标签:ural == article height 两种 特点 地方 推广 http
卷积神经网络是多层感知机的变种,由生物学家休博尔和维瑟尔在早期关于猫视觉皮层的研究发展而来。视觉皮层的细胞存在一个复杂的构造,这些细胞对视觉输入空间的子区域非常敏感,我们称之为感受野。
通常神经认知机包含特征提取的采样元和抗变形的卷积元,采样元中涉及两个重要参数,即感受野与阈值参数,前者确定输入连接的数目,后者控制对特征子模式的反应程度。卷积神经网络可以看作神经认知机的推广。
卷积神经网络成功的关键在于它采用了局部连接(传统神经网络中每个神经元与图片上每个像素相连接)和权值共享(卷积过程中卷积核的权重不变)的方式,一方面减少了权值的数量使得网络易于优化,另一方面降低了过拟合的风险。
CNN的特征提取层参数是通过训练数据学习得到的,所以其避免了人工特征提取,而是从训练数据中进行学习;同一特征图的神经元共享权值,减少了网络参数,这也是卷积神经网络相对于全连接网络的一大优势。
CNN一般采用卷积层与采样层交替设置,即一层卷积层接一层采样层,采样层后接一层卷积层……,这样卷积层提取出特征,再进行组合形成更抽象的特征,最后形成对图片对象的特征描述。
下采样层(Down-Pooling)也称池化层,一般包含平均池化和最大池化。最大池化(Pooling)采样,它是一种非线性降采样方法,其在计算机视觉中的价值主要体现在两个方面:(1)它减小了来自上层隐藏层的计算复杂度;(2)这些池化单元具有平移不变性;由于增强了对位移的鲁棒性,因此是一个高效的降低数据维度的采样方法。
