标签:nat 增量 插入数据 完成 for循环 redis事务 exists 良好的 半径
redis中文网站:http://www.redis.net.cn/ 和 http://redis.cn/
redis官网:http://redis.io/
命令的链接:http://redisdoc.com/
访问以下网站时,当你只是刷新时,谷歌按F12你会发现,并最后修改时间,并没有发生改变:因为你访问是缓存
# curl --head www.baidu.com HTTP/1.1 200 OK Server: bfe/1.0.8.18 Date: Fri, 16 Dec 2016 03:18:29 GMT Content-Type: text/html Content-Length: 277 Last-Modified: Mon, 13 Jun 2016 02:50:07 GMT 最后修改时间 Connection: Keep-Alive ETag: "575e1f5f-115" Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform Pragma: no-cache Accept-Ranges: bytes
转自 【转载请注明来自于-运维社区】https://www.unixhot.com/page/cache
| Web架构知识体系之缓存 | |||
| 缓存分层 | 缓存分级 | 内容 | 内容简介 |
| 用户层 | DNS | DNS系统本地缓存 | 客户端操作系统DNS缓存 |
| LocalDNS缓存 | 本地DNS提供商的缓存 | ||
| DNS缓存服务器 | 专用的DNS缓存服务器 | ||
| 浏览器DNS缓存 | Firefox默认60秒,HTML5的新特性:DNS Prefetching | ||
| 应用程序DNS缓存 | Java(JVM)、PHP语言本身的DNS缓存 | ||
| 浏览器 | 浏览器缓存 | HMTL5新特性:Link Prefetching | |
| 基于最后修改时间的HTTP缓存协商: Last-Modified | |||
| 基于过期时间的HTTP缓存协商: Expires、cache-control | |||
| 基于打标签的HTTP缓存协商: Etag | |||
| 代理层 | CDN | 反向代理缓存 | 基于Squid、Varnish、Nginx、ATS等,一般有多级 |
| Web层 | 解释器 | Opcache | 操作码缓存 |
| Web服务器 | Web服务器缓存 | Apache(mod_cache)、Nginx(FastCGI缓存、Proxy cache) | |
| 应用层 | 应用服务 | 动态内容缓存 | 缓存动态内存输出 |
| Local Cache | 应用本地缓存,PHP(Yac、Xcache) Java(ehcache) | ||
| 页面静态化 | 动态页面静态化,专门用于静态化的CMS | ||
| 数据层 | 分布式缓存 | 分布式缓存 | Memcache、Redis |
| 数据库 | MySQL | innodb缓存、MYISAM缓存 | |
| 系统层 | 操作系统 | CPU Cache | L1(数据缓存、指令缓存) L2、L3 |
| 内存Cache | 内存高速缓存、Page Cache | ||
| 物理层 | 磁盘 | Disk Cache | 磁盘缓存(Cache memory) |
| 硬件 | Raid Cache | 磁盘阵列缓存 | |
| 备注 | 1.此体系结构仅包含缓存(Cache),不包含缓冲(Buffer),所有很多缓冲区没有列举。 2.根据用户发起一个HTTP请求开始,持续更新中,欢迎大家添加更多的内容。 |
||
例如:大小图片的处理机制是不一样的,配置不同的调配参数
block的大小,默认是4K(原因:因为内存的一个页也是4K)
动态没必要上CDN,因为它的变化频率大;静态的需要上CDN,提升用户的体验,这样的话方便上CDN
浏览器请求并发数是基于域名的
不同的版本的不同浏览器的并发不一样
后两个域名的区别特别大
1)提升了访问的速度,从而提生了用户的体验
2)减少了带宽,为企业节省了成本
域名多的情况下,弊端就是DNS解析的时间多了,但是这个时间是可以忽略不计的
redis不单单可以做缓存;写的时候,就把它当成数据库写的
redis是VM vare支持的
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
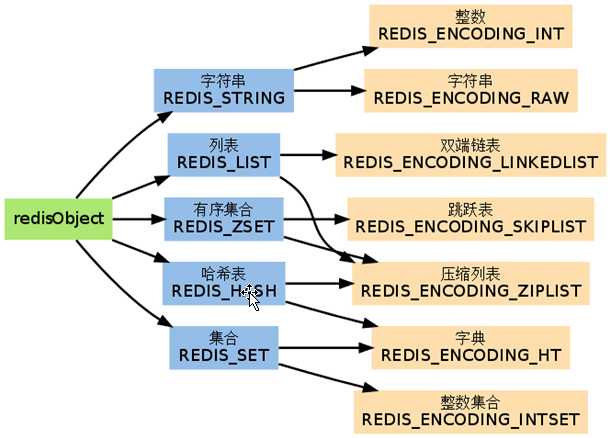
它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
|
redis本身是单线程程序 (线程层面)
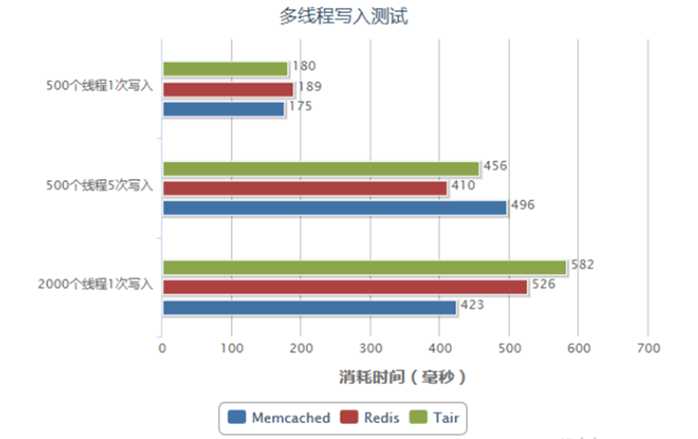
提高访问性能,使用的方式与memcache相同。 主要是电商企业
保存web会话信息 超过5000个会话,NFS是个瓶颈
Nginx+lua+Redis计数器进行IP自动封禁。
构建实时消息系统,聊天,群聊。
