标签:webapp 最大的 red 要求 bubuko smart html 成功 java
solr7需要java8环境,且需要在环境变量中添加 JAVA_HOME变量。
下载地址 https://lucene.apache.org/solr/mirrors-solr-latest-redir.html 我下载为7.4版本
在solr5以前solr的启动都有tomcat作为容器,但是从solr5以后solr内部集成jetty服务器,可以通过bin目录中脚本直接启动。就是从solr5以后跟solr4最大的区别是被发布成一个独立的应用。
在solr5之后solr其实特别容易安装,有安装包,之后在解压,直接启动bin下solr,solr就这样完成的启动了。。


注意:这里我直接启动会有报 log4j2.xml (文件名、目录名或卷标语法不正确。) 我暂时还没解决,不过不影响启动
启动后直接访问 http://localhost:8983/solr/#/
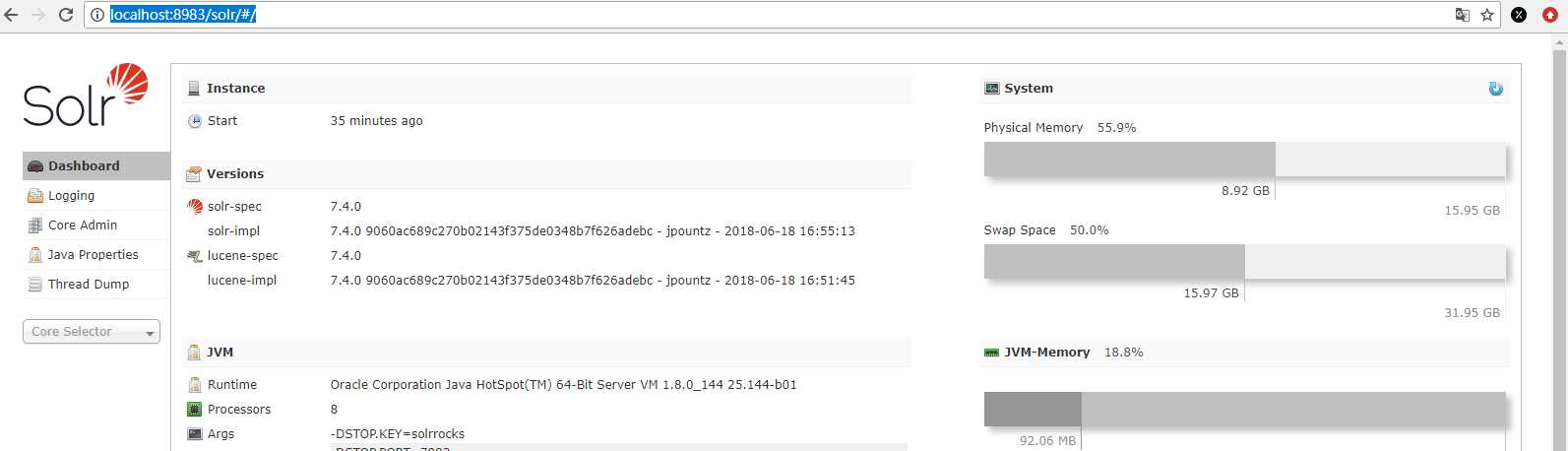
出现这个页面就表示solr启动成功