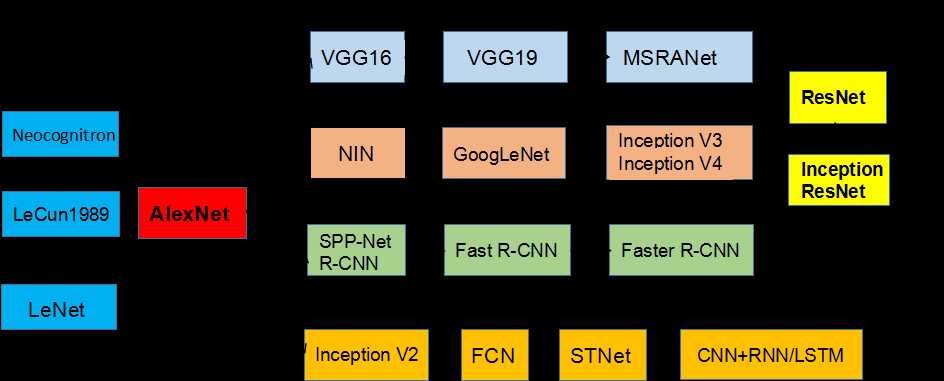
CNN的演化路径可以总结为以下几个方向:
1.从LeNet到Alex-Net
2.网络结构加深
3.加强卷积功能
4.从分类到检测
5.新增功能模块
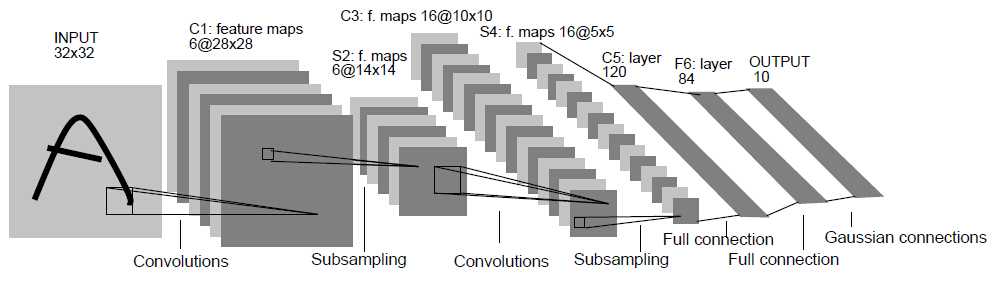
作为CNN的开端,LeNet包含了卷积层,池化层,全连接层,这些都是现代CNN网络的基本组件。
输入尺寸:32*32
卷积层:3个
降采样层:2个
全连接层:1个
输出:10个类别(数字0~9的概率)
Inuput(32*32)
输入图像Size为32*32,比mnist数据库中最大的字幕(28*28)还大,这样做的目的是希望潜在的明显特征能够出现在最高层特征监测子感受野的中心。
C1,C3,C5(卷积层)
卷积运算可以理解为滤波操作(参考Stanford CS131),通过卷积运算,可以使原信号特征增强,并且降低噪声。
S2,S4(池化层)
池化层,也称下采样层,是为了降低网络训练参数及模型的过拟合程度,通常有Max-Pooling和Mean-Pooling两种方式。
深度学习的鼻祖Hinton(http://study.163.com/course/introduction.htm?courseId=1003842018)和他的学生Alex Krizhevsky 在2012年ImageNet Challenge使用的模型,刷新了Image Classification的记录,从此深度学习进入了一个新时代;