用户把产品放入购物车,用户下次访问的时候,购物车结算的商品还在。(把用户的购物车记录下来)
用户不登录:购物车的内容放在cookie
用户登录后:购物车的内容存放在redis uid_xxx value购物车,设置过期时间
数据库读缓存
session处理有几种方式
1)语言支持多
2) 简单、高效
3)所有开发都会 PHP的配置文件php.ini配置session存储位置;tomcat sessionmanager
第二条 但设置完后,当超过数量,会直接剔除最旧的数据
appendonly yes/no
86 save 900 1 ##每900s内有1个键发生变化,做一个快照 87 save 300 10 ##每300s内有10个键变化,就做一个快照 88 save 60 10000 ##60s内有10000个键变化,就做一个快照
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改,即将数据写入硬盘。
这个需要优化,一般情况下是关闭的 (当没有MySQL的情况下,必须开启)
106 # Note that you must specify a directory here, not a file name. 107 dir /var/lib/redis/
[root@tomcat redis]# ll total 4 -rw-r--r-- 1 redis redis 243 Dec 26 10:19 dump.rdb [root@tomcat redis]# file dump.rdb dump.rdb: data ##当你快照完成后,可以将原来的rdb文件替换掉
dbcompression yes
指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
节省空间,浪费CPU(根据企业的现况,具体考量,决策)
appendfsync everysec
在默认情况下, Redis 将数据库快照保存在名字为 dump.rdb 的二进制文件中。
你可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动保存一次数据集。
你也可以通过调用 SAVE 或者 BGSAVE , 手动让 Redis 进行数据集保存操作。
比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 1000 个键被改动”这一条件时, 自动保存一次数据集:
save 60 1000
这种持久化方式被称为快照(snapshot)。
当 Redis 需要保存 dump.rdb 文件时, 服务器执行以下操作:
这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益。
快照功能并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。
尽管对于某些程序来说, 数据的耐久性并不是最重要的考虑因素, 但是对于那些追求完全耐久能力(full durability)的程序来说, 快照功能就不太适用了。
从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化。
你可以通过修改配置文件来打开 AOF 功能:
appendonly yes
从现在开始, 每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。
这样的话, 当 Redis 重新启时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
修改配置文件redis.conf
266 # log file in background when it gets too big. 267 268 appendonly yes ###将no改成yes
AOF 重写和 RDB 创建快照一样,都巧妙地利用了写时复制机制。
以下是 AOF 重写的执行步骤:
搞定!现在 Redis 原子地用新文件替换旧文件,之后所有命令都会直接追加到新 AOF 文件的末尾
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
因为以上提到的种种原因, 未来我们可能会将 AOF 和 RDB 整合成单个持久化模型。 (这是一个长期计划。)
接下来的几个小节将介绍 RDB 和 AOF 的更多细节。
注意:
[root@tomcat redis]# for ((i=1;i<=1000;i++));do echo $i;done [root@tomcat redis]# for ((i=1;i<=1000;i++));do redis-cli -h 10.0.0.150 set k$i $i;done
在 Redis 2.2 或以上版本,可以在不重启的情况下,从 RDB 切换到 AOF :
1)为最新的 dump.rdb 文件创建一个备份。
2)将备份放到一个安全的地方。
3)执行以下两条命令: ###配置文件也要弄
