评论数 # comment_nums = response.xpath(‘//div[@class="post-adds"]/a/span/text()‘).extract()[0] # match_re = re.match(‘.*?(\d+).*‘, comment_nums) # if match_re: # comment_nums = int(match_re.group(1)) # else: # comment_nums = 0 # #正文 # content = response.xpath(‘//div[@class="entry"]‘).extract()[0] # #标签 tag_list = [elem for elem in tag_list ] #在tag_list中有不是标签的项时,过滤使用 # tag_list = response.xpath(‘//p[@class="entry-meta-hide-on-mobile"]/a/text()‘).extract() # tag = ",".join(tag_list)
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ArticlespiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class JobboleArticleItem(scrapy.Item): url = scrapy.Field() #博客url url_object_id =scrapy.Field() #url经过MD5等压缩成固定长度 front_image_url = scrapy.Field() # 封面url front_image_path = scrapy.Field() # 本地存储的封面路径 title = scrapy.Field() create_date = scrapy.Field() praise_nums= scrapy.Field() fav_nums= scrapy.Field() comment_nums= scrapy.Field() content= scrapy.Field() tag= scrapy.Field()
article_item = JobboleArticleItem() article_item["title"] = title article_item["create_date"] = create_date article_item["praise_nums"] = praise_nums article_item["fav_nums"] = fav_nums article_item["comment_nums"] = comment_nums article_item["content"] = content article_item["tags"] = tags article_item["url"] = response.url article_item["front_image_url"] = front_image_url # article_item["url_object_id"] = # article_item["front_image_path"] = yield article_item
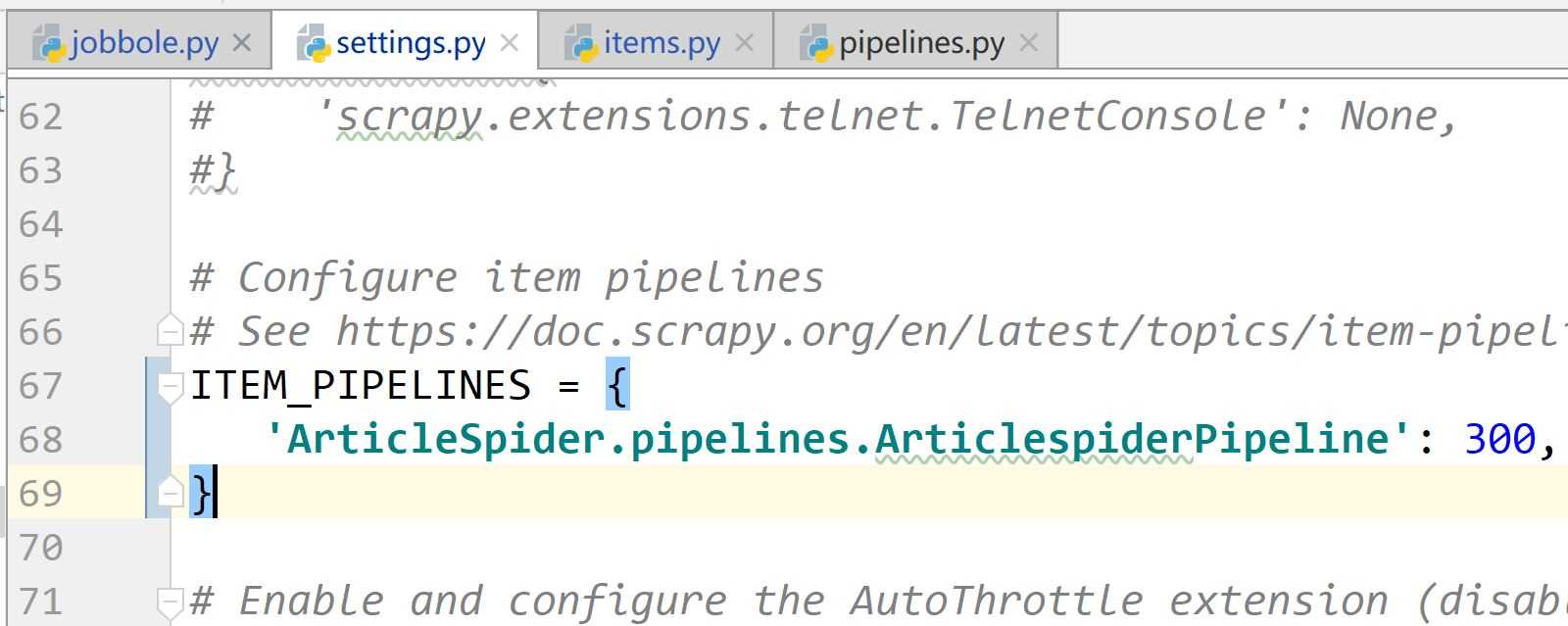
ITEM_PIPELINES = { ‘ArticleSpider.pipelines.ArticlespiderPipeline‘: 300, ‘scrapy.pipelines.images.ImagesPipeline‘:1, } IMAGES_URLS_FIELD = "front_image_url" project_dir = os.path.abspath(os.path.dirname(__file__)) IMAGES_STORE = os.path.join(project_dir,"images")
IMAGES_URLS_FIELD:指向保存封面地址的变量
IMAGES_STORE: 指定下载图片的目录
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.pipelines.images import ImagesPipeline class ArticlespiderPipeline(object): def process_item(self, item, spider): return item class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): for ok , value in results: images_file_path = value["path"] item["front_image_path"] = images_file_path return item
# Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { ‘ArticleSpider.pipelines.ArticlespiderPipeline‘: 300, # ‘scrapy.pipelines.images.ImagesPipeline‘:1, ‘ArticleSpider.pipelines.ArticleImagePipeline‘: 1, } IMAGES_URLS_FIELD = "front_image_url" project_dir = os.path.abspath(os.path.dirname(__file__)) IMAGES_STORE = os.path.join(project_dir,"images")
