标签:决定 程序假死 大小 main 数据结构 first 项目 view lis
Java中普通的遍历方式一般常用的就是fori和foreach方式,在一般情况下这两种区别不大,往往是效率区别和有一些特殊场合注意问题,下次再详解,这次先描述关于LinkedList遍历时遇到的问题。
具体问题:
项目中需要实现接收对方频繁发送过来的数据并解析后序列化文件到目的服务器,采用了定量发送的办法,每次把接收的数据解析成功后放入到LinkedList当中,当达到目标数量时,遍历LinkedList中的数据,拼接成功想要的内容,然后序列化到目的服务器中。刚开始遍历的方法是这样的:
1 for (int i = 0; i < linkedList.size(); i++) { 2 linkedList.get(i); // 具体操作略,只表现遍历方式 3 }
咋一看没什么问题,开始测试时目标为1w也没什么问题,后面加大目标数量到10w时有明显卡顿,程序一直停顿在遍历中,一时没明白是为什么ps一起一直用ArrayList是这种遍历方式没出现过问题,仔细查看了一下LinkedList的数据结构发现了问题所在:
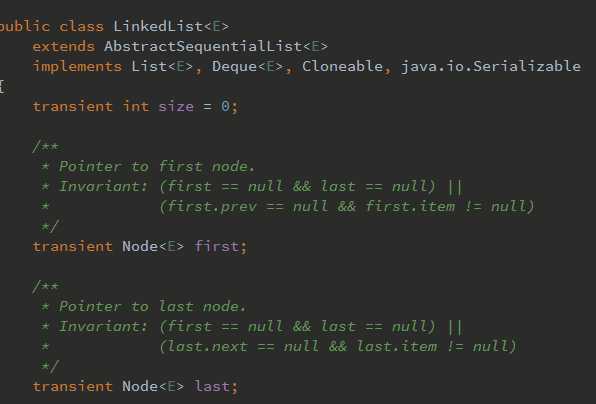
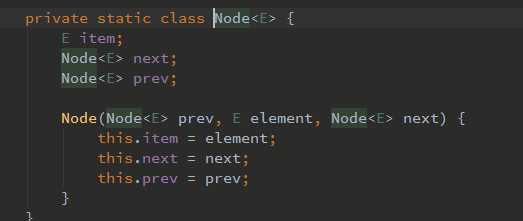
LinkedList的数据结构是双向链表,在进行get方式遍历的时候采用的方式如下:
1 public E get(int index) { 2 checkElementIndex(index); 3 return node(index).item; 4 }
checkElementIndex方法不用看具体实现,目的是判断当前元素是在链表前半段或者后半段然后决定从哪边遍历,后面的node方法决定了具体取元素的过程实现,源码如下:
1 Node<E> node(int index) { 2 // assert isElementIndex(index); 3 4 if (index < (size >> 1)) { 5 Node<E> x = first; 6 for (int i = 0; i < index; i++) 7 x = x.next; 8 return x; 9 } else { 10 Node<E> x = last; 11 for (int i = size - 1; i > index; i--) 12 x = x.prev; 13 return x; 14 } 15 }
从代码中看出,在以这种方法在遍历取元素的时候,无论目标元素在哪,都会从头部或者尾部遍历到目标节点然后取出。这种方式在链表遍历中其实是不太合理的,试想一下简单的遍历,加入有10个元素的一个链表需要遍历,那么每次元素的查询次数为
[1,2,3,4,5,5,4,3,2,1]总次数为30,时间复杂度计算方式为(n*1+(n/2)*(n/2-1)*1/1)*2渐进时间复杂度即n趋向于无穷大时约等于O(n^2).当目标数量n越大时,时间复杂度的增长也就越快,从而导致了程序假死。
分析完问题,那么来查看一下如何解决问题,不能使用fori遍历那应该采用什么方式遍历比较好呢,下面采用了3种方式遍历一个10000个元素的链表,比较了不同方式的时间花费:

public class TestLinkedList { public static void main(String[] args) { LinkedList<Integer> linkedList = getList(); iterateByFori(linkedList); iterateByForEach(linkedList); iterateByIterator(linkedList); } private static LinkedList<Integer> getList(){ LinkedList<Integer> linkedList = new LinkedList<>(); for (int i = 0; i < 100000; i++) { linkedList.add(i); } return linkedList; } //fori方式 private static void iterateByFori(LinkedList<Integer> linkedList){ long time1 = System.currentTimeMillis(); for (int i = 0; i < linkedList.size(); i++) { linkedList.get(i); } long time2 = System.currentTimeMillis(); System.out.println("Fori方式遍历的时间花费为:"+(time2-time1)); } //foreach方式 private static void iterateByForEach(LinkedList<Integer> linkedList){ long time1 = System.currentTimeMillis(); for (Integer j:linkedList) { //TODO } long time2 = System.currentTimeMillis(); System.out.println("foreach方式遍历的时间花费为:"+(time2-time1)); } //Iterator方式 private static void iterateByIterator(LinkedList<Integer> linkedList){ long time1 = System.currentTimeMillis(); Iterator<Integer> iterator = linkedList.iterator(); while (iterator.hasNext()){ iterator.next(); } long time2 = System.currentTimeMillis(); System.out.println("Iterator方式遍历的时间花费为:"+(time2-time1)); } }
分别一次采用了fori方式、foreach方式以及Iterator方式遍历(自带的removeFirst等方法在这里不做讨论),结果如下:
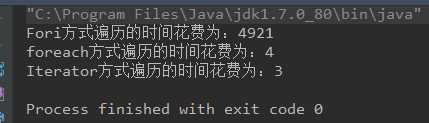
从图中可以可以看出时间花费的差别大小,所以在链表结构实现的数据集合中,最好采用Iterator或者foreach的方式遍历,效率最高。
标签:决定 程序假死 大小 main 数据结构 first 项目 view lis
原文地址:https://www.cnblogs.com/gsm340/p/9243916.html