点击admin core 输入创建core名称 注意:创建的instanceDir和dataDir 需存在,就是我们需在solr-7.4.0\server\solr 目录下先去创建目录
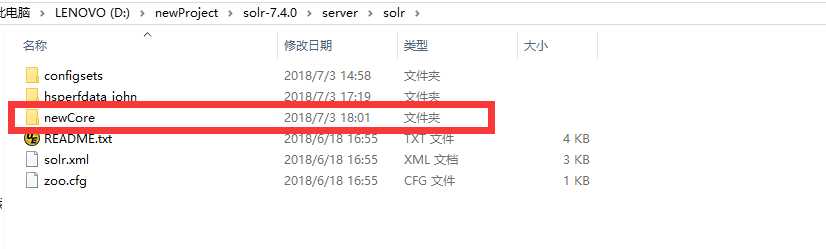
此目录下的conf文件我们可从solr\configsets\sample_techproducts_configs中复制
当创建与复制好后,我们在再页面上创建core 创建成功
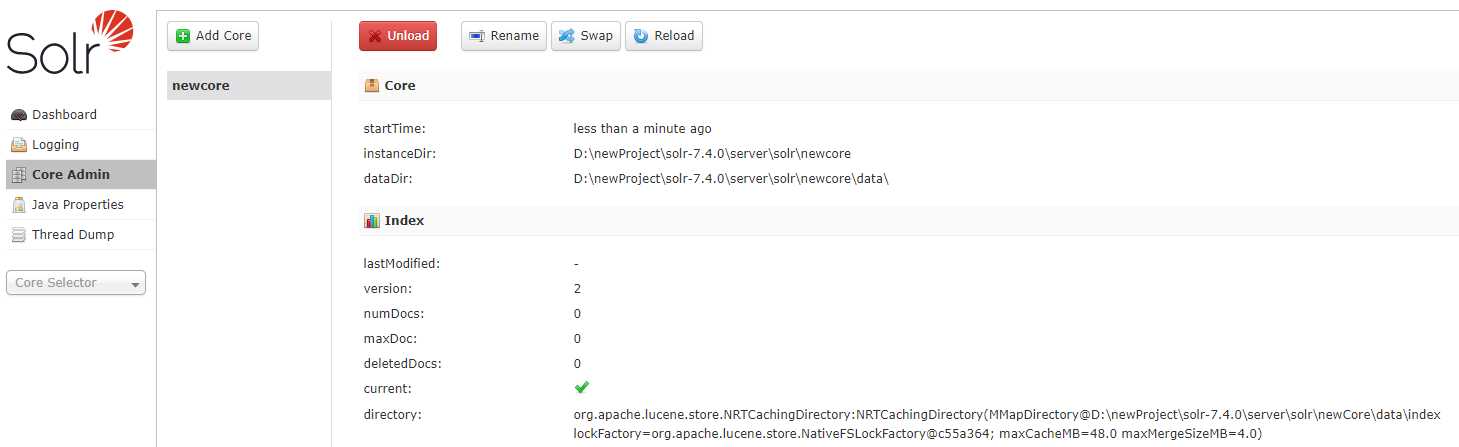
4.配置IK分词
下载地址:https://pan.baidu.com/s/1Dbma2vAepBSsCag_EztTTw
下载解压后 把两个jar文件复制到solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib中
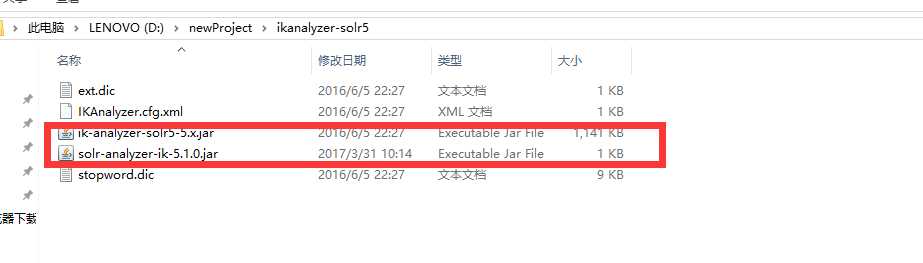
在solr-7.4.0\server\solr-webapp\webapp\WEB-INF\classes目录下新建一个classes目录,把下面三个文件复制进去
