标签:不能 反码 assign 注意 har 排序 turned any list
1 快速入门... 4
1.1 分号... 4
1.2 常变量声明... 4
1.2.1 val常量... 4
1.2.2 var变量... 4
1.2.3 类型推导... 5
1.2.4 函数编程风格... 5
1.3 Range. 5
1.4 定义函数... 6
1.5 while、if6
1.6 foreach、for. 7
1.7 读取文件... 7
1.8 类、字段和方法... 7
1.9 Singleton单例对象... 9
1.10 Scala入口程序... 10
1.11 基本类型... 11
1.12 字面量... 12
1.12.1 整数字面量... 12
1.12.2 浮点数字面量... 12
1.12.3 字符字面量... 13
1.12.4 字符串字面量... 13
1.12.5 Symbol符号字面量... 14
1.12.6 布尔字面量... 15
1.13 操作符和方法... 15
1.14 数学运算... 16
1.15 关系和逻辑操作... 17
1.16 位操作符... 17
1.17 对象相等性... 18
1.18 操作符优先级... 19
1.19 基本类型富包装类型... 19
分号表示语句的结束;
如果一行只有一条语句时,可以省略,多条时,需要分隔
一般一行结束时,表示表达式结束,除非推断该表达式未结束:
// 末尾的等号表明下一行还有未结束的代码.
def equalsign(s: String) =
println("equalsign: " + s)
// 末尾的花括号表明下一行还有未结束的代码.
def equalsign2(s: String) = {
println("equalsign2: " + s)
}
//末尾的逗号、句号和操作符都可以表明,下一行还有未结束的代码.
def commas(s1: String,
s2: String) = Console.
println("comma: " + s1 +
", " + s2)
多个表达式在同一行时,需要使用分号分隔
定义的引用不可变,不能再指向别的对象,相当于Java中的final
Scala中一切皆对象,所以,定义一切都是引用(包括定义的基本类型变量,实质上是对象)
val定义的引用不可变,指不能再指向其他变量,但指向的内容是可以变的:

val定义的常量必须要初始化
val的特性能并发或分布式编程很有好处
定义的引用可以再次改变(内容就更可以修改了),但定义时也需要初始化
在Java中有原生类型(基础类型),即char、byte、short、int、long、float、double和boolean,这些都有相应的Scala类型(没有基本类型,但好比Java中相应的包装类型),Scala编译成字节码时将这些类型尽可能地转为Java中的原生类型,使你可以得到原生类型的运行效率
用val和var声明变量时必须初始化,但这两个关键字均可以用在构造函数的参数中,这时变量是该类的一个属性,因此显然不必在声明时进行初始化。此时如果用val声明,该属性是不可变的;如果用var声明,则该属性是可变的:
class Person(val name: String, var age: Int)
即姓名不可变,但年龄是变化的
val p = new Person("Dean Wampler", 29)

var和val关键字只标识引用本身是否可以指向另一个不同的对象,它们并未表明其所引用的对象内容是否可变
定义时可以省略类型,会根据值来推导出类型
scala> var str = "hello"
str: String = hello
scala> var int = 1
int: Int = 1
定义时也可明确指定类型:
scala> var str2:String = "2"
str2: String = 2
以前传统Java都是指令式编程风格,如果代码根本就没有var,即仅含有val,那它或许是函数式编程风格,因此向函数式风格转变的方式之一,多使用val,尝试不用任何var编程
指令式编程风格:
def printArgs(args: Array[String]): Unit = {
var i = 0
while (i < args.length) {
println(args(i))
i += 1
}
}
函数式编程风格:
def printArgs(args: Array[String]): Unit = {
for (arg <- args)
println(arg)
}
或者:
def printArgs(args: Array[String]): Unit = {
//如果函数字面量只有一行语句并且只带一个参数,
//则么甚至连指代参数都不需要
args.foreach(println)
}
数据范围、序列