AlexNet的网络结构如下图所示,总共包含8层,其中前5层为卷积层,后3层为全连接层,输入为1000个分类,一个完整的卷积层通常包含一层convolution,一层Rectified Linear Units,一层max-pooling,一层normalization,AlexNet完整的网络模型如图1所示,为了加快训练,使用了2个GPU;
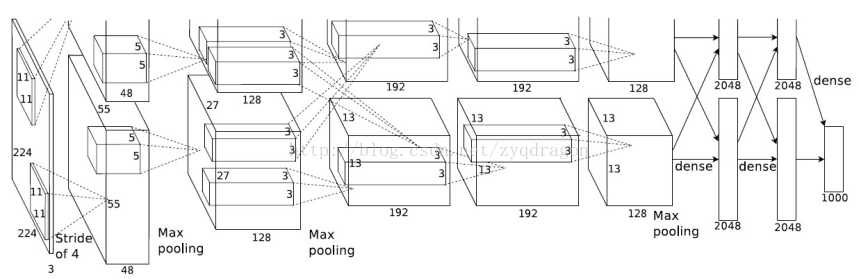
图1 AlexNet网络模型
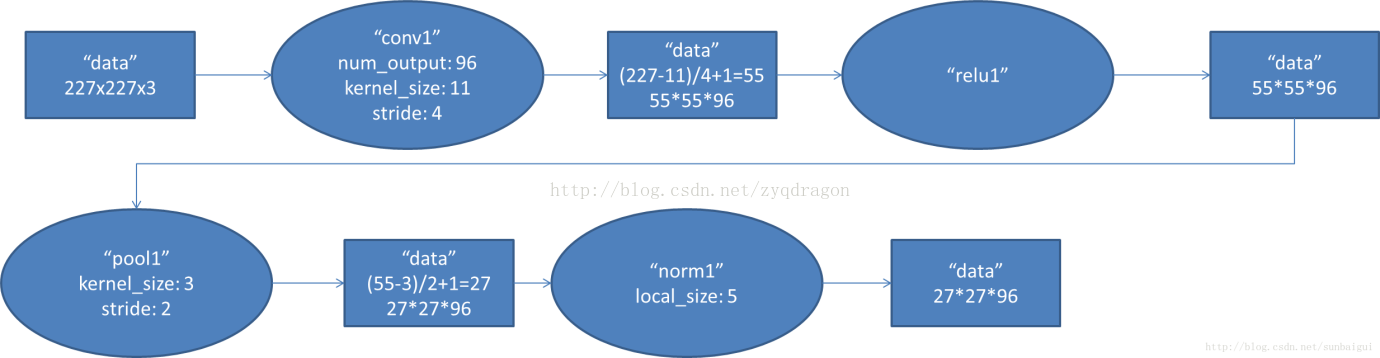
Conv1对应的数据流图如下,AlexNet首先256*256*3的RGB图像进行数据增强,对于输入的图像随机提取224*224*3,并对数据进行horizontal reflections变换,使得数据集增大了2048倍,随后经过预处理变为227*227*3的训练数据;
使用96个11*11的卷积核进行卷积运算(每个GPU 48个卷积核),步长为4,对应的输出尺寸为(227+2*0-11)/4+1=55,随后使用3*3的池化层进行下采样,步长为2,对应的输出尺寸为(55+2*0-3)/2+1=27;
图2 Conv1数据流图
Conv2对应的数据流图如下
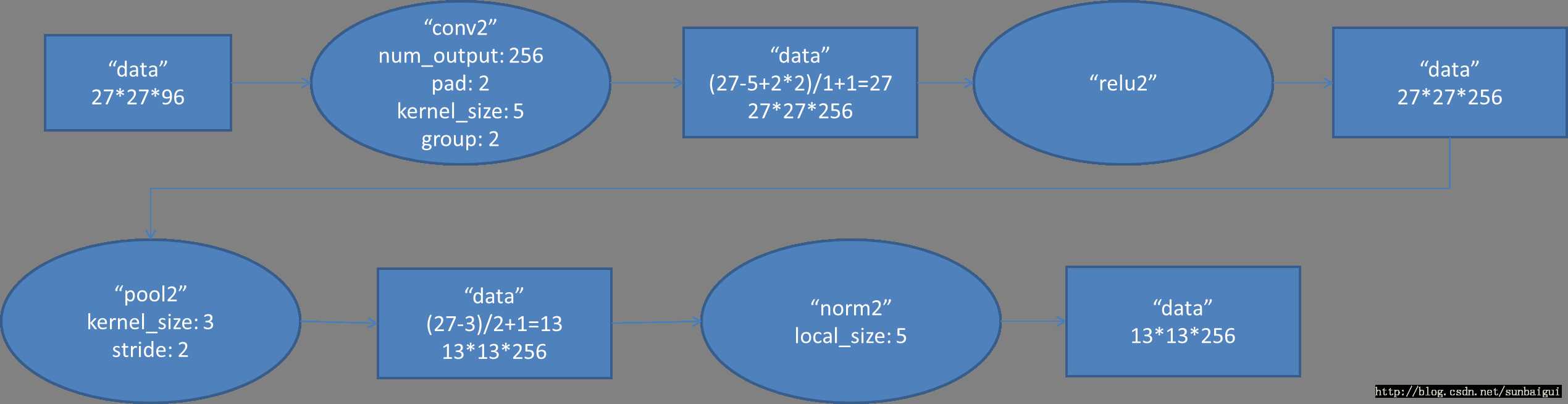
