标签:http read || cpp 手写 char s 转换 memset vector
终于到了饭吉圆杯的开赛,这是EZ我参与的历史上第一场ACM赛制的题目然而没有罚时
不过题目很好,举办地也很成功,为法老点赞!!!
这次和翰爷,吴骏达 dalao,陈乐扬dalao组的队,因为我们有二个初二的,所以并起来算一个 。
然后我和另外一个初二的连键盘都没摸,靠着翰爷的大杀四方成功A了5题并因为罚时惜败得到Rank2。%%%Orz 翰爷%%%
好了下面开始讲题。
与一般的ACM相似,这次考试的题目也分为三档:
好了我是真的菜,并且针对我无比菜的水平,我也只改了Easy+Medium。
整场比赛最水的题目了,模拟题不解释。
由于\(n\le 111\),因此连Hash都不用上。我们直接把图变成字符串然后开Map存一下即可
CODE
#include<iostream>
#include<cstdio>
#include<map>
#include<string>
using namespace std;
const int N=120;
map <string,bool> t;
int n,m,a,b,ans;
char g[N][N];
bool vis[N][N];
string s;
inline void find(void)
{
for (register int i=2;i<=n;++i)
if (g[i][2]==‘#‘) { a=i-2; break; }
for (register int i=2;i<=m;++i)
if (g[2][i]==‘#‘) { b=i-2; break; }
}
inline void solve(int x1,int y1,int x2,int y2)
{
register int i,j;
for (s="",i=x1;i<=x2;++i)
for (j=y1;j<=y2;++j)
s+=g[i][j],vis[i][j]=1;
if (t[s]) return;
for (s="",i=x2;i>=x1;--i)
for (j=y2;j>=y1;--j)
s+=g[i][j];
if (t[s]) return;
if (a==b)
{
for (s="",j=y2;j>=y1;--j)
for (i=x1;i<=x2;++i)
s+=g[i][j];
if (t[s]) return;
for (s="",j=y1;j<=y2;++j)
for (i=x2;i>=x1;--i)
s+=g[i][j];
if (t[s]) return;
}
t[s]=1; ++ans;
}
int main()
{
//freopen("CODE.in","r",stdin); freopen("CODE.out","w",stdout);
register int i,j; ios::sync_with_stdio(false); cin>>n>>m;
for (i=1;i<=n;++i)
for (j=1;j<=m;++j)
cin>>g[i][j]; find();
for (i=1;i<=n;++i)
for (j=1;j<=m;++j)
if (g[i][j]!=‘#‘&&!vis[i][j]) solve(i,j,i+a-1,j+b-1);
return printf("%d",ans),0;
}这道题有两种方法。
第一种当然是暴力证明了,由于我不会,因此给出法老的手写证明:
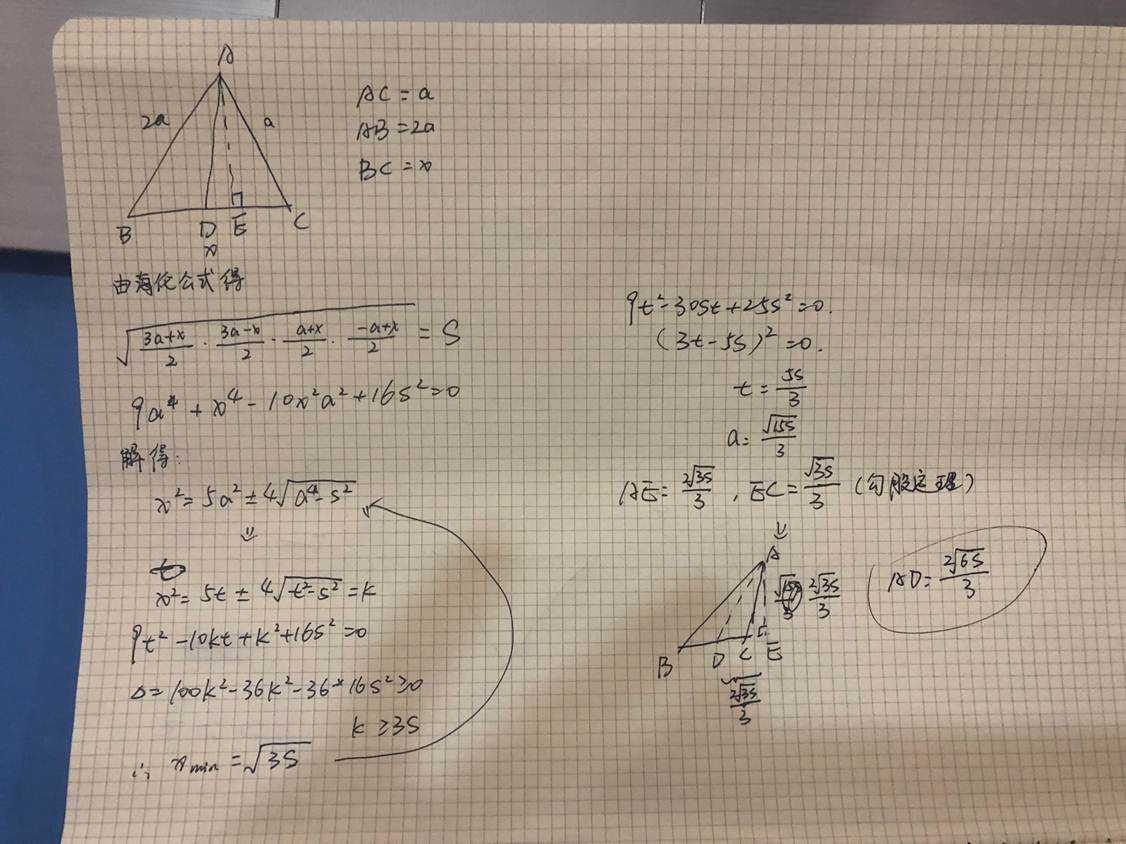
第二种就比较策略了。题目中提到了:
\(f(s)\)的函数图像似乎是一个极其诡异的曲线
然后我们根据相似三角形感性理解一下其实面积变大的话其形状不会改变,只有边长会按比例增加。
因此我们可以结合样例得到:
\(f(s)=A \sqrt S=1.63299\sqrt S\)
然后写上去一交发现WA了!Why?精度!
我们来猥琐一波:
\((1.63299)^2=2.666...=\frac{8}{3}\)
所以\(A=\frac{2\sqrt S}{3}\)
然后就水过了。
CODE
#include<cstdio>
#include<cmath>
using namespace std;
int main()
{
int n; scanf("%d",&n);
printf("%.5lf",(double)sqrt(n*8.0/3.0));
return 0;
}也是比较简单的题目,要正确理解题意