支持Range的类型包括Int、Long、Float、Double、Char、BigInt和BigDecimal
Range可以包含区间上限,也可以不包含区间上限;步长默认为1,也可以指定一个非1的步长:

函数是一种具有返回值(包括空Unit类型)的方法
函数体中最后一条语句即为返回值。如果函数会根据不同情况返回不同类型值时,函数的返回类型将是不同值的通用(父)类型,或者是可以相互转换的类型(如Char->Int)
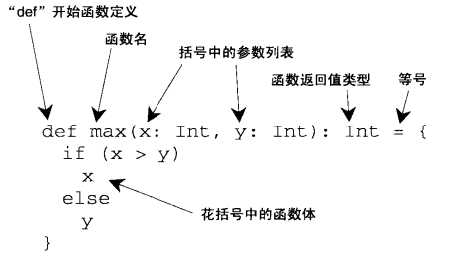
如果函数体只一条语句,可以省略花括号:
def max2(x:Int,y:Int)=if(x>y)x else y
scala> max2(3,5)
res2: Int = 5
Unit:返回类型为空,即Java中的void类型。如果函数返回为空,则可以省略
scala> def greet()=println("Hello")
greet: ()Unit
打印入口程序的外部传入的参数:
object Test {
def main(args: Array[String]): Unit = {
var i = 0
while (i < args.length) {
if (i != 0) print(" ")
print(args(i))
i += 1
}
}
}
注:Java有++i及i++,但Scala中没有。
与Java一样,while或if后面的布尔表达式必须放在括号里,不能写成诸如 if i < 10 的形式
object Test {
def main(args: Array[String]): Unit = {
var i = 0;
args.foreach(arg => { if (i != 0) print(" "); print(arg); i += 1 })
}
}
foreach方法参数要求传的是函数字面量(匿名函数),arg为函数字面量的参数,并且值为遍历出来的集合中的每个元素,类型为String,已省略,如不省略,则应为:
args.foreach((arg: String) => { if (i != 0) print(" "); print(arg); i += 1 })
如果函数字面量只有一行语句并且只带一个参数,则么甚至连指代参数都不需要:
args.foreach(println)
也可以使用for循环来代替:
for (arg <- args) println(arg)
object Test {
def main(args: Array[String]): Unit = {
import scala.io.Source
//将文件中所有行读取到List列表中
val lines = Source.fromFile(args(0)).getLines().toList
//找到最长的行:类似冒泡排序,每次拿两个元素进行比较
val longestLine = lines.reduceLeft((a, b) => if (a.length() > b.length()) a else b)
//最长行的长度本身的宽度
val maxWidth = widthOfLength(longestLine)
for (line <- lines) {
val numSpaces = maxWidth - widthOfLength(line)
//让输出的每行宽度右对齐
val padding = " " * numSpaces
println(padding + line.length() + " | " + line)
}
}
def widthOfLength(s: String) = s.length().toString().length()
}

类的方法以 def 定义开始,要注意的 Scala 的方法的参数都是 val 类型,而不是 var 类型,因此在函数体内不可以修改参数的值,比如如果你修改 add 方法如下:
使用class定义类:
class ChecksumAccumulator {}
然后就可以使用 new 来实例化:
val cal = new ChecksumAccumulator
类里面可以放置字段和方法,这都称为成员(member)。
字段,不管是使用val还是var,都是指向对象的变量(即Java中的引用)
方法,使用def进行定义
class ChecksumAccumulator {
var sum = 0
}
object Test {
def main(args: Array[String]): Unit = {
val acc = new ChecksumAccumulator
val csa = new ChecksumAccumulator
}
}
刚实例化时内存的状态如下:
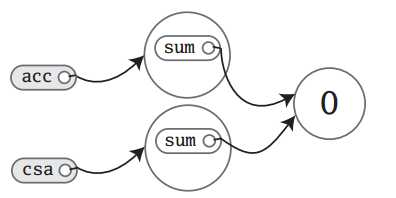
