标签:估计 new sub state 技术 测试数据 features 格式 分类
机器学习一般的数据集会划分为两个部分:
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
sklearn.model_selection.train_test_split
sklearn.datasets
加载获取流行数据集
datasets.load_() 获取小规模数据集,数据包含在datasets里
datasets.fetch_(data_home=None)获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集
下载的目录,默认是 ~/scikit_learn_data/
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
sklearn.datasets.load_iris() 加载并返回鸢尾花数据集

sklearn.datasets.load_digits() 加载并返回数字数据集
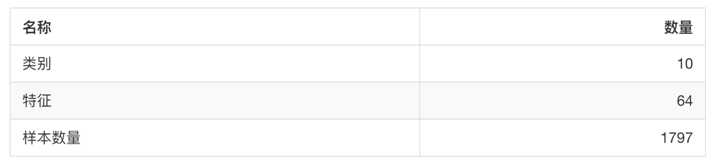
用于分类的大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
subset: ‘train‘或者‘test‘,‘all‘,可选,选择要加载的数据集.
训练集的“训练”,测试集的“测试”,两者的“全部”
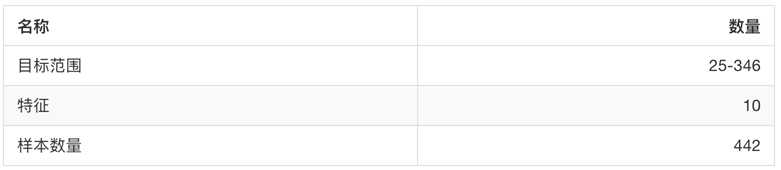
sklearn.datasets.load_boston() 加载并返回波士顿房价数据集
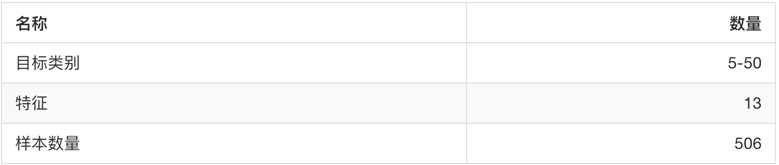
sklearn.datasets.load_diabetes() 加载和返回糖尿病数据集
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API
标签:估计 new sub state 技术 测试数据 features 格式 分类
原文地址:https://www.cnblogs.com/longyunfeigu/p/9254548.html