标签:残差 tick numpy content split idt 糖尿病 结果 数据库
Scikit-learn是个简单高效的数据分析工具,它其中封装了大量
的机器学习算法,内置了大量的公开数据集,并且拥有完善的文档。
1 用KNN算法实现鸢尾花的分类
鸢尾花是在模式识别文献中最有名的数据库。数据集包含3个类,每类有50个实例,每个类指向一种类型的鸢尾花。一类与另外两类线性分离,而后者不能彼此线性分离。
鸢尾花数据集特征:
属性数量: 4 (数值型,数值型,帮助预测的属性和类)
| 属性信息: |
|---|
| sepal length 萼片长度(厘米) |
| sepal width 萼片宽度(厘米) |
| petal length 花瓣长度(厘米) |
| petal width 花瓣宽度(厘米) |
| 类别: |
|---|
| Iris-Setosa 山鸢尾 |
| Iris-Versicolour 变色鸢尾 |
| Iris-Virginica 维吉尼亚鸢尾 |
步骤1 用sklearn中的load_iris读取数据集,查看特征值的前两行和分类情况。
import numpy as np
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris =datasets.load_iris()
iris_X=iris.data#特征值
iris_y=iris.target#分类
print(iris_X[:2,:])
print(iris_y)运行结果:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
步骤2 把所有的数据集按7:3的比例分为训练数据集和测试数据集。输出的y_train被分开并且打乱了顺序。
X_train,X_test,y_train,y_test=train_test_split(iris_X,iris_y,test_size=0.3)
print(y_train)运行结果:
[0 0 2 1 1 1 0 0 0 2 0 0 1 1 0 2 1 0 2 2 2 2 1 0 1 2 0 0 1 0 0 1 0 2 0 0 2 2 2 2 2 0 1 1 2 2 2 1 0 1 0 0 1 2 1 2 1 0 1 0 0 0 2 2 0 0 1 2 0 2 1 0 0 0 1 2 2 1 0 1 1 2 1 2 0 1 0 1 1 0 1 0 1 2 2 2 2 0 1 0 1 2 0 1 0]
步骤3 进行分类训练和测试。在测试时,knn.predict(X_test)为测试集特征的预测值,把它和测试集的真实值做比较。
knn=KNeighborsClassifier()
knn.fit(X_train,y_train)
print(knn.predict(X_test))
print(y_test)运行结果:
[2 0 2 0 0 0 1 2 1 0 2 1 2 2 1 0 0 2 0 1 2 2 0 1 2 1 2 1 2 2 0 1 0 1 0 2 0 1 0 1 0 2 1 0 2]
[2 0 2 0 0 0 1 2 1 0 2 1 2 2 1 0 0 2 0 1 2 2 0 1 2 1 1 1 2 2 0 1 0 1 0 2 0 1 0 1 0 2 1 0 2]
最终预测的分类和实际的分类很接近,但是还是存在一点错误。
2 Scikit-learn线性回归预测糖尿病
糖尿病数据集是在442例糖尿病患者中获得了十个基线变量,年龄,性别,体重,平均血压和六个血清测量值,以及兴趣爱好,基线后一年的疾病进展的定量测量。
线性回归:给定数据集中每个样本及其正确答案,根据给定的训练数据训练一个模型函数h(hypothesis,假设),目标是找到使残差平方和最小的那个参数。
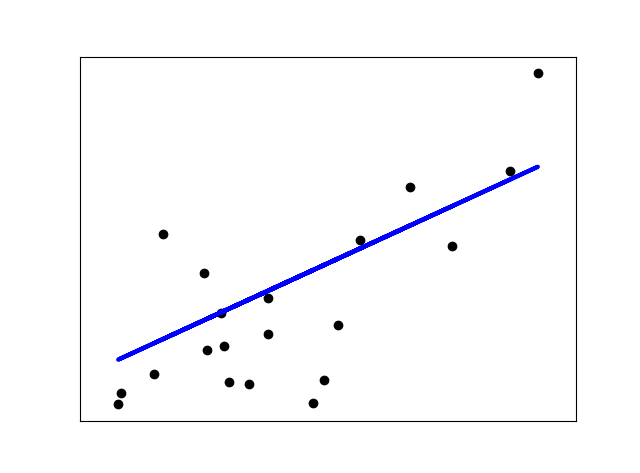
本例中为了阐述线性回归的二维图,只使用了糖尿病数据集的第一个特征。本例将会训练出一条直线,使得预测值和正确答案的残差平方和最小。最后还计算参数,残差平方和和方差分数。
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# 载入糖尿病数据集
diabetes = datasets.load_diabetes()
# 只使用数据集的第一个特征
diabetes_X = diabetes.data[:, np.newaxis, 2]
# 把特征分为训练数据集和测试数据集
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# 把类型分为训练数据集和测试数据集
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# 创建一个线性回归对象
regr = linear_model.LinearRegression()
# 用训练数据集训练模型
regr.fit(diabetes_X_train, diabetes_y_train)
# 用测试数据集做预测
diabetes_y_pred = regr.predict(diabetes_X_test)
# 回归方程的系数
print(‘Coefficients: \n‘, regr.coef_)
# 均方误差
print("Mean squared error: %.2f"
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# 解释方差分数:1代表预测的好
print(‘Variance score: %.2f‘ % r2_score(diabetes_y_test, diabetes_y_pred))
# 画出二维的测试数据集图形
plt.scatter(diabetes_X_test, diabetes_y_test, color=‘black‘)
# 画出拟合图形
plt.plot(diabetes_X_test, diabetes_y_pred, color=‘blue‘, linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()运行结果:
Coefficients:
[938.23786125]
Mean squared error: 2548.07
Variance score: 0.47
感谢您的阅读,如果您喜欢我的文章,欢迎关注我哦

标签:残差 tick numpy content split idt 糖尿病 结果 数据库
原文地址:http://blog.51cto.com/13820241/2132442