注:在Scala中,由于数字类型(整型与小数)都是final类型的,即不可变,所以在内存中如果是同一数据,则是共享的
由于上面是使用var进行定义的字段,而不是val,所以可以重新赋值:
acc.sum = 3
现在内存状态如下:
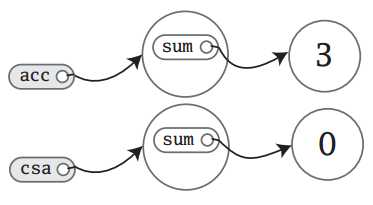
由于修改了acc中sum的内容,所以acc.sum指向了3所在的内存。
对象的稳定型就是要保证对象状态的稳定型,即对象中字段值在对象整个生命周期中持续有效。这需要将字段设为private以阻止外界直接对它进行访问与修改,因为私有字段只能被同一类里的方法访问,所以更新字段的代码将被锁定在类里:
class ChecksumAccumulator {
private var sum = 0
def add(b: Byte): Unit = {
sum += b
}
}
与Java 不同的,Scala 的缺省修饰符为 public,也就是如果不带有访问范围的修饰符 public,protected,private,Scala 缺省定义为 public
类的方法以 def 定义开始,要注意的 Scala 的方法的参数都是 val 类型,而不是 var 类型,因此在函数体内不可以修改参数的值,比如如果你修改 add 方法如下:
def add(b: Byte): Unit = {
b = 1 // 编译出错,因为b是val :error: reassignment to val
sum += b
}
如果某个方法的方法体只有一条语句,则可以去掉花括号:
def add(b: Byte): Unit = sum += b
类的方法分两种,一种是有返回值的,一种是不含返回值
如果方法没有返回值(或为Unit),则定义方法时可以去掉结果类型和等号 =,并把方法体放在花括号里:
def add(b: Byte) { sum += b }
定义方法时,如果去掉方法体前面的等号 =,则方法的结果类型就一定是Unit,这不管方法体最后语句是啥,因为编译器可以把任何类型转换为Unit,如结果是String,但返回结果类型声明为Unit,那么String将被转换为Unit并丢弃原值。下面是明确定义返回类型为Unit:
scala> def f(): Unit = "this String gets lost"
f: ()Unit
去掉等号的方法返回值类型也一定是Unit:
scala> def g() { "this String gets lost too" }
g: ()Unit
加上等号时,如果没有确定定义返回类型,则会根据方法体最后语句来推导:
scala> def h() = { "this String gets returned!" }
h: ()java.lang.String
scala> h
res0: java.lang.String = this String gets returned!
Scala 代码无需使用“;”结尾,也不需要使用 return返回值,函数的最后一行的值就作为函数的返回值
Scala中不能定义静态成员,而是以定义成单例对象(singleton object)来代替,即定义类时,使用的object关键字,而非class关键字,但看上去就像定义class一样:
class ChecksumAccumulator {
private var sum = 0
def add(b: Byte): Unit = {
sum += b
}
def checksum(): Int = {
return ~(sum & 0xFF) + 1
}
}
import scala.collection.mutable.Map
object ChecksumAccumulator {
private val cache = Map[String, Int]()
def calculate(s: String): Int =
if (cache.contains(s))
cache(s)
else {
val acc = new ChecksumAccumulator
for (c <- s)
acc.add(c.toByte)
val cs = acc.checksum()
cache += (s -> cs)
cs
}
}
当单例对象(object)与某个类(class)的名称相同时(上面都为ChecksumAccumulator),它就被称为是这个类的伴生对象。类和它的伴生对象必须定义在一个源文件里。类被称为这个单例对象的伴生类。类和它的伴生对象可以互相访问其私有成员
可以将单例对象当作Java中的静态方法工具类来使用,可以直接通过单例对象的名称来调用:
ChecksumAccumulator.calculate("Every value is an object.")