图3 Conv2数据流图
Conv3对应的数据流图如下

图4 Conv3数据流图
Conv4对应的数据流图如下

图5 Conv4数据流图
Conv5对应的数据流图如下
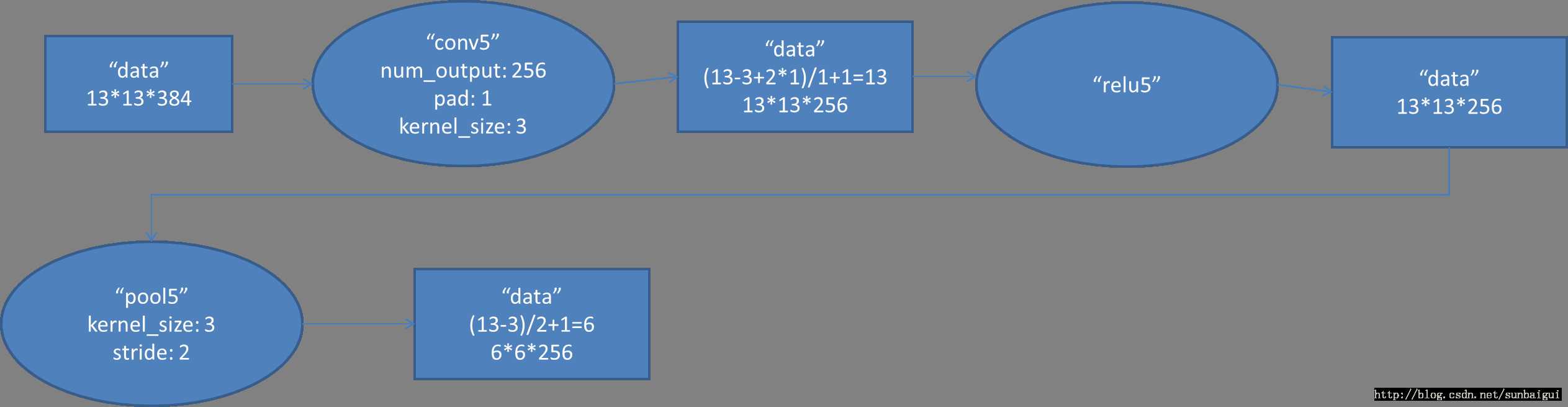
图6 Conv5数据流图
Fc6对应的数据流图如下
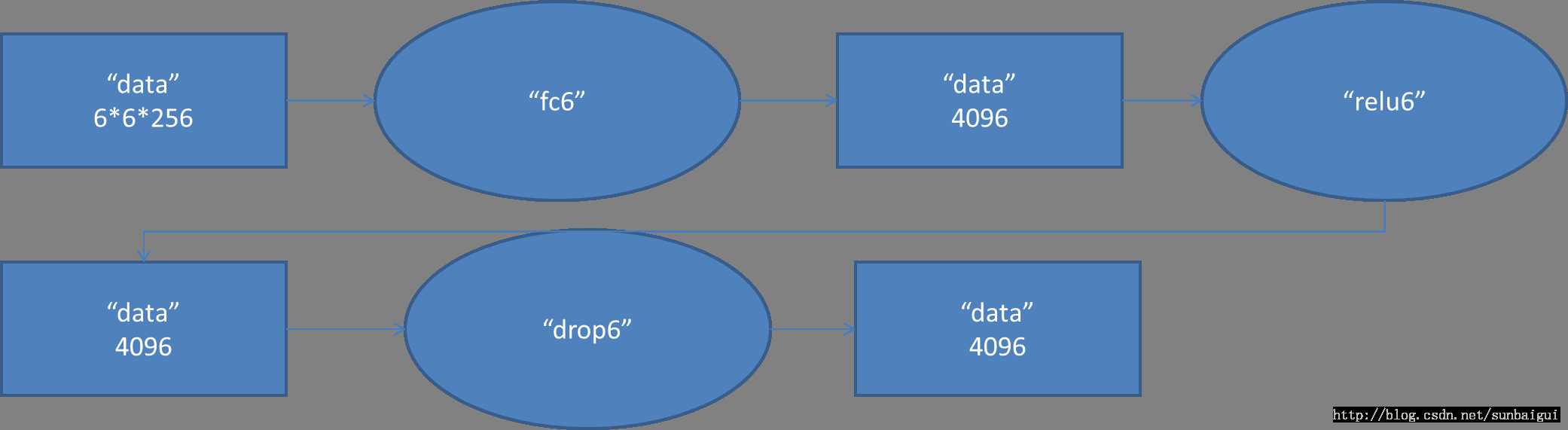
图7 Fc6数据流图
Fc7对应的数据流图如下
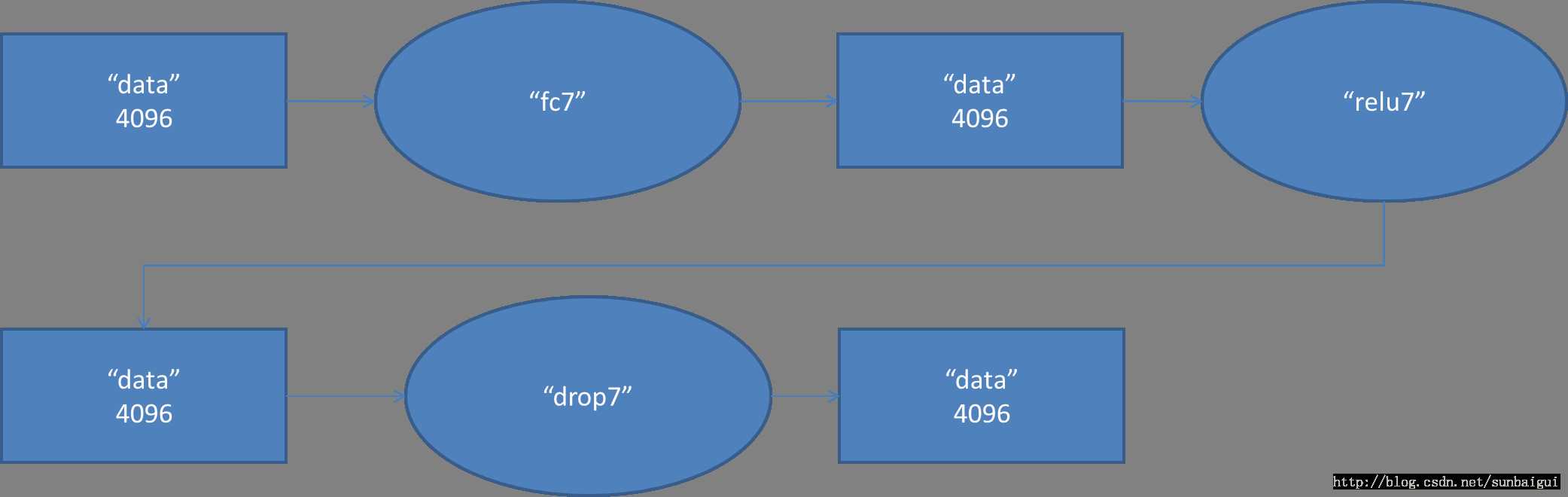
图8 Fc7数据流图
Fc8对应的数据流图

图9 Fc8数据流图
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,也意味着巨量的参数,但是巨量参数容易产生过拟合同时也大大增加了计算量。2014年《Going deeper with convolutions》一文中提出解决这两个问题的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。另一方面有文献指出,对于大规模稀疏的神经网路,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。这点表明臃肿的稀疏网络可能被不失性能地简化。
所以优化的目标就变成了:既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。据此论文提出了Inception的结构来实现此目的。
