标签:kafka json 配置 depend common 启动 mod 不可 artifact
本文档基于Windows搭建本地JAVA Spark开发环境。
官网下载JDK。
注意JDK安装目录不可以包含空格,比如:C:\Java\jdk1.8.0_171,否则可能导致后续运行Spark报错(提示找不到java.exe)。
1、到spark官网网站 http://spark.apache.org/downloads.html下载spark;
注意点击红框部分进入选择下载包,不要点击截图上步骤3后面链接。
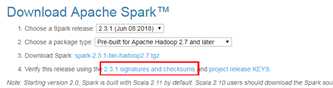
2、参考截图下载 spark-2.3.1-bin-hadoop2.7.tgz
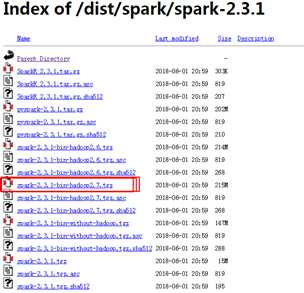
3、下载本地进行解压
比如解压后路径:D:\Tools\spark-2.3.1-bin-hadoop2.7
4、配置环境变量
1)SPARK_HOME
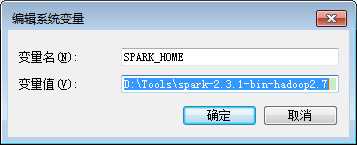
2)Path环境变量增加
%SPARK_HOME%\bin,%SPARK_HOME%\sbin
1、到 https://archive.apache.org/dist/hadoop/common/hadoop-2.7.1下载Hadoop 2.7.1;
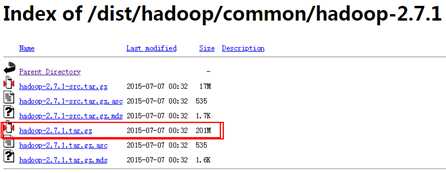
2、将下载的hadoop解压缩在本地目录;
比如:D:\Tools\hadoop-2.7.1
3、配置环境变量
1)HADOOP_HOME
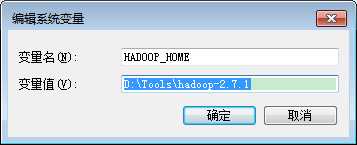
2)Path环境变量增加
%HADOOP_HOME%\bin
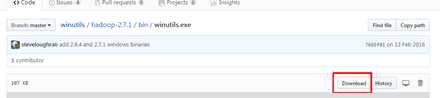
4、下载 winutils.exe 并复制到 hadoop的bin目录
https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe
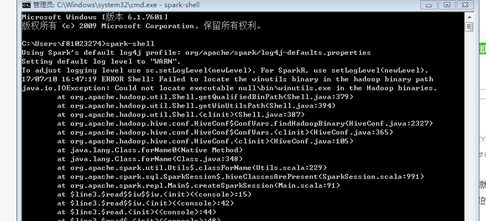
备注:如果不下载winutils.exe会导致启动spark-shell提示如下错误
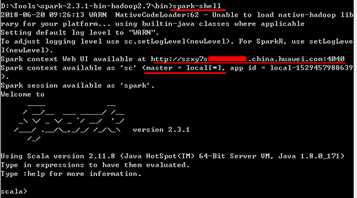
1、CMD切换到spark-2.3.1-bin-hadoop2.7\bin目录
2、运行spark-shell
如果可以看到如下界面,则代表启动成功
可以访问截图中的网址查看Spark的管理界面。
1、新建一个Maven工程
New Project -->Maven -> maven-archetype-quickstart
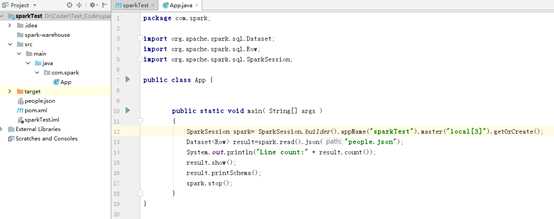
2、java源码
1 package com.spark; 2 3 import org.apache.spark.sql.Dataset; 4 import org.apache.spark.sql.Row; 5 import org.apache.spark.sql.SparkSession; 6 7 public class App { 8 9 10 public static void main( String[] args ) 11 { 12 SparkSession spark= SparkSession.builder().appName("sparkTest").master("local[3]").getOrCreate(); 13 Dataset<Row> result=spark.read().json("people.json"); 14 System.out.println("Line count:" + result.count()); 15 result.show(); 16 result.printSchema(); 17 spark.stop(); 18 } 19 }
setMaster: "local[4]" to run locally with 4 cores,
3、POM.XML配置
1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 7 <groupId>com.spark</groupId> 8 <artifactId>sparkTest</artifactId> 9 <version>1.0-SNAPSHOT</version> 10 11 <properties> 12 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> 13 <spark.version>2.3.1</spark.version> 14 <hadoop.version>2.7.1</hadoop.version> 15 </properties> 16 17 <dependencies> 18 <dependency> 19 <groupId>org.apache.spark</groupId> 20 <artifactId>spark-sql_2.11</artifactId> 21 <version>${spark.version}</version> 22 </dependency> 23 24 <dependency> 25 <groupId>org.apache.spark</groupId> 26 <artifactId>spark-core_2.11</artifactId> 27 <version>${spark.version}</version> 28 </dependency> 29 30 <dependency> 31 <groupId>org.apache.spark</groupId> 32 <artifactId>spark-hive_2.11</artifactId> 33 <version>${spark.version}</version> 34 </dependency> 35 <dependency> 36 <groupId>org.apache.spark</groupId> 37 <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> 38 <version>${spark.version}</version> 39 </dependency> 40 41 <dependency> 42 <groupId>org.apache.spark</groupId> 43 <artifactId>spark-streaming_2.11</artifactId> 44 <version>${spark.version}</version> 45 </dependency> 46 47 <dependency> 48 <groupId>org.apache.hadoop</groupId> 49 <artifactId>hadoop-common</artifactId> 50 <version>${hadoop.version}</version> 51 </dependency> 52 53 <dependency> 54 <groupId>org.apache.spark</groupId> 55 <artifactId>spark-sql-kafka-0-10_2.11</artifactId> 56 <version>${spark.version}</version> 57 </dependency> 58 59 </dependencies> 60 </project>
4、新建一个 people.json 文件,并拷贝到工程目录
文件内容如下
1 {"name":"Michael"} 2 {"name":"Andy", "age":30} 3 {"name":"Justin", "age":19}
5、(可选)优化IDEA控制台打印,使得INFO级别日志不打印
1) 拷贝spark-2.3.1-bin-hadoop2.7\conf\log4j.properties.template到当前工程src\main\resources\ log4j.properties.
2)调整日志级别
log4j.rootCategory=WARN, console
6、启动工程,查看是否可以运行看到结果

01_PC单机Spark开发环境搭建_JDK1.8+Spark2.3.1+Hadoop2.7.1
标签:kafka json 配置 depend common 启动 mod 不可 artifact
原文地址:https://www.cnblogs.com/clarino/p/9241133.html