其实,单例对象就是一个对象,不需要实例化就可以直接通过单例对象名来访问其成员,即单例对象名就相当于变量名,已指向了某个类的实例,只不过该类不是由你来实例化,而是在访问它时由Scala实例化出来的,且在JVM只有一个这个的实例。在编译伴生对象时,会生成一个相应名为ChecksumAccumulator$(在单例对象名后加上美元符号)的类:

类和单例对象的差别:单例对象定义时不带参数(Object关键字后面),而类可以(Class关键字后面可以带括号将类参数包围起来),因为单例对象不是使用new关键字实例化出来的(这也是 Singleton 名字的由来)
单例对象在第一次被访问的时候才会被始化
没有伴生类的单例对象被称为独立对象,一般作为相关功能方法的工具类,或者用作Scala应用的入口程序
在Java中,只要类中有如下签名的main方法,即可作为程序入口程序:
class T {
public static void main(String[] args) {}
}
在Scala中,入口程序不是定义在类class中的,而是定义在单例对象中的,
object T {
def main(args: Array[String]): Unit = {}
}
与Java 类似,Scala 中任何 Singleton对象(使用Object关键字定义),如果包含 main 方法,都可以作为应用的入口
Scala的每个源文件都会自动引入包java.lang和scala包中的成员,和scala包中名为Predef的单例对象的成员,该单例对象中包含了许多有用的方法,例如,当在Scala源文件中写pringln的时候,实际调用了Predef.println,另外当你写assert,实质上是调用Predef.assert
Java的源文件扩展名为.java,而Scala的源文件扩展名为.scala
在Java中,如果源文件中有public的class,则该public类的类名必须与Java源文件名一致,但在Scala中没有这种限制,但一般会将源文件名与类名设为一致
与Java一样,也有对应的编译与运行命令,它们分别是scalac(编译)与scala(运行),ava中的为javac、java,不管是Java还是Scala程序,都会编译成.class的字节码文件
Scala 为 Singleton 对象的 main 定义了一个 App trait 类型
Scala的入口程序还可以继承scala.App特质(Trait,Scala中的Trait像Java中的Interface,但不同的是可以有方法的实现),这样就不用写main方法(因为scala.App特质里实现了main方法),而直接将代码写在花括号里,花括号里的代码会被收集进单例对象的主构造器中,并在类被初始化时执行:
object T extends scala.App {
println("T")
}
缺点:命令参数行args不能再被访问;某些JVM线程会要求main方法不能通过继承得到,必须自己行编写;
Java 支持的基本数据类型,Scala 都有对应的支持,不过 Scala 的数据类型都是对象,而且这些基本类型都可以通过隐式自动转换的形式支持比 Java 基本数据类型更多的方法:比如调用 (-1).abs() ,Scala 发现基本类型 Int 没有提供 abs()方法,但可以发现系统提供了从 Int 类型转换为 RichInt 的隐式自动转换,而 RichInt 具有 abs 方法,那么 Scala 就自动将 1 转换为 RichInt 类型,然后调用 RichInt 的 abs 方法。
Scala 的基本数据类型有: Byte,Short,Int,Long 和 Char (这些成为整数类型)。整数类型加上 Float 和 Double 成为数值类型。此外还有 String 类型,除 String 类型在 java.lang 包中定义,其它的类型都定义在包 scala 中。比如 Int 的全名为 scala.Int。实际上 Scala 运行环境自动会载入包 scala 和 java.lang 中定义的数据类型,你可以使用直接使用 Int,Short,String 而无需再引入包或是使用全称(如scala.xx与java.lang.xx)。
Scala的基本类型与Java对应类型范围完全一样,这样可以让Scala编译器直接把这些类型编译成Java中的原始类型

scala> var hex=0xa //十六进制,整数默认就是Int类型
hex: Int = 10
scala> var hex:Short=0x00ff //若要Short类型,则要明确指定变量类型
hex: Short = 255
scala> var hex=0xaL //赋值时明确指定数据为Long型,否则默认为Int类型
hex: Long = 10
scala> val prog=2147483648L //若超过了Int范围,则后面一定要加上 L ,置换为Long类型
prog: Long = 2147483648