redis-cli> CONFIG SET appendonly yes redis-cli> CONFIG SET save ""
4)确保命令执行之后,数据库的键的数量没有改变。
5)确保写命令会被正确地追加到 AOF 文件的末尾。
步骤 3 执行的第一条命令开启了 AOF 功能: Redis 会阻塞直到初始 AOF 文件创建完成为止, 之后 Redis 会继续处理命令请求, 并开始将写入命令追加到 AOF 文件末尾。
步骤 3 执行的第二条命令用于关闭 RDB 功能。 这一步是可选的, 如果你愿意的话, 也可以同时使用 RDB 和 AOF 这两种持久化功能。
别忘了在 redis.conf 中打开 AOF 功能! 否则的话, 服务器重启之后, 之前通过 CONFIG SET 设置的配置就会被遗忘, 程序会按原来的配置来启动服务器。
阅读这个小节前, 先将下面这句话铭记于心: 一定要备份你的数据库!
需求:磁盘故障, 节点失效, 诸如此类的问题都可能让你的数据消失不见, 不进行备份是非常危险的。
Redis 对于数据备份是非常友好的, 因为你可以在服务器运行的时候对 RDB 文件进行复制: RDB 文件一旦被创建, 就不会进行任何修改。 当服务器要创建一个新的 RDB 文件时, 它先将文件的内容保存在一个临时文件里面, 当临时文件写入完毕时, 程序才使用 rename(2) 原子地用临时文件替换原来的 RDB 文件。
这也就是说, 无论何时, 复制 RDB 文件都是绝对安全的。
Redis 的容灾备份基本上就是对数据进行备份, 并将这些备份传送到多个不同的外部数据中心。
容灾备份可以在 Redis 运行并产生快照的主数据中心发生严重的问题时, 仍然让数据处于安全状态。
因为很多 Redis 用户都是创业者, 他们没有大把大把的钱可以浪费, 所以下面介绍的都是一些实用又便宜的容灾备份方法:
需要注意的是, 这类容灾系统如果没有小心地进行处理的话, 是很容易失效的。
最低限度下, 你应该在文件传送完毕之后, 检查所传送备份文件的体积和原始快照文件的体积是否相同。 如果你使用的是 VPS , 那么还可以通过比对文件的 SHA1 校验和来确认文件是否传送完整。
另外, 你还需要一个独立的警报系统, 让它在负责传送备份文件的传送器(transfer)失灵时通知你

127.0.0.1:6379> expire foo 20 (integer) 1 127.0.0.1:6379> get foo "wzs" 127.0.0.1:6379> TTL foo (integer) 7 127.0.0.1:6379> get foo (nil)
SET name "guohz“ Get name
一个键默认最大能存储512MB
127.0.0.1:6379> keys * 1) "foo" 127.0.0.1:6379> set name wzs OK 127.0.0.1:6379> append name yjj (integer) 6 127.0.0.1:6379> get name "wzsyjj" 127.0.0.1:6379> mset key k1 key2 k2 key3 k3 OK 127.0.0.1:6379> mget key key2 key3 1) "k1" 2) "k2" 3) "k3"
127.0.0.1:6379> incr num (integer) 2001 127.0.0.1:6379> decr num (integer) 2000 127.0.0.1:6379> decr num (integer) 1999
127.0.0.1:6379> incrby num 100 (integer) 2099 127.0.0.1:6379> decrby num 100 (integer) 1999
Redis hash 是一个键值对集合。 Redis hash是一个string类型的field和value的映射表 hash特别适合用于存储对象。 每个 hash 可以存储 2^32 -1(4294967295) 键值对
127.0.0.1:6379> hset h1 name wzs (integer) 1 127.0.0.1:6379> hget h1 name "wzs" 127.0.0.1:6379> hset h1 sex male (integer) 1 127.0.0.1:6379> hset h1 age 28 (integer) 1 127.0.0.1:6379> hget h1 name "wzs"
127.0.0.1:6379> hgetall h1 1) "name" 2) "wzs" 3) "sex" 4) "male" 5) "age" 6) "28"
127.0.0.1:6379> hkeys h1 1) "name" 2) "sex" 3) "age" 127.0.0.1:6379> hvals h1 1) "wzs" 2) "male" 3) "28"
Redis列表是简单的字符串列表。 按照插入顺序排序每个 LIST可以存储 2^32 -1 键值对