# -*- coding : utf-8 -*- __author__ = "lxr" import hashlib def get_md5(url): # 判断 url 是否为 unicode ,是,则转换成 utf-8 if isinstance(url,str): # str代表unicode url = url.encode("utf-8") m = hashlib.md5() m.update(url) return m.hexdigest() # 返回 抽取的摘要 if __name__ == "__main__" : print(get_md5("http://jobbole.com".encode("utf-8")))
try: create_date = datetime.datetime.strptime(create_date, "%Y/%m/%d").date() #将字符串格式的日期转换成日期格式 except Exception as e: create_date = datetime.datetime.now().date() article_item["create_date"] = create_date
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.pipelines.images import ImagesPipeline from scrapy.exporters import JsonItemExporter import codecs import json class ArticlespiderPipeline(object): def process_item(self, item, spider): return item class JsonWithEncodingPipeline(object): # 自定义json文件的导出 def __init__(self): self.file = codecs.open(‘article.json‘,‘w‘,encoding=‘utf-8‘) # 写方式打开json文件 def process_item(self, item, spider): lines = json.dumps(dict(item), ensure_ascii=False) + "\n" # item强制转为字典,再解析为json串 ; arcii设置false self.file.write(lines) # json串写入文件 return item def spider_closed(self,spider): self.file.close() #关闭文件 class JsonExporterPipeline(object): # 调用scrapy 提供的 json exporter ,导出json文件 def __init__(self): self.file = open(‘articleexport.json‘, ‘wb‘) # b二进制 self.exporter = JsonItemExporter(self.file, encoding=‘utf-8‘, ensure_ascii=False) self.exporter.start_exporting() # 开始导出json文件 def close_spider(self, spider): self.exporter.finish_exporting() # 停止导出文件 self.file.close() # 关闭文件 def process_item(self, item, spider): self.exporter.export_item(item) return item class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): for ok , value in results: images_file_path = value["path"] item["front_image_path"] = images_file_path return item
ITEM_PIPELINES = { ‘ArticleSpider.pipelines.JsonExporterPipeline‘: 2, # ‘scrapy.pipelines.images.ImagesPipeline‘:1, ‘ArticleSpider.pipelines.ArticleImagePipeline‘: 1, }
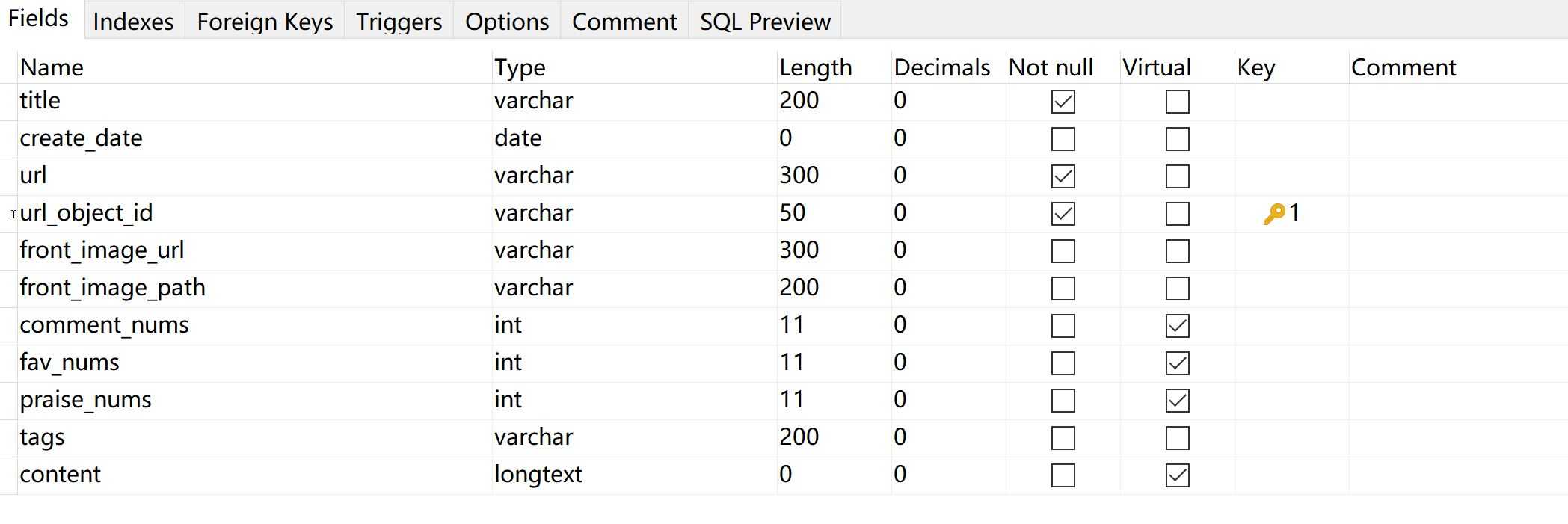
import MySQLdb.cursors from twisted.enterprise import adbapi class MysqlTwistedPipeline(object): def __init__(self, dbpool): self.dbpool = dbpool @classmethod def from_settings(cls, settings): # 将setting.py中的值导入 dbparms = dict( host = settings["MYSQL_HOST"], db = settings["MYSQL_DBNAME"], user = settings["MYSQL_USER"], passwd = settings["MYSQL_PASSWORD"], charset = "utf8", use_unicode = True, cursorclass = MySQLdb.cursors.DictCursor, ) dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms) return