标签:提取 相关 中心 ext none text 关键词 rank .com
摘抄自微信公众号:AI学习与实践
TextRank,它利用图模型来提取文章中的关键词。由 Google 著名的网页排序算法 PageRank 改编而来的算法。
PageRank
PageRank 是一种通过网页之间的超链接来计算网页重要性的技术,以 Google 创办人 Larry Page 之姓来命名,Google 用它来体现网页的相关性和重要性。
PageRank 通过网络浩瀚的超链接关系来确定一个页面的等级,把从 A 页面到 B 页面的链接解释为 A 页面给 B 页面投票,Google 根据 A 页面(甚至链接到 A的页面)的 等级和投票 目标的等级来决定 B 的等级。
简单的说,一个高等级的页面可以使其他低等级页面的等级提升。
整个互联网可以看作是一张有向图图,网页是图中的节点,网页之间的链接就是图中的边。如果网页 A 存在到网页 B 的链接,那么就有一条从网页 A 指向网页 B 的有向边。
构造完图后,使用下面的公式来计算网页 i的重要性(PR值):

TextRank
TextRank 公式在 PageRank 公式的基础上,为图中的边引入了权值的概念:

用 TextRank 算法计算图中各节点的得分时,同样需要给图中的节点指定任意的初值,通常都设为1。然后递归计算直到收敛,即图中任意一点的误差率小于给定的极限值时就可以达到收敛,一般该极限值取 0.0001。
使用 TextRank 提取关键词
现在是要提取关键词,如果把单词视作图中的节点(即把单词看成句子),那么所有边的权值都为 0(两个单词没有相似性),所以通常简单地把所有的权值都设为 1。
此时算法退化为 PageRank,因而把关键字提取算法称为 PageRank 也不为过。
我们把文本拆分为单词,过滤掉停用词(可选),并只保留指定词性的单词(可选),就得到了单词的集合。假设一段文本依次由下面的单词组成:
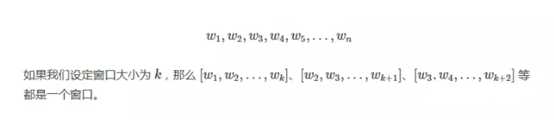
现在将每个单词作为图中的一个节点,同一个窗口中的任意两个单词对应的节点之间存在着一条边。然后利用投票的原理,将边看成是单词之间的互相投票,经过不断迭代,每个单词的得票数都会趋于稳定。
一个单词的得票数越多,就认为这个单词越重要。
使用 TextRank 提取摘要
自动摘要,就是从文章中自动抽取关键句。人类对关键句的理解通常是能够概括文章中心的句子,而机器只能模拟人类的理解,即拟定一个权重的评分标准,给每个句子打分,之后给出排名靠前的几个句子。
基于 TextRank 的自动文摘属于自动摘录,通过选取文本中重要度较高的句子形成文摘。
依然使用 TextRank 公式:

标签:提取 相关 中心 ext none text 关键词 rank .com
原文地址:https://www.cnblogs.com/lovychen/p/9242649.html