首先我们先对原图跑一遍MST,如果求出来的MST已经包含多种颜色,那么直接输出答案即可。
如果只有一种颜色,我们就挑一条不同颜色的边,然后肯定会有一条边被替换下来。
我们找到这条边的最大值即可。
这种方法可以和求LCA一起搞,主要就是倍增。
令\(f_{i,j}\)表示第\(i\)条边向上\(2^j\)次步的路径上的最大值,然后和LCA一起做即可(因为刚好也查询到LCA)
具体维护看CODE
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=100005,P=20;
struct edge
{
int to,next,v;
}e[N<<1];
struct data
{
int l,r,w,col;
bool use;
}a[N];
int head[N],n,m,pa[N][P],f[N][P],father[N],dep[N],cnt,c,rt=1;
long long tot;
inline char tc(void)
{
static char fl[100000],*A=fl,*B=fl;
return A==B&&(B=(A=fl)+fread(fl,1,100000,stdin),A==B)?EOF:*A++;
}
inline void read(int &x)
{
x=0; char ch=tc();
while (ch<‘0‘||ch>‘9‘) ch=tc();
while (ch>=‘0‘&&ch<=‘9‘) x=x*10+ch-‘0‘,ch=tc();
}
inline bool comp(data a,data b)
{
return a.w<b.w;
}
inline void add(int x,int y,int z)
{
e[++cnt].to=y; e[cnt].v=z; e[cnt].next=head[x]; head[x]=cnt;
}
inline int max(int a,int b)
{
return a>b?a:b;
}
inline int min(int a,int b)
{
return a<b?a:b;
}
inline int getfather(int k)
{
return father[k]==k?k:father[k]=getfather(father[k]);
}
inline void DFS(int now,int fa)
{
for (register int i=head[now];i!=-1;i=e[i].next)
if (e[i].to!=fa) f[e[i].to][0]=e[i].v,pa[e[i].to][0]=now,dep[e[i].to]=dep[now]+1,DFS(e[i].to,now);
}
inline void init(void)
{
for (register int j=0;j<P-1;++j)
for (register int i=1;i<=n;++i)
if (pa[i][j]) pa[i][j+1]=pa[pa[i][j]][j],f[i][j+1]=max(f[i][j],f[pa[i][j]][j]);
}
inline void swap(int &a,int &b)
{
int t=a; a=b; b=t;
}
inline int getmax(int x,int y)
{
if (dep[x]<dep[y]) swap(x,y); register int i; int res=0;
for (i=P-1;i>=0;--i)
if (pa[x][i]&&dep[pa[x][i]]>=dep[y]) res=max(res,f[x][i]),x=pa[x][i];
if (x==y) return res;
for (i=P-1;i>=0;--i)
if (pa[x][i]&&pa[y][i]&&pa[x][i]!=pa[y][i])
{
res=max(res,max(f[x][i],f[y][i]));
x=pa[x][i]; y=pa[y][i];
}
return max(res,max(f[x][0],f[y][0]));
}
int main()
{
//freopen("CODE.in","r",stdin); freopen("CODE.out","w",stdout);
register int i; read(n); read(m);
memset(e,-1,sizeof(e));
memset(head,-1,sizeof(head));
for (i=1;i<=m;++i)
