标签:实时 com ast 2.7 highlight 内存 home 集群计算 模块
Apache Spark 一个很快多用途的集群计算系统。提供了很多语言API :Java, Scala, Python and R,还支持很多高级的工具,包括Spark SQL用于SQL和结构化数据的处理,MLlib机器学习,GraphX 用于图形处理和Spark Streaming. 总的说:Spark 支持离线计算、实时计算、机器学习。
Spark为什么快呢,
1、如果没有需要,Spark处理的数据可以一直在内存直至该条数据计算结束。Hadoop MR M->R过程 需要shuffle 磁盘
2、task启动时间比较快,Spark是fork出线程;而MR是启动一个新的进程
Spark会根据任务去切分stage(根据宽依赖和窄依赖),每个STAGE 都会是一个线程、一个task。hadoop 总的是分成map和reduce两个过程(这边不谈 combine sort 等过程),而spark 根据代码 把一个job 分成若干个stage,每个stage 处理不同阶段的数据。
Spark 主要分为 Master 和 Worker 两个模块,Master 主要是管理,Worker 跑一些 Job
1、准备
下载 Spark tar包(spark-2.2.1-bin-hadoop2.7.tgz ),主机 ,主机安装JDK8
我这边搭建的是非HA(High Available)
2、安装
安装无非就是把服务的配置文件改一下
查看目录如下:
