标签:思想 ima auto 之间 计算 经典 一起 size 技术
一、K-means
非监督学习中有一大类问题是聚类问题,其中有个经典算法:K-means,其中K代表我们事先已经知道要将数据集分成K类 。K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。 原理如下图:
二、原理
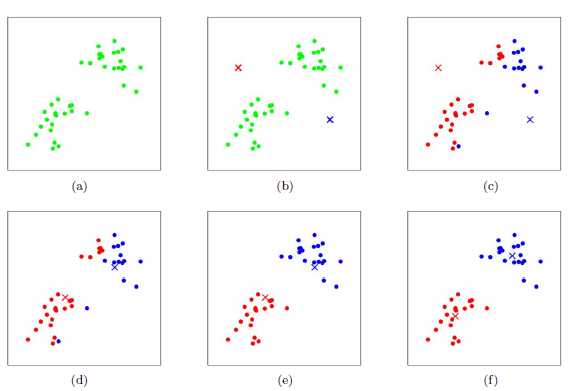
针对上图:
a表达了初始的数据集,假设k=2
b中,随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别
c所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。此时我们对我们当前标记为红色和蓝色的点分别求其新的质心
d所示,新的红色质心和蓝色质心的位置已经发生了变动
e和图f重复了我们在图c和图d的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如图f。
标签:思想 ima auto 之间 计算 经典 一起 size 技术
原文地址:https://www.cnblogs.com/always-fight/p/9238872.html