127.0.0.1:6379> lpush list1 guo hong ze old boy (integer) 5 127.0.0.1:6379> lrange list1 0 10 1) "boy" 2) "old" 3) "ze" 4) "hong" 5) "guo" 127.0.0.1:6379> lrange list1 0 10 1) "wzs" 127.0.0.1:6379> rpush list1 yjj 127.0.0.1:6379> lpop list1 "wzs" 127.0.0.1:6379> rpop list1 "yjj" 127.0.0.1:6379> llen list1 (integer) 5 127.0.0.1:6379> lrem list1 2 morning (integer) 2 127.0.0.1:6379> lrange list1 0 10 1) "pn" 2) "addd" 3) "morning" 4) "boy" 5) "old" 6) "ze" 7) "hong" 8) "guo" 127.0.0.1:6379> lset list1 2 lidazhao
比较有前后顺序
127.0.0.1:6379> sadd set1 wzs yjj zy (integer) 3 127.0.0.1:6379> sadd set1 wzs zhangsanfeng (integer) 1 127.0.0.1:6379> scard set1 (integer) 4 127.0.0.1:6379> sadd set2 wzs zhangsanfeng oldboy sjh laosiji (integer) 5 127.0.0.1:6379> sdiff set1 set2 1) "yjj" 2) "zy" 127.0.0.1:6379> sdiff set2 set1 1) "sjh" 2) "oldboy" 3) "laosiji" 127.0.0.1:6379> SMEMBERS set2
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
ZRANGEBYSCORE salary -inf +inf WITHSCORES
127.0.0.1:6379> zadd salary 10000 wzs (integer) 1 127.0.0.1:6379> zscore salary wzs "10000" 127.0.0.1:6379> zadd salary 13000 oldboy (integer) 1 127.0.0.1:6379> zadd salary 9000 zy (integer) 1 127.0.0.1:6379> zadd salary 12000 yjj (integer) 1 127.0.0.1:6379> zcount salary 10000 20000 (integer) 3
127.0.0.1:6379> zincrby salary 1000 wzs "11000" 127.0.0.1:6379> zscore salary wzs "11000"
127.0.0.1:6379> zincrby salary -1000 zy "8000" 127.0.0.1:6379> zscore salary zy "8000"
127.0.0.1:6379> zrange salary 0 -1 1) "zy" 2) "wzs" 3) "yjj" 4) "oldboy" 127.0.0.1:6379> zrange salary 0 -1 withscores 开始到最后 1) "zy" 2) "8000" 3) "wzs" 4) "11000" 5) "yjj" 6) "12000" 7) "oldboy" 8) "13000" 127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf WITHSCORES 127.0.0.1:6379> ZRANGEBYSCORE salary 10000 20000 WITHSCORES 1) "wzs" 2) "11000" 3) "yjj" 4) "12000" 5) "oldboy" 6) "13000" 127.0.0.1:6379> ZRANGEBYSCORE salary 10000 20000 1) "wzs" 2) "yjj" 3) "oldboy"
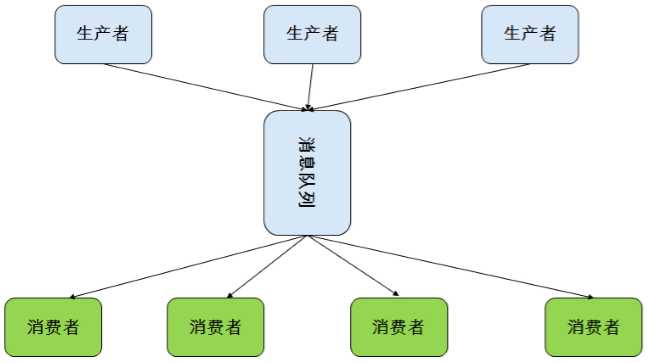
发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。
队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到。
发布-订阅模式中消息被广播到所有的consumer中,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
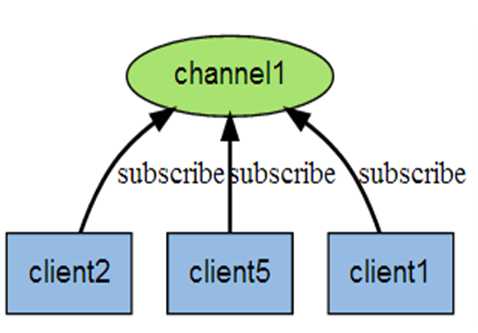
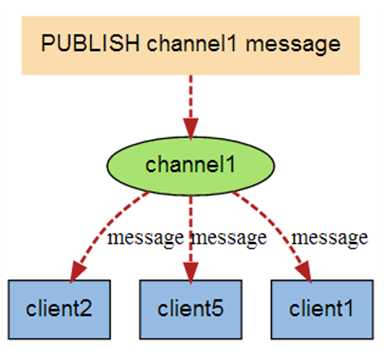
SUBSCRIBE mq1 #客户端
PUBLISH mq1 "Redis is a great caching technique"