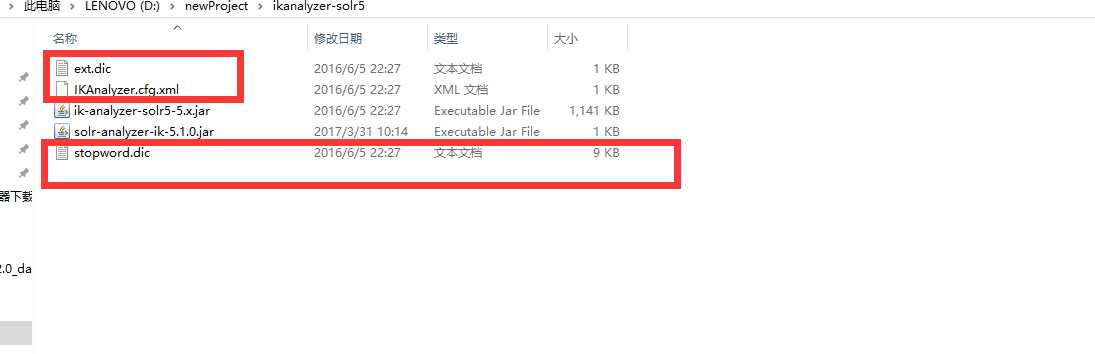
进入之前创建的core 在solr-7.4.0\server\solr\newCore\conf下打开managed-schema.xml 添加如下代码:
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer" /> <analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer" /> </fieldType>
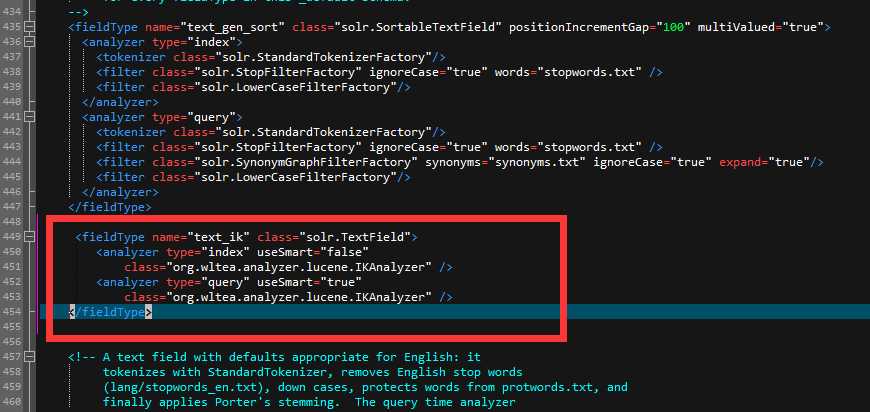
重启solr 重新访问 选择刚之前创建的core
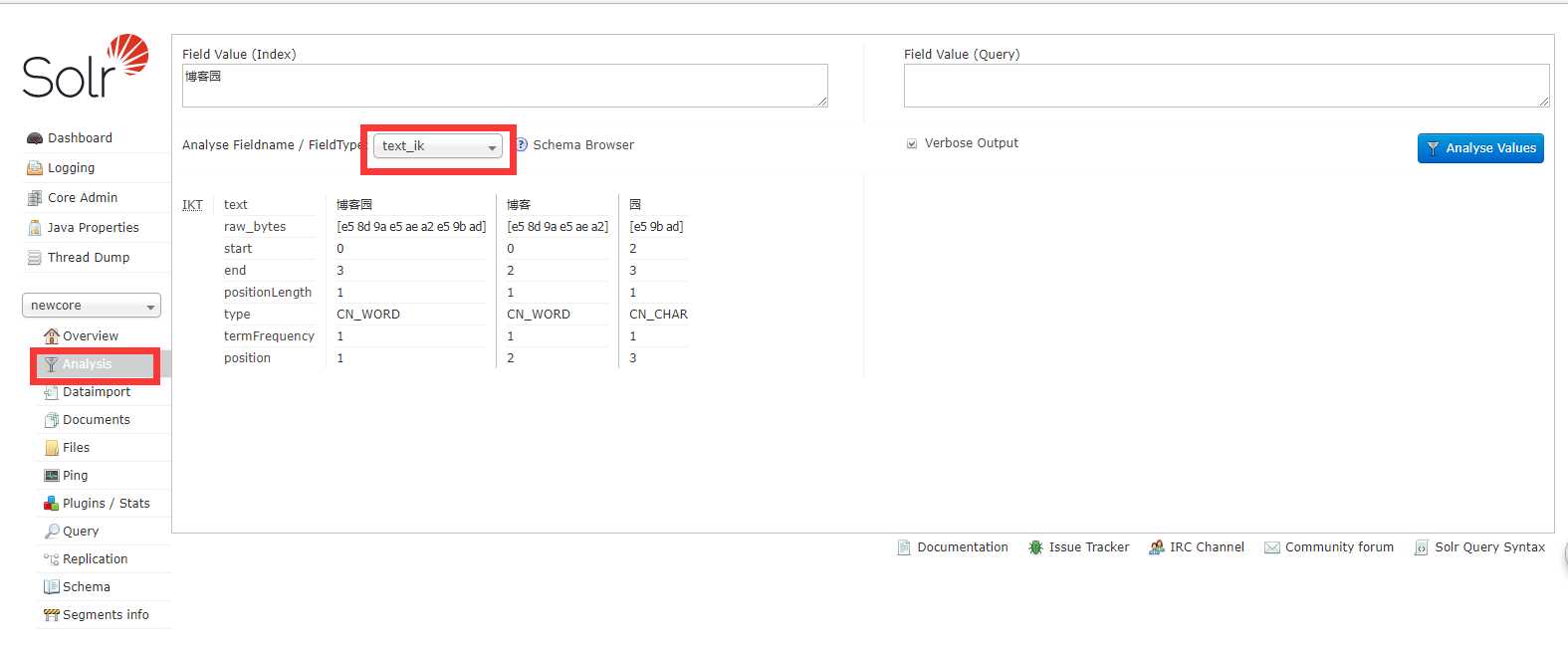
选择Analysis 输入要搜索的中文 选择FieldType为text_ik 可以发现分词成功
标签:webapp 最大的 red 要求 bubuko smart html 成功 java
原文地址:https://www.cnblogs.com/tony-zt/p/9260017.html