标签:IV get 关键词 can head 频繁 Oz visible url
思路:1.获取拉勾网搜索到职位的页数
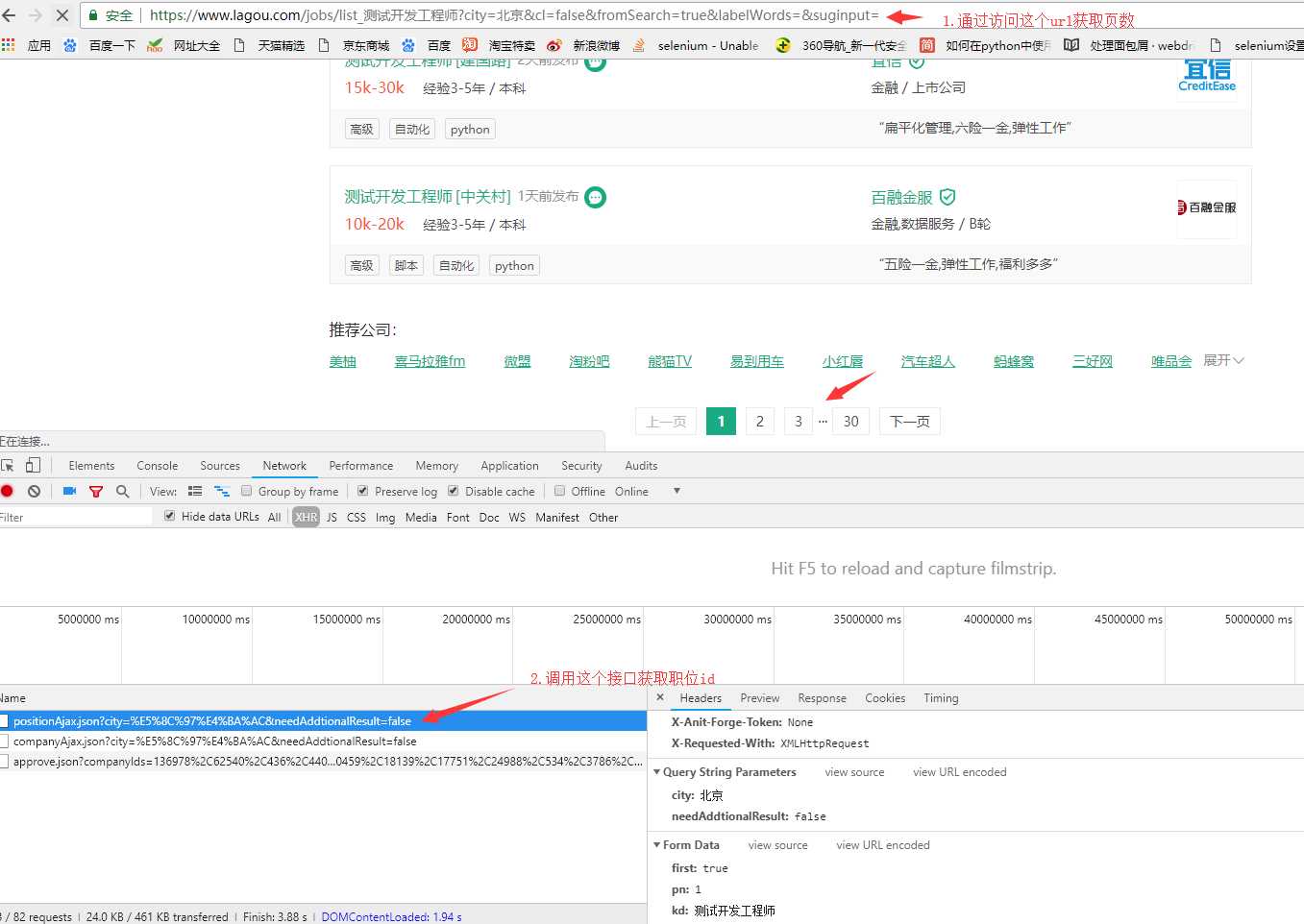
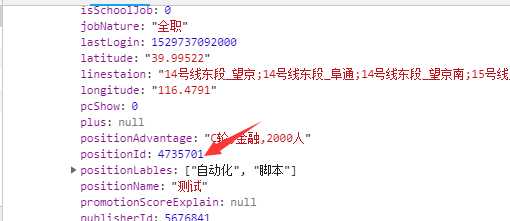
2.调用接口获取职位id
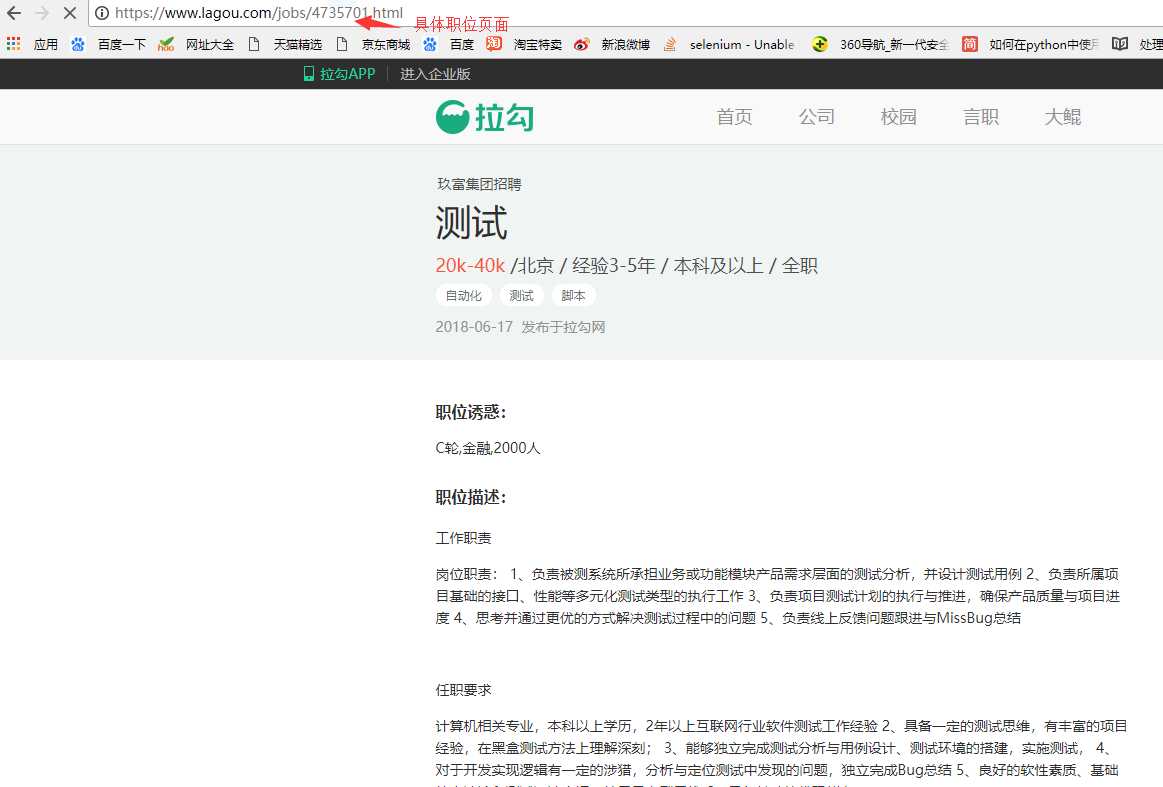
3.根据职位id访问页面,匹配出关键字
url访问采用unirest,由于拉钩反爬虫,短时间内频繁访问会被限制访问,所以没有采用多线程,而且每个页面访问时间间隔设定为10s,通过nokogiri解析页面,正则匹配只获取技能要求中的英文单词,可能存在数据不准确的情况
数据持久化到excel中,采用ruby erb生成word_cloud报告
爬虫代码:
require ‘unirest‘ require ‘uri‘ require ‘nokogiri‘ require ‘json‘ require ‘win32ole‘ @position = ‘测试开发工程师‘ @city = ‘杭州‘ # 页面访问 def query_url(method, url, headers:{}, parameters:nil) case method when :get Unirest.get(url, headers:headers).body when :post Unirest.post(url, headers:headers, parameters:parameters).body end end # 获取页数 def get_page_num(url) html = query_url(:get, url).force_encoding(‘utf-8‘) html.scan(/<span class="span totalNum">(\d+)<\/span>/).first.first end # 获取每页显示的所有职位的id def get_positionsId(url, headers:{}, parameters:nil) response = query_url(:post, url, headers:headers, parameters:parameters) positions_id = Array.new response[‘content‘][‘positionResult‘][‘result‘].each{|i| positions_id << i[‘positionId‘]} positions_id end # 匹配职位英文关键字 def get_skills(url) puts "loading url: #{url}" html = query_url(:get, url).force_encoding(‘utf-8‘) doc = Nokogiri::HTML(html) data = doc.css(‘dd.job_bt‘) data.text.scan(/[a-zA-Z]+/) end # 计算词频 def word_count(arr) arr.map!(&:downcase) arr.select!{|i| i.length>1} counter = Hash.new(0) arr.each { |k| counter[k]+=1 } # 过滤num=1的数据 counter.select!{|_,v| v > 1} counter2 = counter.sort_by{|_,v| -v}.to_h counter2 end # 转换 def parse(hash) data = Array.new hash.each do |k,v| word = Hash.new word[‘name‘] = k word[‘value‘] = v data << word end JSON data end # 持久化数据 def save_excel(hash) excel = WIN32OLE.new(‘Excel.Application‘) excel.visible = false workbook = excel.Workbooks.Add() worksheet = workbook.Worksheets(1) # puts hash.size (1..hash.size+1).each do |i| if i == 1 # puts "A#{i}:B#{i}" worksheet.Range("A#{i}:B#{i}").value = [‘关键词‘, ‘频次‘] else # puts i # puts hash.keys[i-2], hash.values[i-2] worksheet.Range("A#{i}:B#{i}").value = [hash.keys[i-2], hash.values[i-2]] end end