标签:递归 图片 img 创建 scheduler ima 分享 ide loader
scrapy startproject xxx
cd xxx
scrapy genspider xxxx xxxx.com
# -*- coding: utf-8 -*-
import scrapy
class ShiinaSpider(scrapy.Spider):
name = ‘shiina‘
allowed_domains = [‘mashiro.com‘]
start_urls = [‘https://tieba.baidu.com/p/5290405550?red_tag=0653675634‘]
def parse(self, response):
# response:相应
# 执行命令:scrapy crawl shiina --nolog,--log意思是不打印日志
print(response)
print(response.url)
print(response.text) # 这里不显示了
# 程序运行结果
‘‘‘
<200 https://tieba.baidu.com/p/5290405550?red_tag=0653675634>
https://tieba.baidu.com/p/5290405550?red_tag=0653675634
‘‘‘
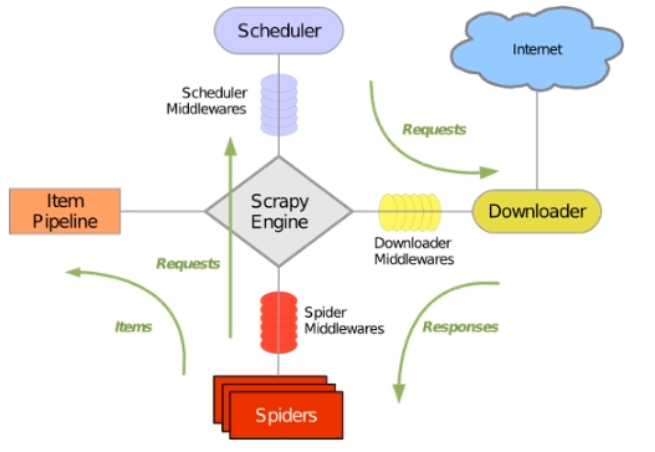
每一个创建的spider都会具有一个起始url,当我们执行的时候scrapy engine会将连接放在scheduler里面,然后往里面取链接,交给downloader去下载,下载完了交给spider。spider对内容进行解析,然后既可以将内容交给pipline进行持久化,也可以将新的url继续通过scrapy engine交给scheduler,然后继续递归爬取。
可以把scrapy engine看成一个while循环,scheduler看成是一个队列,scrapy engine不断地从队列里面取url,交给下载器去下载
标签:递归 图片 img 创建 scheduler ima 分享 ide loader
原文地址:https://www.cnblogs.com/traditional/p/9255610.html