scala> val bt:Byte= 38 //若要Byte类型,则要在定义时明确指定变量的类型为Byte类型
bt: Byte = 38
scala> val big=1.23232 //小数默认就是Double类型
big: Double = 1.23232
scala> val big=1.23232f //如果要定义成Float,则可直接在小数后面加上F
big: Float = 1.23232
scala> val big=1.23232D //虽然默认就是Double,但也可在小数后面加上D
big: Double = 1.23232
scala> val a=‘A‘ //类型推导成Char类型
a: Char = A
scala> val f =‘\u0041‘ //也可以使用Unicode编码表示,以 \u 开头,u一定要小写,且\u后面接4位十六进制
f: Char = A
scala> val hello="hello" //类型推导成String类型
hello: String = hello
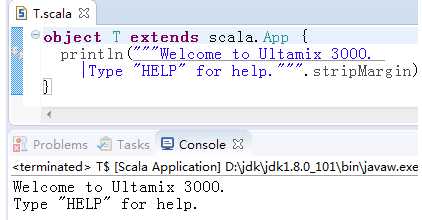
scala> val longString=""" Welcome to Ultamix 3000. Type "Help" for help.""" //以使用三个引号(""")开头和结尾,这样之间的字符都将看作是最原始的字符,不会被转义
longString: String = " Welcome to Ultamix 3000. Type "Help" for help." //注:开头与结尾的双引号不属于上面字符串的一部分,而是表示控制台上输出的是String
scala> val bool=true
bool: Boolean = true
字面量就是直接写在代码里的常量值
十六进制以 0x或0X开头:
scala> val hex = 0x5
hex: Int = 5
scala> val hex2 = 0x00FF
hex2: Int = 255
scala> val magic = 0xcafebabe
magic: Int = -889275714
注:不区分大小写
八进制以0开头
scala> val oct = 035 // (八进制35是十进制29)
oct: Int = 29
scala> val nov = 0777
nov: Int = 511
scala> val dec = 0321
dec: Int = 209
如果是非0开头,即十进制:
scala> val dec2 = 255
dec2: Int = 255
注:不管字面量是几进制,输出时都会转换为十进制
如果整数以L或l结尾,就是Long类型,否则默认就是Int类型:
scala> val prog = 0XCAFEBABEL
prog: Long = 3405691582
scala> val tower = 35L
tower: Long = 35
scala> val of = 31l
of: Long = 31
从上面可以看出,定义Int型时可以省去类型即可,如果是Long类型,定义时也可省略Long类型,此时在数字后面加上L或l即可,但也可以直接定义成Long也可:
scala> var lg:Long = 2
lg: Long = 2
如果要得到Byte或Short类型的变量时,需在定义时指定变量的相应类型:
scala> val little: Short = 367
little: Short = 367
scala> val littler: Byte = 38
littler: Byte = 38
scala> val big = 1.2345
big: Double = 1.2345
scala> val bigger = 1.2345e1
bigger: Double = 12.345
scala> val biggerStill = 123E45
biggerStill: Double = 1.23E47
小数默认就是Double类型,如果要是Float,则要以F结尾:
scala> val little = 1.2345F
little: Float = 1.2345
scala> val littleBigger = 3e5f
littleBigger: Float = 300000.0
当然Double类型也可以D结尾,不过是可选的
scala> val anotherDouble = 3e5
anotherDouble: Double = 300000.0
scala> val yetAnother = 3e5D
yetAnother: Double = 300000.0
当然,也要以在定义变量时明确指定类型也可:
scala> var f2 = 1.0
f2: Double = 1.0
scala> var f2:Float = 1
f2: Float = 1.0
使用单引号引起的单个字符
scala> val a = ‘A‘