127.0.0.1:6379> subscribe channel1 Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "channel1" 3) (integer) 1 1) "message" 2) "channel1"
127.0.0.1:6379> pubsub channels 1) "channel1" 127.0.0.1:6379> pubsub numsub channel1 1) "channel1" 2) (integer) 2
事务的特性:原子性、一致性、分离性、持久性
zadd salary 2000 guohongze zadd salary 3000 oldboy ZRANGE salary 0 -1 WITHSCORES MULTI ZINCRBY salary 1000 guohongze zincrby salary -1000 oldboy EXEC 127.0.0.1:6379> multi OK 127.0.0.1:6379> zincrby salary -1000 yjj QUEUED 127.0.0.1:6379> zincrby salary 1000 wzs QUEUED 127.0.0.1:6379> exec 1) "11000" 2) "12000"
Info Client list Client kill ip:port config get * CONFIG RESETSTAT 重置统计 CONFIG GET/SET 动态修改 Dbsize FLUSHALL 清空所有数据 select 1 FLUSHDB 清空当前库 MONITOR 监控实时指令 SHUTDOWN 关闭服务器 save将当前数据保存 SLAVEOF host port 主从配置 SLAVEOF NO ONE SYNC 主从同步 ROLE返回主从角色
Slow log 是 Redis 用来记录查询执行时间的日志系统。 slow log 保存在内存里面,读写速度非常快 可以通过改写 redis.conf 文件或者用 CONFIG GET 和 CONFIG SET 命令对它们动态地进行修改 slowlog-log-slower-than 10000 超过多少微秒 CONFIG SET slowlog-log-slower-than 100 CONFIG SET slowlog-max-len 1000 保存多少条慢日志 CONFIG GET slow* SLOWLOG GET SLOWLOG RESET
127.0.0.1:6379> config set slowlog-max-len 256 OK 127.0.0.1:6379> config get slow* 1) "slowlog-log-slower-than" 2) "10000" 3) "slowlog-max-len" 4) "256"
127.0.0.1:6379> CONFIG GET dir 1) "dir" 2) "/data/server/redis/src" 127.0.0.1:6379> config set dir /data/server/redis OK 127.0.0.1:6379> CONFIG GET dir 1) "dir" 2) "/data/server/redis" 127.0.0.1:6379> save OK
[root@yumlib redis]# ls 00-RELEASENOTES deps MANIFESTO runtest src BUGS dump.rdb

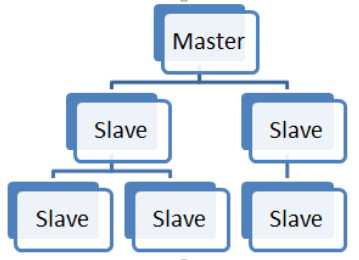
当数据量变得庞大的时候,读写分离还是很有必要的。同时避免一个redis服务宕机,导致应用宕机的情况,我们启用sentinel(哨兵)服务,实现主从切换 的功能。redis提供了一个master,多个slave的服务。
准备三个redis服务,依次命名文件夹子master,slave1,slave2.这里为在测试机上,不干扰原来的redis服务,我们master使用6000端口。
注意:配置文件的位置,根据实际情况更改
slaveof 192.168.1.1 6379 slave-read-only 只读模式 masterauth <password> 主服务器设置密码后需要填写密码 min-slaves-to-write <number of slaves> 从服务器不少于,才允许写入 min-slaves-max-lag <number of seconds> 从服务器延迟不大于 CONFIG set slave-read-only yes Config set masterauth root INFO replication SLAVEOF NO ONE 升级至MASTER
port 6000 requirepass 123456
port 6001 slaveof 127.0.0.1 6000 masterauth 123456 requirepass 123456