read(a[i].l),read(a[i].r),read(a[i].w),read(a[i].col);
sort(a+1,a+m+1,comp);
for (i=1;i<=n;++i)
father[i]=i;
for (i=1;i<=m;++i)
{
int fx=getfather(a[i].l),fy=getfather(a[i].r);
if (fx!=fy)
{
father[fx]=fy; tot+=a[i].w; a[i].use=1;
add(a[i].l,a[i].r,a[i].w); add(a[i].r,a[i].l,a[i].w);
}
}
for (i=1;i<=m;++i)
if (a[i].use)
{
if (!c) { c=a[i].col; continue; }
if (c!=a[i].col) return printf("%lld",tot),0;
}
DFS(rt,-1); init(); long long ans=1e18;
for (i=1;i<=m;++i)
if (!a[i].use&&a[i].col!=c) ans=min(ans,tot-getmax(a[i].l,a[i].r)+a[i].w);
return printf("%lld",ans),0;
}比较套路的数位DP。
我们考虑对题意进行转换,考虑把走过的点写下来,那么一个点的二进制是另一个点的二进制的子集。
所以每一个路径上的数肯定是一段1,然后一段0。
就相当于要确定二进制每一位的出现次数,然后出现的二进制位值之和要小于等于\(k\),总和等于\(n\)
仔细想一想,这就是个多重背包了(怎么好像就我一个人写多重背包)
CODE
#include<cstdio>
#include<cctype>
#include<cstring>
using namespace std;
const int N=1e5+5,mod=1e9+9;
int n,k,f[N],x;
inline void inc(int &x,int y)
{
if ((x+=y)>=mod) x-=mod;
}
inline void dec(int &x,int y)
{
if ((x-=y)<0) x+=mod;
}
int main()
{
register int i,j; scanf("%d%d",&k,&n); f[0]=1;
for (i=0;(x=1<<i)<=n;++i)
{
for (j=0;j<=n;++j)
if (j>=x) inc(f[j],f[j-x]);
for (j=n;j>=0;--j)
if (j>=(long long)x*(k+1)) dec(f[j],f[j-(long long)x*(k+1)]);
}
return printf("%d",f[n]),0;
}这是典型的技巧题,首先我们想一下这个问题的两种解决方法:
然后这两种算法的效率取决于每组数据的点数。我们设一个阈值\(S\):
当点数大于\(S\)时进行算法1,否则进行算法2。
然后我们可以得出取\(S=\frac{q}{log\ m}\)时复杂度达到理论最小值\(O(q\cdot\sqrt{m\ log\ m})\)
CODE
#include<cstdio>
#include<cctype>
#include<cmath>
#include<map>
#include<set>
using namespace std;
const int N=200005;
struct edge
{
int x,y;
}e[N];
map <int,bool> vis[N];
int n,m,q,blk,t,ans,num[N];
bool s[N];
inline char tc(void)
{
static char fl[100000],*A=fl,*B=fl;
return A==B&&(B=(A=fl)+fread(fl,1,100000,stdin),A==B)?EOF:*A++;
}
inline void read(int &x)
{
x=0; char ch; while (!isdigit(ch=tc()));
while (x=(x<<3)+(x<<1)+ch-‘0‘,isdigit(ch=tc()));
}
inline void write(int x)
{
if (x>9) write(x/10);
putchar(x%10+‘0‘);
}
inline int solve1(void)
{
