标签:image 整合 不用 png curl Scrapyd 很多 运行 scrapy
毕设刚答辩完毕,不用担心查重了,所以补一篇毕设的内容。
毕设是图片搜索网站,使用python爬虫获取图片资源,再由javaweb管理使用图片的信息和图片,大部分实现起来十分简单,也不好意思炫耀。但是有些地方还是有自己的想法,所以记下来供以后参考。
创新之处就在于整合了SSH和scrapy两个相互独立的框架,整合好的框架图如下:
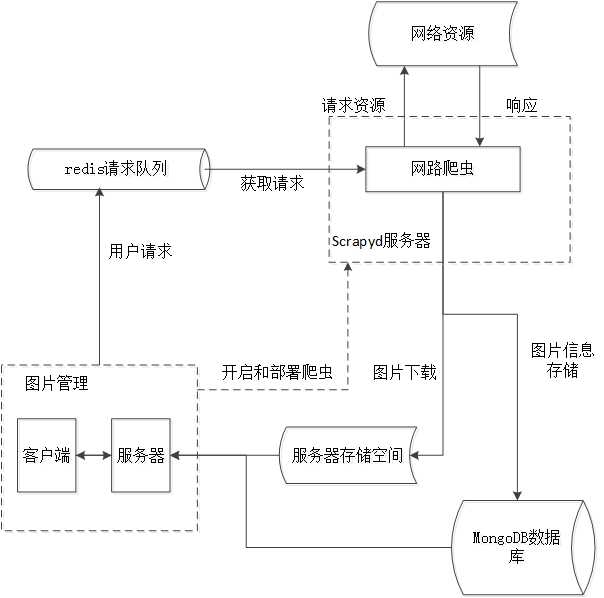
方法是把写好的scrapy爬虫部署到scrapyd应用程序上,关于scrapyd应用程序的安装网上有很多资料,然后是启动和关闭爬虫,是通过控制台运行curl命令实现的,关于curl网上也有很多资料。
对于两个框架之间的传值是通过数据库实现的。
这样做的优点是两个独立的模块可以同运行,增快整体的速度,其次后期维护起来十分方便,这就是解耦带来的好处。
标签:image 整合 不用 png curl Scrapyd 很多 运行 scrapy
原文地址:https://www.cnblogs.com/zhxuxu/p/9217679.html