conf 下的目录如下,都是一些模板文件,我们需要slave.template 和 spark-env.sh.template 复制出来,并去掉template 的后缀。slaves 是Worker 的 ip 或者 域名,作用就是启动spark的时候 可以用ssh 远程启动 Worker。spark-env.sh 是Spark 的一些环境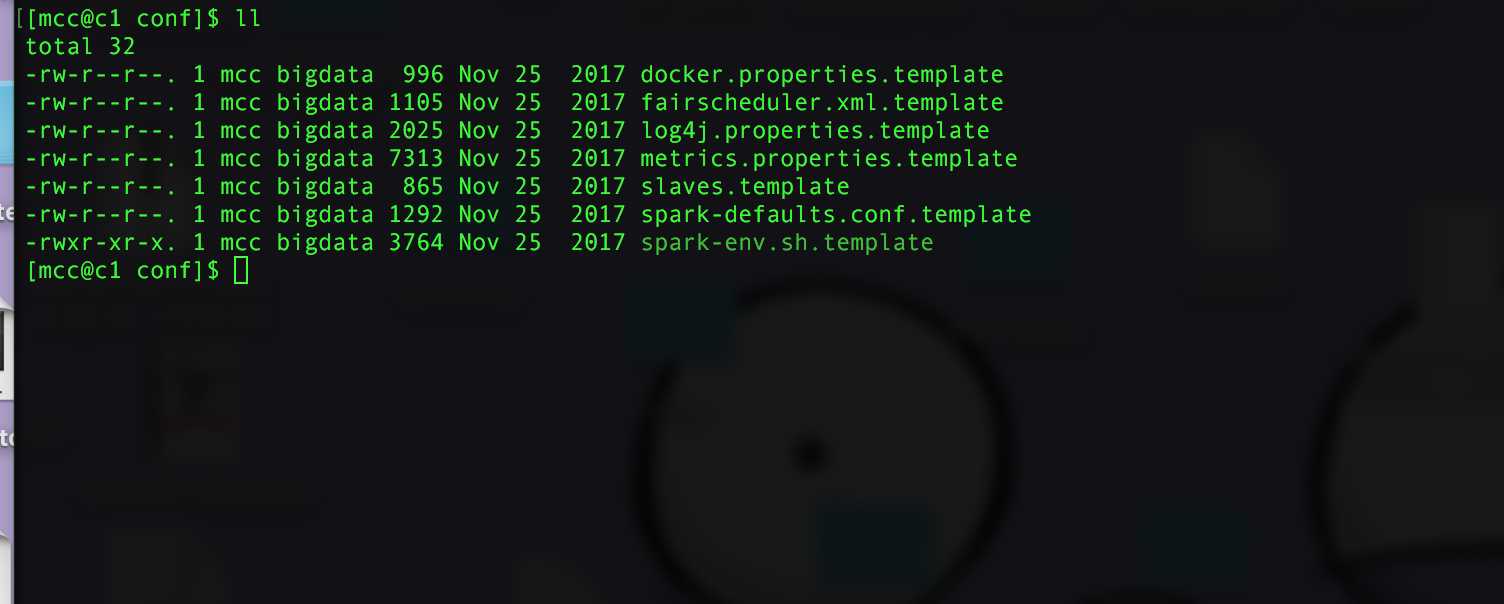
cp slave.template slave
cp spark-env.sh.template spark-env.sh
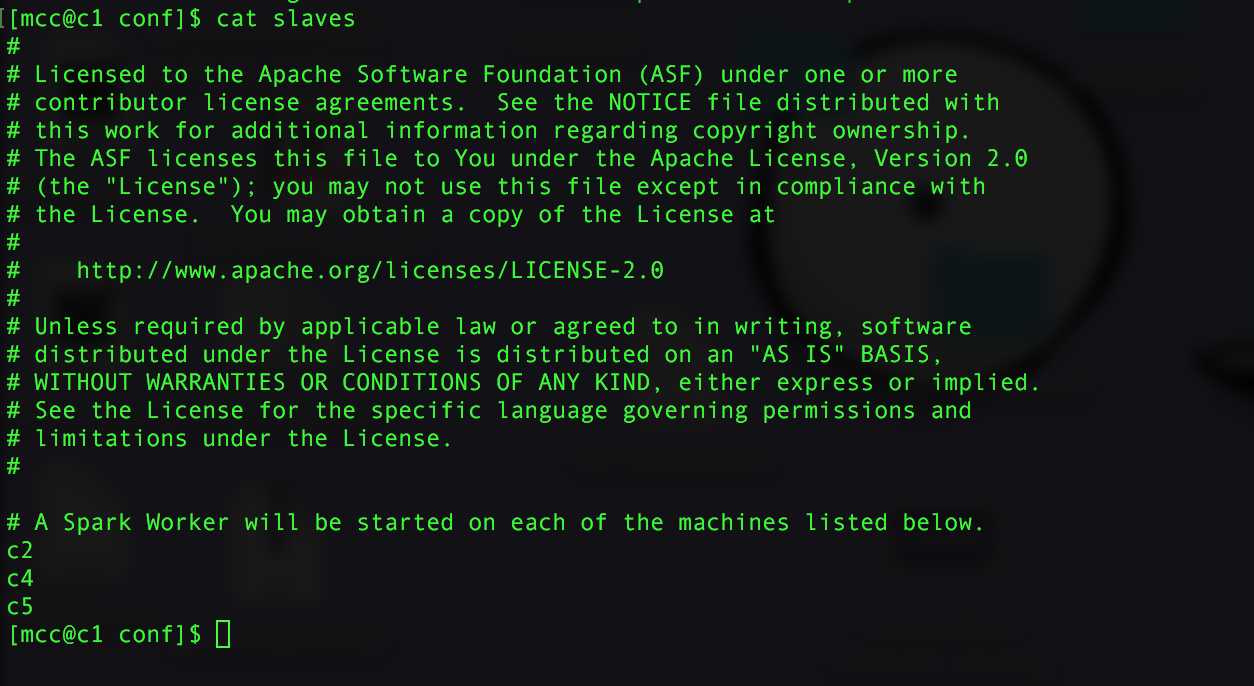
直接在文件末尾追加ip 或者 域名
我这边是配置 c2,c4,c5 为work 如果 单机就 配置 localhost 或者 127.0.0.1等
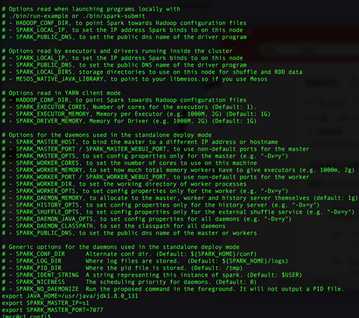
在spark-env.sh末尾追加
export JAVA_HOME=/usr/java/jdk1.8.0_131 #添加jdk环境变量 export SPARK_MASTER_IP=s1 #添加master ip 或者 域名 export SPARK_MASTER_PORT=7077 #master 通信端口
启动
运行spark目录下的sbin/start-all.sh(PS:内网的话,关掉防火墙或者一个一个的开启端口)
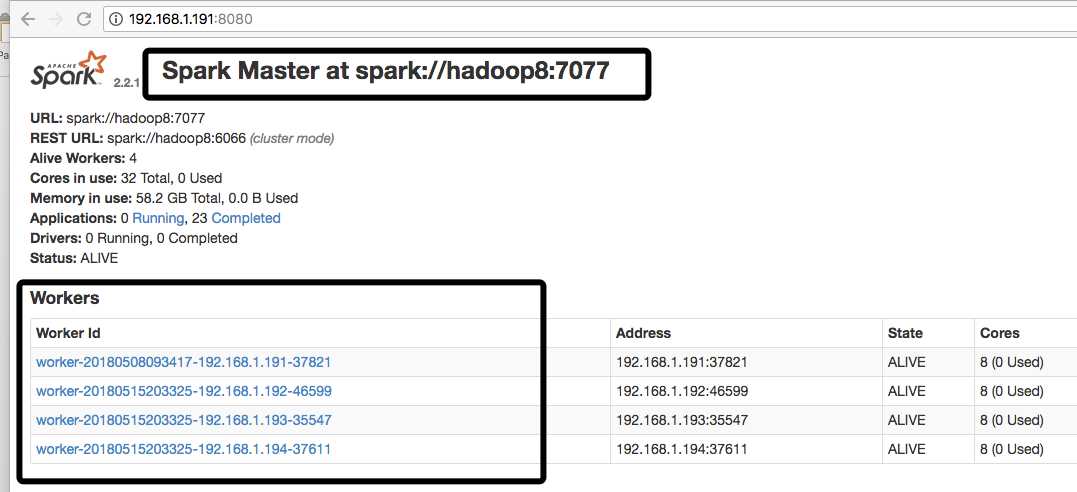
启动之后可以通过spark webui 去访问 masterIP+8080
sbin/start-all.sh
标签:实时 com ast 2.7 highlight 内存 home 集群计算 模块
原文地址:https://www.cnblogs.com/eggplantpro/p/9235288.html