register int i,ans=0;
for (i=1;i<=m;++i)
if (s[e[i].x]&&s[e[i].y]) ++ans;
return ans;
}
inline int solve2(void)
{
register int i,j,ans=0;
for (i=1;i<t;++i)
for (j=i+1;j<=t;++j)
if (vis[num[i]][num[j]]) ++ans;
return ans;
}
int main()
{
//freopen("CODE.in","r",stdin); freopen("CODE.out","w",stdout);
register int i; read(n); read(m);
for (i=1;i<=m;++i)
read(e[i].x),read(e[i].y),vis[e[i].x][e[i].y]=vis[e[i].y][e[i].x]=1;
read(q); blk=q/(int)log2(m);
while (q--)
{
for (read(t),i=1;i<=t;++i)
read(num[i]),s[num[i]]=1;
write(t>blk?solve1():solve2()); putchar(‘\n‘);
for (i=1;i<=t;++i)
s[num[i]]=0;
}
return 0;
}这道题也是有点骚的,就着法老的std写的,第一次知道双Hash的正确写法
首先读题,我们考虑枚举所有的周期,然后对于每一段我们可以结合特殊最小表示法+双Hash来\(O(1)\)求
然后这里我们要知道一个调和级数公式(其实我是知道的,也和另外一个初二口头AC了这道题,不过最后时间不够了,而且我们也不敢上):
\(n+\frac{n}{2}+\frac{n}{3}+\frac{n}{4}+\cdots+\frac{n}{n-1}+1=n\ In\ n\)
然后把每种字符出现的位置用01二进制串表示,然后hash,判断是否能两两对应就可以了 。
CODE
#include<cstdio>
#include<cstring>
#include<vector>
#include<algorithm>
#define fir first
#define sec second
using namespace std;
typedef pair<int,int> Hash;
const int N=1e5+5;
const Hash seed={233,2333},mod={1e9+7,1e9+9};
vector <Hash> a,b;
char s[N];
int len;
Hash pre[5][N],pw[N];
Hash operator %(Hash a,Hash b) { return Hash((a.fir+b.fir)%b.fir,(a.sec+b.sec)%b.sec); }
Hash operator +(Hash a,Hash b) { return Hash(a.fir+b.fir,a.sec+b.sec)%mod; }
Hash operator -(Hash a,Hash b) { return Hash(a.fir-b.fir,a.sec-b.sec)%mod; }
Hash operator *(Hash a,Hash b) { return Hash(1LL*a.fir*b.fir%mod.fir,1LL*a.sec*b.sec%mod.sec); }
inline void write(int x)
{
if (x>9) write(x/10);
putchar(x%10+‘0‘);
}
inline int min(int a,int b)
{
return a<b?a:b;
}
inline Hash get_sub(int k,int l,int r)
{
return pre[k][r]-(pre[k][l-1]*pw[r-l+1]);
}
int main()
{
register int i,j,k; scanf("%s",s+1); len=strlen(s+1);
for (pw[0]={1,1},i=1;i<=len;++i)
pw[i]=pw[i-1]*seed;
for(i=1;i<=len;++i)
{
for(j=0;j<5;++j)
pre[j][i]=pre[j][i-1]*seed;
pre[s[i]-‘a‘][i]=pre[s[i]-‘a‘][i]+Hash(1,1);
}
for (i=1;i<=len;++i)
