标签:href 支持 过程 就会 调用 计算 分享 进一步 例子
coprocessor这个单词看起来很神秘,直译为协处理器,其实可以理解成依赖于regionserver进程的辅助处理接口。
hbae在0.92版本之后提供了coprocessor接口。目前hbase支持两种coprocessor,endpoint和observer。hbase在未来版本可能考虑将coprocessor进程独立出来,单独起个服务。
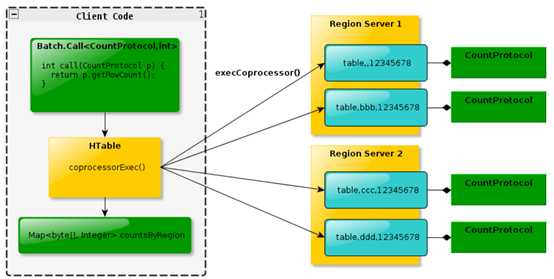
Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执行,势必效率低下。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。这样整体的执行效率就会提高很多。说白了,coprocessor就是hbase提供一些接口和规则,让你可以在regionserver服务中执行你自定义的代码。这个规则就是基于google的protobuf。
endpoint observer在多个regionserver上执行,执行结果返回给client,这个过程有点像mapreduce,map操作在regionserver端,reduce在client端。下图为endpoint执行流程。
另外一种协处理器叫做 Observer Coprocessor,这种协处理器类似于传统数据库中的触发器,思路上类似AOP的思想,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子.
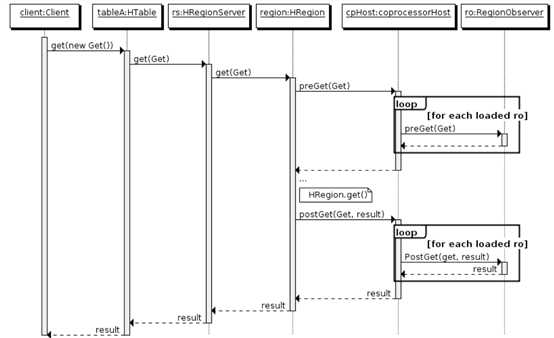
在Region层面,比如:put 操作之前有钩子函数 prePut,该函数在 put 操作执行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数。还有例如get,delete,scan等其他操作的钩子.
在regionserver层面,observer coprocessor还提供了WALObserver
在MasterObserver层面,提供了DDL操作的相关钩子,create,delete等
下图为observer coprocessor执行流程,注意最后的regionObserver是在服务端执行的,因此自定义的observer coprocessor代码打包后需要放在hbase服务端也就是regionserver的classpath下。
参考hbaes源码中的src/example/coprocessor
https://blogs.apache.org/hbase/entry/coprocessor_introduction
标签:href 支持 过程 就会 调用 计算 分享 进一步 例子
原文地址:https://www.cnblogs.com/ulysses-you/p/9256723.html