cls(dbpool) def process_item(self, item, spider): # 使用Twisted提供的框架,将mysql插入变成异步执行 query = self.dbpool.runInteraction(self.do_insert, item) query.addErrback(self.handle_error) # 处理异常 def handle_error(self, failure): # 处理异步插入的异常 print(failure) def do_insert(self, cursor, item): # 执行具体操作 insert_sql = """ insert into jobbole_article(title, create_date, url, url_object_id, front_image_url, front_image_path, comment_nums, fav_nums, praise_nums, tags, content) values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) """ cursor.execute(insert_sql, (item["title"], item["create_date"], item["url"], item["url_object_id"], item["front_image_url"], item["front_image_path"], item["comment_nums"], item["fav_nums"],item["praise_nums"], item["tags"], item["content"]))
ITEM_PIPELINES = { # ‘ArticleSpider.pipelines.JsonExporterPipeline‘: 2, # ‘scrapy.pipelines.images.ImagesPipeline‘:1, ‘ArticleSpider.pipelines.ArticleImagePipeline‘: 1, ‘ArticleSpider.pipelines.MysqlTwistedPipeline‘: 2, } # 添加mysql的连接参数 MYSQL_HOST="localhost" MYSQL_DBNAME="article_spider" MYSQL_USER = "root" MYSQL_PASSWORD = "root"
# -*- coding: utf-8 -*- import scrapy import re from scrapy.http import Request from urllib import parse from ArticleSpider.items import JobboleArticleItem,ArticleItemLoader from ArticleSpider.utils.common import get_md5 import datetime from scrapy.loader import ItemLoader class JobboleSpider(scrapy.Spider): name = ‘jobbole‘ allowed_domains = [‘blog.jobbole.com‘] start_urls = [‘http://blog.jobbole.com/all-posts/‘] def parse(self, response): """ 1.获取文章列表页中的文章url,并交给scrapy下载后并进行解析 2.获取下一页的URL并交给scrapy进行下载,下载完成后交给parse """ #获取文章列表页中的文章url,并交给scrapy下载后并进行解析 post_nodes = response.css(‘#archive .floated-thumb .post-thumb a‘) for post_node in post_nodes: image_url = post_node.css("img::attr(src)").extract_first("") post_url = post_node.css("::attr(href)").extract_first("") yield Request(url = parse.urljoin(response.url, post_url),meta={"front_image_url":image_url},callback = self.parse_detail) #提取下一页URL,并交给scrapy进行下载 next_url = response.css(".next.page-numbers ::attr(href)").extract_first("") if next_url: yield Request(url=parse.urljoin(response.url,next_url), callback=self.parse) def parse_detail(self, response): # #提取文章具体字段 # #使用CSS选择器 # 通过item loader加载 item item_loader = ArticleItemLoader(item=JobboleArticleItem(), response=response) front_image_url = response.meta.get("front_image_url", "") # 封面 item_loader.add_css("title", ".entry-header h1::text") item_loader.add_css("create_date", ".entry-meta-hide-on-mobile ::text") item_loader.add_value("url", response.url) item_loader.add_value("url_object_id", get_md5(response.url)) item_loader.add_value("front_image_url", [front_image_url]) item_loader.add_css("praise_nums", ".vote-post-up h10::text") item_loader.add_css("fav_nums", ".bookmark-btn::text") item_loader.add_css("comment_nums", ‘a[href="#article-comment"] span ::text‘) item_loader.add_css("content", ".entry") item_loader.add_css("tags", ".entry-meta-hide-on-mobile a ::text") article_item = item_loader.load_item() yield article_item
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy from scrapy.loader import ItemLoader from scrapy.loader.processors import MapCompose, TakeFirst, Join import datetime import re class ArticlespiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass def add_jobbole(value): return value + "-jobbole" def date_convert(value): try: create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date() # 将字符串格式的日期转换成日期格式 except Exception as e: create_date = datetime.datetime.now().date() return create_date def get_nums(value): match_re = re.match(‘.*?(\d+).*‘, value) if match_re: nums = int(match_re.group(1)) else: nums = 0 return nums def remove_comment_tags(value): if "评论" in value : return "" else: return value def return_value(value): return value class ArticleItemLoader(ItemLoader): # 自定义Item loader default_output_processor = TakeFirst() class JobboleArticleItem(scrapy.Item): url = scrapy.Field() #博客url url_object_id =scrapy.Field() #url经过MD5等压缩成固定长度 front_image_url = scrapy.Field( output_processor=MapCompose(return_value) ) # 封面url front_image_path = scrapy.Field() # 本地存储的封面路径 title = scrapy.Field( # input_processor = MapCompose(add_jobbole) # 传值的预处理 #也可使用lamda表达式 MapCompose(lamda x : x + "-jobbole") ) create_date = scrapy.Field( input_processor=MapCompose(date_convert), ) praise_nums= scrapy.Field( input_processor=MapCompose(get_nums) ) fav_nums= scrapy.Field( input_processor=MapCompose(get_nums) ) comment_nums= scrapy.Field( input_processor=MapCompose(get_nums) ) content= scrapy.Field( ) tags= scrapy.Field( input_processor=MapCompose(remove_comment_tags), output_processor = Join(",") )
class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): if "front_image_url" in item: for ok , value in results: images_file_path = value["path"] item["front_image_path"] = images_file_path return item
Scrapy分布式爬虫打造搜索引擎——(二) scrapy 爬取伯乐在线
标签:写入 日期转换 user put 路径 tin div input init
原文地址:https://www.cnblogs.com/lxr1995/p/9168484.html