port 6002 slaveof 127.0.0.1 6000 masterauth 123456 requirepass 123456
requirepass:是认证密码,应该之后要作主从切换,所以建议所有的密码都一致。masterauth是从机对主机验证时,所需的密码(即主机的requirepass)。
注意:配置文件的位置,根据实际情况更改
redis-server redis.conf
redis-server redis1.conf
redis-server redis2.conf
ps -ef |grep redis ss -lutnp
# redis-cli -h 127.0.0.1 -p 6000 127.0.0.1:6000> auth 123456 OK 127.0.0.1:6000> set test chenqm OK
# redis-cli -h 127.0.0.1 -p 6001 127.0.0.1:6001> auth 123456 OK 127.0.0.1:6001> get test "chenqm"
# redis-cli -h 127.0.0.1 -p 6002 127.0.0.1:6001> auth 123456 OK 127.0.0.1:6001> get test "chenqm"
可以看到主机执行写命令,从机能同步主机的值,主从复制,读写分离就实现了。
万一主机挂了怎么办,这是个麻烦事情,所以redis提供了一个sentinel(哨兵),以此来实现主从切换的功能,类似与zookeeper。
注意:配置文件的位置,根据实际情况更改
启动三个哨兵
哨兵sentinel官网链接:https://redis.io/topics/sentinel
master的sentinel.conf
port 26279 entinel monitor mymaster 127.0.0.1 6000 2 sentinel auth-pass mymaster 123456
slave1的sentinel.conf
port 26379 entinel monitor mymaster 127.0.0.1 6000 2 sentinel auth-pass mymaster 123456
slave2的sentinel.conf
port 26479 sentinel monitor mymaster 127.0.0.1 6000 2 sentinel auth-pass mymaster 123456
启动方式一:
如果您使用的是redis-sentinel可执行文件(或者如果您的可执行文件具有该名称的符号链接redis-server),则可以使用以下命令行运行Sentinel:
redis-sentinel /path/to/sentinel.conf
启动方式二:
redis-server sentinel.conf --sentinel
查看日志
[7014] 11 Jan 19:42:30.918 # +monitor master mymaster 127.0.0.1 6000 quorum 2 [7014] 11 Jan 19:42:30.923 * +slave slave 127.0.0.1:6002 127.0.0.1 6002 @ mymaster 127.0.0.1 6000 [7014] 11 Jan 19:42:30.925 * +slave slave 127.0.0.1:6001 127.0.0.1 6002 @ mymaster 127.0.0.1 6000
从对应的日志观察到,一个master服务,两个slave服务。
新开一个命令行窗口进入redis的src目录,用redis-cli工具登录其中一个哨兵
redis-cli -p 26379
连接成功后运行如下命令
sentinel master mymaster
ps -ef|grep [r]edis kill -9 PID
查看日志
[7014] 11 Jan 19:43:41.463 # +sdown master mymaster 127.0.0.1 6000 [7014] 11 Jan 19:46:42.379 # +switch-master mymaster 127.0.0.1 6000 127.0.0.1 6001
master切换了,当6000端口的这个服务重启的时候,他会变成6001端口服务的slave。
因为sentinel在切换master的时候,把对应的sentinel.conf和redis.conf文件的配置修改。
期间我们还需要关注的一个问题:sentinel服务本身也不是万能的,也会宕机,所以我们还得部署sentinel集群,象我这样多启动几个sentinel。
注意这个配置:
sentinel monitor mymaster 127.0.0.1 6000 2 //这个后面的数字2,是指当有两个及以上的sentinel服务检测到master宕机,才会去执行主从切换的功能。
标签:nat 增量 插入数据 完成 for循环 redis事务 exists 良好的 半径
原文地址:https://www.cnblogs.com/happy-king/p/9218240.html
