标签:bubuko 相加 led next clu rman efi 输入输出 dog
本篇主要详解spark具体编程实践中的rdd常用算子。
RDDs support 两种类型的操作: transformations(转换), 它会在一个已存在的 dataset 上创建一个新的 dataset, 和 actions(动作), 将在 dataset 上运行的计算后返回到 driver 程序. 例如, map 是一个通过让每个数据集元素都执行一个函数,并返回的新 RDD 结果的 transformation, reduce reduce 通过执行一些函数,聚合 RDD 中所有元素,并将最终结果给返回驱动程序(虽然也有一个并行 reduceByKey 返回一个分布式数据集)的 action.
Spark 中所有的 transformations 都是 lazy(懒加载的), 因此它不会立刻计算出结果. 相反, 他们只记得应用于一些基本数据集的转换 (例如. 文件). 只有当需要返回结果给驱动程序时,transformations 才开始计算. 这种设计使 Spark 的运行更高效. 例如, 我们可以了解到,map 所创建的数据集将被用在 reduce 中,并且只有 reduce 的计算结果返回给驱动程序,而不是映射一个更大的数据集.
默认情况下,每次你在 RDD 运行一个 action 的时, 每个 transformed RDD 都会被重新计算。但是,您也可用 persist (或 cache) 方法将 RDD persist(持久化)到内存中;在这种情况下,Spark 为了下次查询时可以更快地访问,会把数据保存在集群上。此外,还支持持续持久化 RDDs 到磁盘,或复制到多个结点。
Tranformation常用操作实例
map(func)
含义:
通过将一个函数应用于该RDD的所有元素,返回一个新的RDD。一个元素对应一个元素。
输入输出:
def map[U: ClassTag](f: T => U): RDD[U]
示例:
如下,b将RDD[String]转换为RDD[Int],c将RDD[String]转换为RDD[(String,Int)]
scala> val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
a: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[3] at parallelize at <console>:25
scala> val b = a.map(_.length)
b: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at map at <console>:27
scala> b.collect()
res1: Array[Int] = Array(3, 6, 6, 3, 8)
scala> val c= a.map(x=>(x,x.length))
c: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[5] at map at <console>:27
scala> c.collect()
res2: Array[(String, Int)] = Array((dog,3), (salmon,6), (salmon,6), (rat,3), (elephant,8))flatMap(func)
含义:
通过将一个函数应用于该RDD的所有元素,返回一个新的RDD。 其中flatMap函数可以一个元素对应一个或者多个元素
输入输出:
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
示例:
如下先应用元素dog先被map为(d,1),(o,1),(g,1),然后和其他map后的元素一起扁平化
scala> val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
a: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[6] at parallelize at
scala> val d=a.flatMap(x=>{
| for (i<-0 until x.length) yield (x.charAt(i),1)
| })
d: org.apache.spark.rdd.RDD[(Char, Int)] = MapPartitionsRDD[7] at flatMap at <console>:27
scala> d.collect()
res3: Array[(Char, Int)] = Array((d,1), (o,1), (g,1), (s,1), (a,1), (l,1), (m,1), (o,1), (n,1), (s,1), (a,1), (l,1), (m,1), (o,1), (n,1), (r,1), (a,1), (t,1), (e,1), (l,1), (e,1), (p,1), (h,1), (a,1), (n,1), (t,1))mapPartition(func)
Iterator<T> => Iterator<U>类型。输入输出
def mapPartitions[U:ClassTag](f:Iterator[T] =Iterator[U],preservesPartitioning:Boolean = false): RDD[U]示例
如下判断分区中两两相邻的元素,根据结果推断,可以判定(1,2,3)在一个分区,(4,5,6)在一个分区,(7,8,9)在一个分区
scala> val e = sc.parallelize(1 to 9, 3)
e: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:25
scala> def myfunc[T](iter: Iterator[T]) : Iterator[(T, T)] = {
| var res = List[(T, T)]()
| var pre = iter.next
| while (iter.hasNext)
| {
| val cur = iter.next;
| res .::= (pre, cur)
| pre = cur;
| }
| res.iterator
| }
myfunc: [T](iter: Iterator[T])Iterator[(T, T)]
scala> e.mapPartitions(myfunc).collect
res4: Array[(Int, Int)] = Array((2,3), (1,2), (5,6), (4,5), (8,9), (7,8))mapPartitionsWithIndex(func)
含义:
与 mapPartitions 类似,但是也需要提供一个代表 partition 的 index(索引)的 interger value(整型值)作为参数的 func,所以在一个类型为 T 的 RDD 上运行时 func 必须是 (Int, Iterator<T>) => Iterator<U> 类型。