excel.DisplayAlerts = false workbook.saveas(File.dirname(__FILE__)+‘\lagouspider.xls‘) workbook.saved = true excel.ActiveWorkbook.Close(1) excel.Quit() end # 获取页数 url = URI.encode("https://www.lagou.com/jobs/list_#@position?city=#@city&cl=false&fromSearch=true&labelWords=&suginput=") num = get_page_num(url).to_i puts "存在 #{num} 个信息分页" skills = Array.new (1..num).each do |i| puts "定位在第#{i}页" # 获取positionsid url2 = URI.encode("https://www.lagou.com/jobs/positionAjax.json?city=#@city&needAddtionalResult=false") headers = {Referer:url, ‘User-Agent‘:i%2==1?‘Mozilla/5.0‘:‘Chrome/67.0.3396.87‘} parameters = {first:(i==1), pn:i, kd:@position} positions_id = get_positionsId(url2, headers:headers, parameters:parameters) positions_id.each do |id| # 访问具体职位页面,提取英文技能关键字 url3 = "https://www.lagou.com/jobs/#{id}.html" skills.concat get_skills(url3) sleep 10 end end count = word_count(skills) save_excel(count) @data = parse(count)
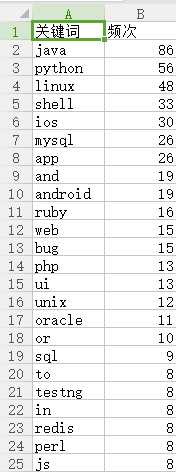
效果展示:

标签:IV get 关键词 can head 频繁 Oz visible url
原文地址:https://www.cnblogs.com/wf0117/p/9218196.html