a: Char = A
单引号之间除了直接是字符外,也可以是对应编码,编码是八进制或十六进制来表示
如果以八进制表示,则以 \ 开头,且为 ‘\0 到 ‘\377‘ (0377=255):
scala> val c = ‘\101‘
c: Char = A
注:如果以八进制表示,则只能表示一个字节大小的字符,即0~255之间的ASCII码单字节字符,如果要表示大于255的Unicode字符,则只能使用十六进制来表示:
scala> val d = ‘\u0041‘
d: Char = A scala>
val f = ‘\u0044‘
f: Char = D
scala> val c = ‘\u6c5f‘
c: Char = 江
注:以十六进制表示时,需以 \u(小写)开头,即后面跟4位十六进制的编码(两个字节)
实际上,十六进制可以出现在Scala程序的任何地方,如可以用在变量名里:
scala> val B\u0041\u0044 = 1
BAD: Int = 1
转义字符:
scala> val backslash = ‘\\‘
backslash: Char = \

使用双引号引起来的0个或多个字符
scala> val hello = "hello"
hello: java.lang.String = hello
特殊字符也需转义:
scala> val escapes = "\\\"\‘"
escapes: java.lang.String = \"‘
如果字符串中需要转义的字符很多时,可以使用三个引号(""")开头和结尾,这样之间的字符都将看作是最原始的字符,不会被转义(当然三个连续的引号除外):
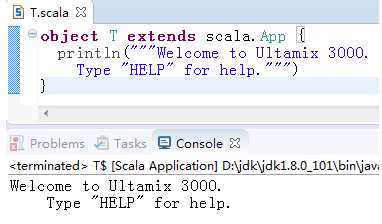
发现第二行前面的空格也会原样输出来,所以第二行前面看起来缩进了,如果要去掉每行前面的空白字符(ASCII编码小于等于32的都会去掉),则把管道符号(|)放在每行前面,然后对字符串调用stripMargin:
以单引号打头,后面跟一个或多个数字、字母或下划线,但第一个字符不能是数字,这种字面量会转换成预定义类scala.Symbol的实例,如 ‘cymbal编译器将会调用工厂方法Symbol("cymbal")转化成Symbol实例。
scala> val s = ‘aSymbol
s: Symbol = ‘aSymbol
scala> s.name
res20: String = aSymbol
符号字面量 ‘x 是表达式 scala.Symbol("x") 的简写
Java中String的intern()方法:String类内部维护一个字符串池(strings pool),当调用String的intern()方法时,如果字符串池中已经存在该字符串,则直接返回池中字符串引用,如果不存在,则将该字符串添加到池中,并返回该字符串对象的引用。执行过intern()方法的字符串,我们就说这个字符串被拘禁了(interned),即放入了池子。默认情况下,代码中的字符串字面量和字符串常量值都是被拘禁的,例如:
String s1 = "abc";
String s2 = new String("abc");
System.out.println(s1 == s2);//false
System.out.println(s1 == s2.intern());//true
同值字符串的intern()方法返回的引用都相同,例如:
String s2 = new String("abc");
String s3 = new String("abc");
System.out.println(s2 == s3);// false
System.out.println(s2.intern() == s3.intern());// true
String str1 = "abc";
String str2 = "abc";
System.out.println(str1 == str2);//true
String str3 = new String("abc");
System.out.println(str1 == str3);//false
Sysmbol实质上也是一种字符串,其好好处:
1. 节省内存
在Scala中,Symbol类型的对象是被拘禁的(interned,即会被放入池中),任意的同名symbols都指向同一个Symbol对象,避免了因冗余而造成的内存开销:
val s1 = "aSymbol"
val s2 = "aSymbol"
println(s1.eq(s2)) //true :表明s1与s2指向同一对象
val s3 = new String("aSymbol") //由于在编译时就确定,所以还是会放入常量池
println(s1.eq(s3)) //false : 表明s1与s3不是同一对象
println(s1 == s3) //true:虽然不是同一对象,但是它们的内容相同
val s = ‘aSymbol