输入输出:
def mapPartitionsWithIndex[U: ClassTag]( f: (Int, Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false): RDD[U]
示例:
通过mapPartitionsWithIndex可以更准确判定数据在分区中的分布情况,见运行结果
scala> val e = sc.parallelize(1 to 9, 3)
e: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:25
scala>
scala> def myfunc2(index: Int, iter: Iterator[Int]) : Iterator[String] = {
| iter.map(x => index + "," + x)
| }
myfunc2: (index: Int, iter: Iterator[Int])Iterator[String]
scala> e.mapPartitionsWithIndex(myfunc2).collect()
res5: Array[String] = Array(0,1, 0,2, 0,3, 1,4, 1,5, 1,6, 2,7, 2,8, 2,9) groupByKey(func)
含义:
在一个 (K, V) pair 的 dataset 上调用时,返回一个 (K, Iterable
输入输出:
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]示例:
将数据按照长度分组
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "spider", "eagle"), 2)
val b = a.keyBy(_.length)
b.groupByKey.collect
res11: Array[(Int, Seq[String])] = Array((4,ArrayBuffer(lion)), (6,ArrayBuffer(spider)), (3,ArrayBuffer(dog, cat)), (5,ArrayBuffer(tiger, eagle)))reduceByKey(func)
含义:
在 (K, V) pairs 的 dataset 上调用时, 返回 dataset of (K, V) pairs 的 dataset, 其中的 values 是针对每个 key 使用给定的函数 func 来进行聚合的, 它必须是 type (V,V) => V 的类型. 像 groupByKey 一样, reduce tasks 的数量是可以通过第二个可选的参数来配置的。
运行时会现在分区内进行合并操作
输入输出:
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(func: (V, V) => V): RDD[(K, V)]val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x => (x.length, x))
b.reduceByKey(_ + _).collect
res19: Array[(Int, String)] = Array((4,lion), (6,spider), (3,dogcat), (5,tigereagle))aggregateByKey(func)
含义:
在 (K, V) pairs 的 dataset 上调用时, 返回 (K, U) pairs 的 dataset,其中的 values 是针对每个 key 使用给定的 combine 函数以及一个 neutral "0" 值来进行聚合的. 允许聚合值的类型与输入值的类型不一样, 同时避免不必要的配置. 像 groupByKey 一样, reduce tasks 的数量是可以通过第二个可选的参数来配置的.
输入输出:
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)]
def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)]
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)]需要说明的是第一个函数即(U, V) => U用于在分区内部合并数据,而第二个函数(U, U) => U则用于不同分区间数据的合并
//首先根据mapPartitionsWithIndex函数查看数据的分布情况,便于后面理解计算结果
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
def myfunc(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.map(x => "[partID:" + index + ", val: " + x + "]")
}
pairRDD.mapPartitionsWithIndex(myfunc).foreach(println)
/**
* 0:(cat,2),(cat,5),(mouse,4)
* 1:(mouse,2),(dog,12),(cat,12)
* */
//先计算每个分区单个key的最大值(),然后将不同分区的值相加
pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
// res3: Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,6))
pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect
// res4: Array[(String, Int)] = Array((dog,100), (cat,200), (mouse,200))combineByKey
输入输出
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
numPartitions: Int): RDD[(K, C)]
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)]
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] 主要参数包括createCombiner、mergeValue、mergeCombiners三个函数,其对数据类型转换示意图如下:
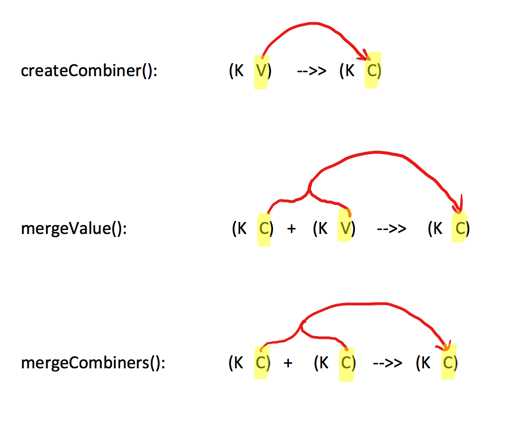
spark源码对这三个参数解释如下:
@param createCombiner function to create the initial value of the aggregation.