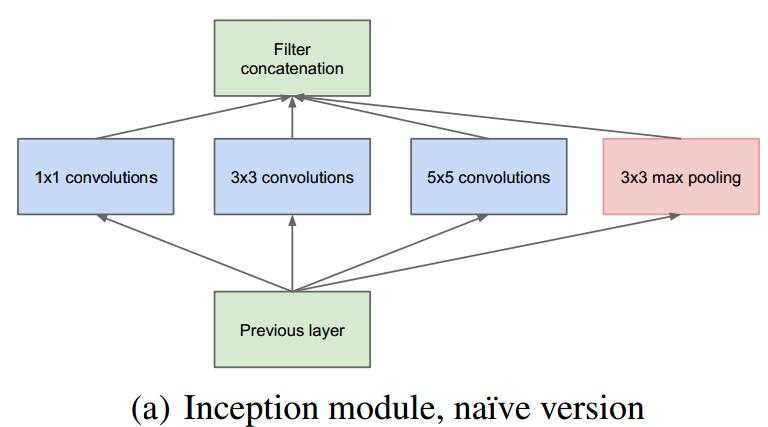
对于上图作如下说明:
1.采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2.选择卷积核大小为1、3、5,同时设定步长stride=1,并设定padding=0、1、2,那么卷积之后便可以得到相同的尺寸,方便拼接在一起。
3.pooling在减少计算参数量并降低过拟合的风险,因此在Inception中也引用了pooling;
4.网络越到后面,特征越抽象,并且每个特征所涉及的感受野也更大了,同时随着层数的增加,3*3和5*5卷积的比例也相应的增加;
5.使用5*5的卷积核仍然会带来巨大的计算量,为此,文章借鉴NIN,采用1*1的卷积核进行降维;
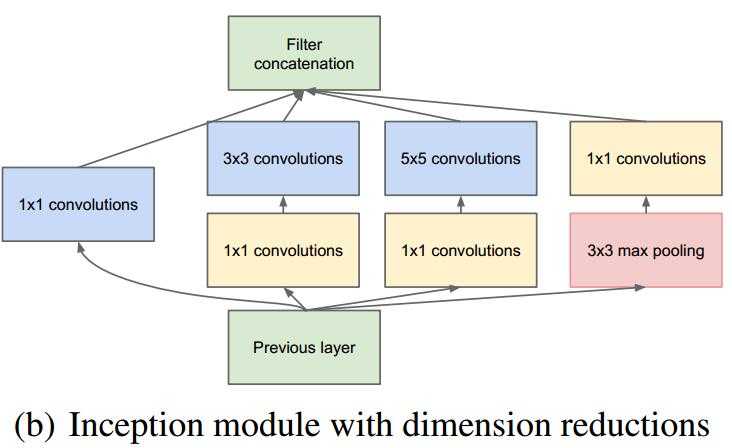
改进后的GoogLeNet框架如下图所示:
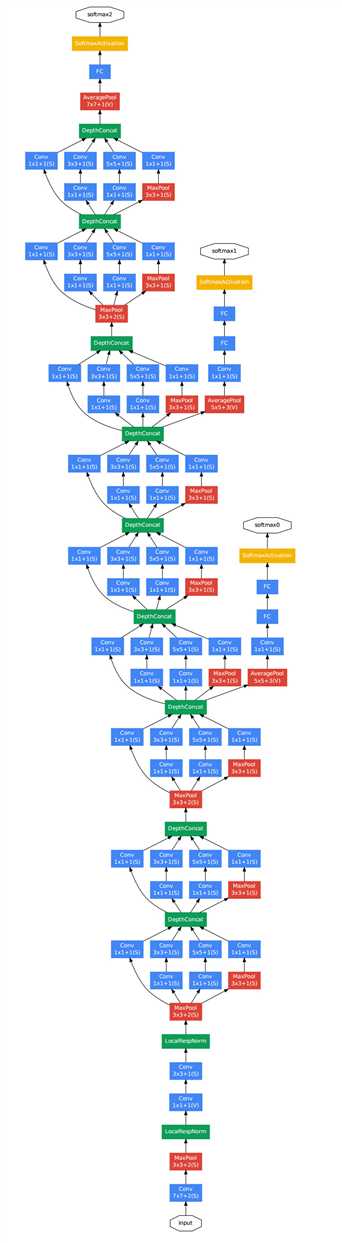
GoogLeNet整体连接图如下图所示
对上图作如下说明:
1.网络最后采用了average pooling 替代全连接层,事实证明可以将Top1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便后续finetune;
2.虽然移除了全连接,但是网络中依然使用了Dropout;
3.为了避免梯度弥散,网络额外增加了2个辅助的softmax用于向前传导梯度。
经过实验得到的准则:
1.避免表达瓶颈,特别是在网络靠前的地方。信息流向前传播过程中不能经过高度压缩的层。
2.高维特征更容易处理。高维特征更易区分,会加快训练。
3.可以在低纬嵌入上进行空间汇聚而无需担心丢失很多信息。
4.平衡网络的宽度与深度
大尺寸的卷积核可以带来更大的感受野,但也意味着更多的参数,比如5*5卷积核是3*3卷积核的2.78倍。为此,作者提出可以用两个连续的3*3卷积层(stride=1)组成的小网络来代替单个的5*5卷积层。
参考文献
https://blog.csdn.net/shuzfan/article/details/50738394
http://blog.csdn.net/cyh_24/article/details/51440344
https://blog.csdn.net/sunbaigui/article/details/39938097
http://www.cnblogs.com/gongxijun/p/6027747.html
http://blog.sina.com.cn/s/blog_6a8198dc0102v9yu.html
标签:ural == article height 两种 特点 地方 推广 http
原文地址:https://www.cnblogs.com/WaitingForU/p/9039034.html