println(s.eq(‘aSymbol)) //true
println(s.eq(Symbol("aSymbol"))) //true:只要是同名的Symbol,则都是指向同一对象
//即使s与s3的内容相同,但eq比较的是对象地址,所以不等
println(s.name.eq(s3)) //false
println(s.name == s3) //true:但内容相同
println(s.name.eq(s1)) //true : s与s1的的内容都会放入池中,所以指向的是同一对象
注:在Scala中,如果要基于引用地址进行比较,则要使用eq方法,而不是==,这与Java是不一样的
2. 快速比较
由于Symbol类型的对象会自动拘禁的(interned),任意的同名symbols(准确的说是值)都指向同一个Symbol对象,而相同值的字符串并不一定是同一个instance,所以symbols对象之间的比较操作符==速度会很快:因为它只基于地址进行比较,如果发现不是同一Symbols对象,则就认为不相同,不会在对内容进行比较(因为不同名的Symbols的值肯定也不相同)
Symbol类型的应用
Symbol类型一般用于快速比较,例如用于Map类型:Map<Symbol, Data>,根据一个Symbol对象,可以快速查询相应的Data, 而Map<String, Data>的查询效率则低很多。
虽说利用String的intern方法也可以实现Map<String, Data>的键值快速比较,但是由于需要显式地调用intern()方法,在编码时会造成很多的麻烦,而且如果忘了调用intern()方法,还会造成难以寻找的bug。从这个角度看,Scala的Symbol类型会自动进行intern操作(加入到池中),所以简化了编码的复杂度;而Java中除了字符串常量,是不会自动进行intern的,需要对相应对象手动调用interned方法
scala> val bool = true
bool: Boolean = true
scala> val fool = false
fool: Boolean = false
操作符如+加号,实质上是类型中有名为 + 的方法:
scala> val sum = 1 + 2 // Scala调用了(1).+(2)
sum: Int = 3
scala> val sumMore = (1).+(2)
sumMore: Int = 3
实际上Int类型包含了名为 + 的各种不同参数的重载方法,如Int+Long:
scala> val longSum = 1 + 2L // Scala调用了(1).+(2L)
longSum: Long = 3
既然+是名为加号的方法,可以以 1+2 这种操作模式来调用,那么其他方法也是可以如下方式来调用:
scala> val s = "Hello, world!"
s: java.lang.String = Hello, world!
scala> s indexOf ‘o‘ // 调用了s.indexOf(’o’)
res0: Int = 4
如果有多个参数,则要使用括号:
scala> s indexOf (‘o‘, 5) // Scala调用了s.indexOf(’o’, 5)
res1: Int = 8
在 Scala 中任何方法都可以是操作符:Scala里的操作符不是特殊的语法,任何方法都可以是操作符,到底是方法还是操作符取决于你如何使用它。如果写成s.indexOf(‘o‘),indexOf就不是操作符。不过如果写成,s indexOf ‘o‘,那么indexOf就是操作符了
上面看到的是中缀操作符,还是前缀操作符,如 -7里的“-”,后缀操作符如 7 toLong里的“toLong”( 实为 7.toLong )。
前缀操作符与后缀操作都只有一个操作数,是一元(unary)操作符,如-2.0、!found、~0xFF,这些操作符对应的方法是在操作符前加上前缀“unary_”:
scala> -2.0 // Scala调用了(2.0).unary_-
res2: Double = -2.0
scala> (2.0).unary_-
res3: Double = -2.0
可以当作前缀操作符用的标识符只有+、-、!和~。因此,如果你定义了名为unary_!的方法,就可以对值或变量用 !P 这样的前缀操作符方式调用方法。但是如果你定义了名为unary_*的方法,就没办法将其用成前缀操作符了,因为*不是四种可以当作前缀操作符用的标识符之一。
后缀操作符是不用点与括号调用的不带任何参数的方法:
scala> val s = "Hello, world!"
s: java.lang.String = Hello, world!
scala> s.toLowerCase()
res4: java.lang.String = hello, world!
由于不带参数,则可能省略括号
scala> s.toLowerCase
res5: java.lang.String = hello, world!