@param mergeValue function to merge a new value into the aggregation result.
@param mergeCombiners function to merge outputs from multiple mergeValue function.由于聚合操作会遍历分区中所有的元素,因此每个元素(键值对)的键只有两种情况,即以前出现过的和没出现过的。分区内如果没有出现过,聚合执行的是createCombiner方法,否则执行更新,即mergeValue方法。
分区间的聚合操作采用mergeCombiners方法。
示例:
根据单词长度分组
scala> val a = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
a: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[27] at parallelize at <console>:24
scala> val b = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)
b: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[28] at parallelize at <console>:24
scala> val c = b.zip(a)
c: org.apache.spark.rdd.RDD[(Int, String)] = ZippedPartitionsRDD2[29] at zip at <console>:28
scala> c.collect
res24: Array[(Int, String)] = Array((1,dog), (1,cat), (2,gnu), (2,salmon), (2,rabbit), (1,turkey), (2,wolf), (2,bear), (2,bee))
scala> val d = c.combineByKey(List(_), (x:List[String], y:String) => y :: x, (x:List[String], y:List[String]) => x ::: y)
d: org.apache.spark.rdd.RDD[(Int, List[String])] = ShuffledRDD[30] at combineByKey at <console>:30
scala> d.collect
res25: Array[(Int, List[String])] = Array((1,List(cat, dog, turkey)), (2,List(gnu, rabbit, salmon, bee, bear, wolf)))
scala>根据人名进行平均数计算
scala> import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SparkSession
scala> type ScoreCollector = (Int, Double)
defined type alias ScoreCollector
scala> type PersonScores = (String, (Int, Double))
defined type alias PersonScores
scala> val initialScores = Array(("Fred", 88.0), ("Fred", 95.0), ("Fred", 91.0), ("Wilma", 93.0), ("Wilma", 95.0), ("Wilma", 98.0))
initialScores: Array[(String, Double)] = Array((Fred,88.0), (Fred,95.0), (Fred,91.0), (Wilma,93.0), (Wilma,95.0), (Wilma,98.0))
scala> val wilmaAndFredScores = sc.parallelize(initialScores).cache()
wilmaAndFredScores: org.apache.spark.rdd.RDD[(String, Double)] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> val createScoreCombiner = (score: Double) => (1, score)
createScoreCombiner: Double => (Int, Double) = <function1>
scala> val scoreCombiner = (collector: ScoreCollector, score: Double) => {
| val (numberScores, totalScore) = collector
| (numberScores + 1, totalScore + score)
| }
scoreCombiner: (ScoreCollector, Double) => (Int, Double) = <function2>
scala> val scoreMerger = (collector1: ScoreCollector, collector2: ScoreCollector) => {
| val (numScores1, totalScore1) = collector1
| val (numScores2, totalScore2) = collector2
| (numScores1 + numScores2, totalScore1 + totalScore2)
| }
scoreMerger: (ScoreCollector, ScoreCollector) => (Int, Double) = <function2>
scala>
scala> val scores = wilmaAndFredScores.combineByKey(createScoreCombiner, scoreCombiner, scoreMerger)
scores: org.apache.spark.rdd.RDD[(String, (Int, Double))] = ShuffledRDD[1] at combineByKey at <console>:37
scala> scores.collect
res0: Array[(String, (Int, Double))] = Array((Wilma,(3,286.0)), (Fred,(3,274.0)))
scala> val averagingFunction = (personScore: PersonScores) => {
| val (name, (numberScores, totalScore)) = personScore
| (name, totalScore / numberScores)
| }
averagingFunction: PersonScores => (String, Double) = <function1>
scala> val averageScores = scores.collectAsMap().map(averagingFunction)
averageScores: scala.collection.Map[String,Double] = Map(Fred -> 91.33333333333333, Wilma -> 95.33333333333333)需要说明的groupByKey,reduceByKey,aggregateByKey,以及foldByKey都是通过调用combineByKey(combineByKeyWithClassTag)来实现的,具体实现方式可以参考org.apache.spark.rdd.PairRDDFunctions类。
foldByKey(func)
含义:
RDD[K,V]根据K将V做折叠、合并处理,其中先将zeroValue应用于V(同一个分区单个key应用一次),再将映射函数应用于处理后的V