{
bool flag=1;
for (j=i+1;j<=len;j+=i)
{
a.clear(); b.clear();
for (k=0;k<5;++k)
a.push_back(get_sub(k,1,min(i,len-j+1))),b.push_back(get_sub(k,j,min(i+j-1,len)));
sort(a.begin(),a.end()); sort(b.begin(),b.end());
if (a!=b) { flag=0; break; }
}
if (flag) write(i),putchar(‘ ‘);
}
return 0;
}首先先发现对\(t\)从小到大排序后可以得到最优解(这个很好证明而且也很显然,实在不行结合样例理解一下即可)。
考虑排序后如何算出初始的最优解,我们可以分析后得出答案等价于:
\(\sum_{i=1}^n l_i-t_i\cdot(n-i+1)\)
然后我们考虑修改,其实就是取走一个数在放上一个数的过程,我们发现只要得出这个点(老的)对答案的贡献和新的点对答案的贡献。
很显然,一个点被删除/加入对于它的排名有影响,对排在它后面的数的答案也有影响。
因此我们分别考虑这两个影响,排名可以用类似于求逆序对的方法用树状数组求知。
然后考虑对于排在它后面的数统统前移一位,其实也是一个求和(\(\sum t_i\))的过程,因此我们再开一维树状数组来直接统计即可。
具体实现看CODE
#include<cstdio>
#include<cctype>
#include<algorithm>
using namespace std;
typedef long long LL;
const LL N=2e5+5;
LL n,m,l[N],t[N],r[N],x,nl,nt,ans,tree[2][N>>1];
inline char tc(void)
{
static char fl[100000],*A=fl,*B=fl;
return A==B&&(B=(A=fl)+fread(fl,1,100000,stdin),A==B)?EOF:*A++;
}
inline void read(LL &x)
{
x=0; char ch; while (!isdigit(ch=tc()));
while (x=(x<<3)+(x<<1)+ch-‘0‘,isdigit(ch=tc()));
}
inline void write(LL x)
{
if (x<0) putchar(‘-‘),x=-x;
if (x>9) write(x/10); putchar(x%10+‘0‘);
}
inline void add(LL x,LL y,LL z)
{
for (;x<=1e5;tree[z][x]+=y,x+=x&-x);
}
inline LL get(LL x,LL y)
{
LL tot=0; for (;x;tot+=tree[y][x],x-=x&-x); return tot;
}
int main()
{
//freopen("CODE.in","r",stdin); freopen("CODE.out","w",stdout);
register LL i; read(n); read(m);
for (i=1;i<=n;++i)
read(l[i]),read(t[i]),r[i]=t[i],ans+=l[i];
sort(r+1,r+n+1);
for (i=1;i<=n;++i)
ans-=r[i]*(n-i+1),add(r[i],1,0),add(r[i],r[i],1);
write(ans); putchar(‘\n‘);
while (m--)
{
read(x); read(nl); read(nt);
ans-=l[x]; l[x]=nl; ans+=l[x];
add(t[x],-1,0); add(t[x],-t[x],1);
ans+=t[x]*(n-get(t[x],0))+get(t[x],1);
t[x]=nt; ans-=t[x]*(n-get(t[x],0))+get(t[x],1);
add(t[x],1,0); add(t[x],t[x],1);
write(ans); putchar(‘\n‘);
}
return 0;
}标签:http read || cpp 手写 char s 转换 memset vector
原文地址:https://www.cnblogs.com/cjjsb/p/9255601.html