输入输出:
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
def foldByKey(zeroValue: V, numPartitions: Int)(func: (V, V) => V): RDD[(K, V)]
def foldByKey(zeroValue: V,partitioner: Partitioner)(func: (V, V) => V): RDD[(K, V)] 示例:
scala> val aa = sc.parallelize(List( ("cat",2), ("mouse", 2),("cat", 3), ("dog", 4), ("mouse", 2), ("cat", 1)),2 )
aa: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[18] at parallelize at
scala> def myfunc(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
| iter.map(x => "[partID:" + index + ", val: " + x + "]")
| }
myfunc: (index: Int, iter: Iterator[(String, Int)])Iterator[String]
scala> aa.mapPartitionsWithIndex(myfunc).foreach(println)
[partID:1, val: (dog,4)]
[partID:0, val: (cat,2)]
[partID:1, val: (mouse,2)]
[partID:0, val: (mouse,2)]
[partID:1, val: (cat,1)]
[partID:0, val: (cat,3)]
scala> aa.foldByKey(0)(_+_).collect()
res10: Array[(String, Int)] = Array((dog,4), (cat,6), (mouse,4))
scala> aa.foldByKey(2)(_+_).collect()
res11: Array[(String, Int)] = Array((dog,6), (cat,10), (mouse,8))
scala>
scala> val bb = sc.parallelize(List( ("cat",2), ("mouse", 2),("cat", 3), ("dog", 4), ("mouse", 2), ("cat", 1)),3 )
bb: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[22] at parallelize at <console>:25
scala> bb.mapPartitionsWithIndex(myfunc).foreach(println)
[partID:0, val: (cat,2)]
[partID:2, val: (mouse,2)]
[partID:1, val: (cat,3)]
[partID:2, val: (cat,1)]
[partID:0, val: (mouse,2)]
[partID:1, val: (dog,4)]
scala> bb.foldByKey(2)(_+_).collect()
res13: Array[(String, Int)] = Array((cat,12), (mouse,8), (dog,6))
scala> aa.foldByKey(0)(_*_).collect()
res14: Array[(String, Int)] = Array((dog,0), (cat,0), (mouse,0))
scala> aa.foldByKey(1)(_*_).collect()
res15: Array[(String, Int)] = Array((dog,4), (cat,6), (mouse,4))首先查看了aa数据的分布情况,两个分区,分区0内三个元素((cat,2),(mouse,2),(cat,3)),分区1内三个元素((dog,4),(mouse,2),(cat,1)),计算过程示意如下:
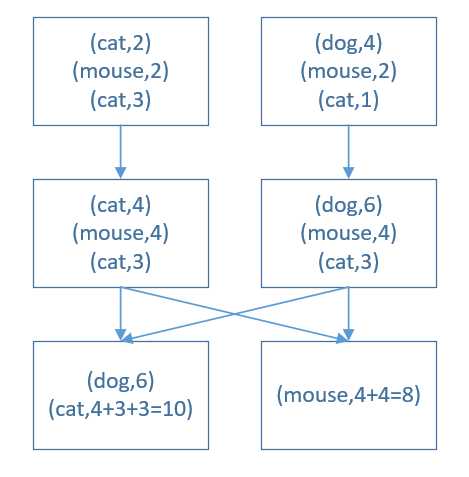
由此可见zeroValue化后,分区0中的(cat,2)变为了(cat,4),而同分区的(cat,3)没有发生变化。分区1中的(cat,1)变成了(cat,3),故cat最后的结果为10。并不是所有的元素都加2,而是同一个分区的单个元素加2。bb的结果可以对应去对比分析。
其实很好理解,foldByKey是通过调用combineByKeyWithClassTag方法实现的,zeroValue方法对应combineByKeyWithClassTag中的createCombiner,而combineByKey是通过调用org.apache.spark.Aggregator来实现的,关键源码如下:
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}分区内的计算通过调用aggregator.combineValuesByKey(iter, context),iter是单个分区的迭代器,
def combineValuesByKey(
iter: Iterator[_ <: Product2[K, V]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, V, C](createCombiner, mergeValue, mergeCombiners)
combiners.insertAll(iter)
updateMetrics(context, combiners)
combiners.iterator
}org.apache.spark.util.collection.util.collection.ExternalAppendOnlyMap中insertAll方法如下:
def insertAll(entries: Iterator[Product2[K, V]]): Unit = {
if (currentMap == null) {
throw new IllegalStateException(
"Cannot insert new elements into a map after calling iterator")
}
// An update function for the map that we reuse across entries to avoid allocating
// a new closure each time
var curEntry: Product2[K, V] = null
val update: (Boolean, C) => C = (hadVal, oldVal) => {
if (hadVal) mergeValue(oldVal, curEntry._2) else createCombiner(curEntry._2)
}
while (entries.hasNext) {
curEntry = entries.next()
val estimatedSize = currentMap.estimateSize()
if (estimatedSize > _peakMemoryUsedBytes) {
_peakMemoryUsedBytes = estimatedSize
}
if (maybeSpill(currentMap, estimatedSize)) {
currentMap = new SizeTrackingAppendOnlyMap[K, C]
}
currentMap.changeValue(curEntry._1, update)
addElementsRead()
}
}其update说明了分区内没出现过,聚合执行的是createCombiner,否则执行mergeValue。
sortByKey(func)
输入输出:
scala> val a = sc.parallelize(List( ("cat",2), ("mouse", 2),("bear", 3), ("dog", 4), ("ant", 2), ("horse", 1)),2 )
a: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[49] at parallelize at <console>:25
scala> def myfunc3(index: Int, iter: Iterator[(String,Int)]) : Iterator[String] = {
| iter.map(x => index + "," +x.toString())
| }
myfunc3: (index: Int, iter: Iterator[(String, Int)])Iterator[String]
scala> a.mapPartitionsWithIndex(myfunc3).collect().sorted.foreach(println)
0,(bear,3)
0,(cat,2)
0,(mouse,2)
1,(ant,2)
1,(dog,4)
1,(horse,1)
scala> a.sortByKey(true).mapPartitionsWithIndex(myfunc3).collect().sorted.foreach(println)
0,(ant,2)
0,(bear,3)
0,(cat,2)
1,(dog,4)
1,(horse,1)
1,(mouse,2) 常用Action算子如下:
| Action | Meaning |
|---|---|
| reduce(func) | Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect() | Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| count() | Return the number of elements in the dataset. |
| first() | Return the first element of the dataset (similar to take(1)). |
| take(n) | Return an array with the first n elements of the dataset. |
| takeSample(withReplacement, num, [seed]) | Return an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| takeOrdered(n, [ordering]) | Return the first n elements of the RDD using either their natural order or a custom comparator. |
| saveAsTextFile(path) | Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
| saveAsSequenceFile(path) (Java and Scala) | Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that implement Hadoop‘s Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| saveAsObjectFile(path) (Java and Scala) | Write the elements of the dataset in a simple format using Java serialization, which can then be loaded using SparkContext.objectFile(). |
| countByKey() | Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach(func) | Run a function func on each element of the dataset. This is usually done for side effects such as updating an Accumulator or interacting with external storage systems. Note: modifying variables other than Accumulators outside of the foreach() may result in undefined behavior. See Understanding closures for more details. |
countByKey(func)
含义:
countByKey用于统计RDD[K,V]中每个K的数量,结果以Map的形式返回到driver端。
如果结果集比较大,可以考虑用rdd.mapValues(_ => 1L).reduceByKey(_ + _)达到相同的统计目的,返回格式为RDD[T,Long]
输入输出:
def countByKey(): Map[K, Long] 示例:
scala> val aa = sc.parallelize(List( ("cat",2), ("mouse", 2),("cat", 3), ("dog", 4), ("mouse", 2), ("cat", 1)),2 )
aa: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[29] at parallelize at <console>:25
scala> aa.countByKey()
res17: scala.collection.Map[String,Long] = Map(dog -> 1, cat -> 3, mouse -> 2)
scala> aa.mapValues(_=>1).reduceByKey(_+_)
res18: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[33] at reduceByKey at <console>:28
scala> aa.mapValues(_=>1).reduceByKey(_+_).collect()
res19: Array[(String, Int)] = Array((dog,1), (cat,3), (mouse,2))
scala> aa.mapValues(_=>1).reduceByKey(_+_).collectAsMap()
res20: scala.collection.Map[String,Int] = Map(cat -> 3, dog -> 1, mouse -> 2) Accumulators(累加器)是一个仅可以执行 “added”(添加)的变量来通过一个关联和交换操作,因此可以高效地执行支持并行。累加器可以用于实现 counter( 计数,类似在 MapReduce 中那样)或者 sums(求和。
spark主要有LongAccumulator,DoubleAccumulator,CollectionAccumulator三类累加器,LongAccumulator,DoubleAccumulator主要用来数值累加,CollectionAccumulator用于list元素的累加。示例如下:
scala> import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SparkSession
scala> val spark=SparkSession.builder().appName("AccumutorTest").getOrCreate()
18/03/05 14:30:19 WARN SparkSession$Builder: Using an existing SparkSession; some configuration may not take effect.
spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@3346e906
scala> val longAccumutor=spark.sparkContext.longAccumulator("longValue")
longAccumutor: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 48, name: Some(longValue), value: 0)
scala> val doubleAccumutor=spark.sparkContext.doubleAccumulator("doubleValue")
doubleAccumutor: org.apache.spark.util.DoubleAccumulator = DoubleAccumulator(id: 49, name: Some(doubleValue), value: 0.0)
scala> val collectAccumutor=spark.sparkContext.collectionAccumulator[String]("listValue")
collectAccumutor: org.apache.spark.util.CollectionAccumulator[String] = CollectionAccumulator(id: 50, name: Some(listValue), value: [])
scala> val a = spark.sparkContext.parallelize(List( ("cat",2), ("mouse", 2),("bear", 3), ("dog", 4), ("ant", 2), ("horse", 1)),2 )
a: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[2] at parallelize at <console>:29
scala> a.foreach(x=>longAccumutor.add(x._2))
scala> longAccumutor.value
res7: Long = 14
scala> a.foreach(x=>collectAccumutor.add(x._1))
scala> collectAccumutor.value
res9: java.util.List[String] = [cat, mouse, bear, dog, ant, horse]Broadcast variables(广播变量)允许程序员将一个 read-only(只读的)变量缓存到每台机器上,而不是给任务传递一个副本。它们是如何来使用呢,例如,广播变量可以用一种高效的方式给每个节点传递一份比较大的 input dataset(输入数据集)副本。在使用广播变量时,Spark 也尝试使用高效广播算法分发 broadcast variables(广播变量)以降低通信成本。
Spark 的 action(动作)操作是通过一系列的 stage(阶段)进行执行的,这些 stage(阶段)是通过分布式的 “shuffle” 操作进行拆分的。Spark 会自动广播出每个 stage(阶段)内任务所需要的公共数据。这种情况下广播的数据使用序列化的形式进行缓存,并在每个任务运行前进行反序列化。这也就意味着,只有在跨越多个 stage(阶段)的多个任务会使用相同的数据,或者在使用反序列化形式的数据特别重要的情况下,使用广播变量会有比较好的效果。
广播变量通过在一个变量 v 上调用 SparkContext.broadcast(v) 方法来进行创建。广播变量是 v 的一个 wrapper(包装器),可以通过调用 value 方法来访问它的值。代码示例如下:
scala> import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SparkSession
scala> val spark=SparkSession.builder().appName("Broadcast").getOrCreate()
18/03/05 13:59:26 WARN SparkSession$Builder: Using an existing SparkSession; some configuration may not take effect.
spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@3346e906
scala> val slices=2
slices: Int = 2
scala> val num=1000000
num: Int = 1000000
scala> val arr1=new Array[Int](num)
arr1: Array[Int] = Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
scala> for(i<-0 until arr1.length){
| arr1(i)=i
| }
scala> val arr2=new Array[Int](num)
arr2: Array[Int] = Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
scala> for (i<-0 until arr2.length){
| arr2(i)=i
| }
scala> val barr1=spark.sparkContext.broadcast(arr1)
barr1: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> val barr2=spark.sparkContext.broadcast(arr2)
barr2: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(1)
scala> val observedSizes=spark.sparkContext.parallelize(0 to 10,slices).map(_=>(barr1.value.length,barr2.value.length))
observedSizes: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[1] at map at <console>:40
scala> observedSizes.collect().foreach(i => println(i))
(1000000,1000000)
(1000000,1000000)
(1000000,1000000)
(1000000,1000000)
(1000000,1000000)
(1000000,1000000)
(1000000,1000000)
(1000000,1000000)
(1000000,1000000)
(1000000,1000000)
(1000000,1000000)
在创建广播变量之后,在集群上执行的所有的函数中,应该使用该广播变量代替原来的 v 值,所以节点上的 v 最多分发一次。另外,对象 v 在广播后不应该再被修改,以保证分发到所有的节点上的广播变量具有同样的值(例如,如果以后该变量会被运到一个新的节点)。
spark知识体系03-Rdds,Accumulators,Broadcasts
标签:bubuko 相加 led next clu rman efi 输入输出 dog
原文地址:https://www.cnblogs.com/molyeo/p/9246365.html