还可以省去点:
scala> import scala.language.postfixOps//需要导一下这个来激活后缀操作符使用方式,否则会警告
import scala.language.postfixOps
scala> s toLowerCase
res6: java.lang.String = hello, world!
scala> 1.2 + 2.3
res6: Double = 3.5
scala> 3 - 1
res7: Int = 2
scala> ‘b‘ - ‘a‘
res8: Int = 1
scala> 2L * 3L
res9: Long = 6
scala> 11 / 4
res10: Int = 2
scala> 11 % 4
res11: Int = 3
scala> 11.0f / 4.0f
res12: Float = 2.75
scala> 11.0 % 4.0
res13: Double = 3.0
数字类型还提供了一元的前缀 + 和 - 操作符(方法 unary_+ 和 unary_-)
scala> val neg = 1 + -3
neg: Int = -2
scala> val y = +3
y: Int = 3
scala> -neg
res15: Int = 2
scala> 1 > 2
res16: Boolean = false
scala> 1 < 2
res17: Boolean = true
scala> 1.0 <= 1.0
res18: Boolean = true
scala> 3.5f >= 3.6f
res19: Boolean = false
scala> ‘a‘ >= ‘A‘
res20: Boolean = true
可以使用一元操作符!(unary_!方法)改变Boolean值:
scala> val thisIsBoring = !true
thisIsBoring: Boolean = false
scala> !thisIsBoring
res21: Boolean = true
逻辑与(&&)和逻辑或(||):
scala> val toBe = true
toBe: Boolean = true
scala> val question = toBe || !toBe
question: Boolean = true
scala> val paradox = toBe && !toBe
paradox: Boolean = false
与Java里一样,逻辑与和逻辑或有短路:
scala> def salt() = { println("salt"); false }
salt: ()Boolean
scala> def pepper() = { println("pepper"); true }
pepper: ()Boolean
scala> pepper()&& salt()
pepper
salt
res22: Boolean = false
scala> salt()&& pepper()
salt
res23: Boolean = false
scala> pepper() || salt()
pepper
res24: Boolean = true
scala> salt() || pepper()
salt
pepper
res25: Boolean = true
按位与运算(&):都为1时才为1,否则为0
按位或运算(|):只要有一个为1 就为1,否则为0
按位异或运算(^):相同位产生0,不同产生1,因此0011 ^ 0101产生0110。
scala> 1 & 2 // 0001 & 0010 = 0000 = 0
res24: Int = 0
scala> 1 | 2 // 0001 | 0010 = 0011 = 3
res25: Int = 3
scala> 1 ? 3 // 0001 ^ 0011 = 0010 = 2
res26: Int = 2
scala> ~1 // ~0001 = 1110(负数原码:从最末一位向前除符号位各位取反即可) = 1010 = -2
res27: Int = -2
负数补码:反码+1
左移(<<),右移(>>)和无符号右移(>>>)。左移和无符号右移在移动的时候填入零。右移则在移动时填入左侧整数的最高位(符号位)。
scala> -1 >> 31 //1111 1111 1111 1111 1111 1111 1111 1111 向右移动后,还是 1111 1111 1111 1111 1111 1111 1111 1111,左侧用符号位1填充
res38: Int = -1
scala> -1 >>> 31 //1111 1111 1111 1111 1111 1111 1111 1111 向右无符号移动后,为0000 0000 0000 0000 0000 0000 0000 0001,左侧用0填充
es39: Int = 1
scala> 1 << 2 //0000 0000 0000 0000 0000 0000 0000 0001 向左位移后,为0000 0000 0000 0000 0000 0000 0000 0100,右侧用0填充
res40: Int = 4
基本类型比较:
scala> 1 == 2
res31: Boolean = false
scala> 1 != 2
res32: Boolean = true
scala> 2 == 2
res33: Boolean = true
这些操作对所有对象都起作用,而不仅仅是基本类型,如列表的比较:
scala> List(1, 2, 3) == List(1, 2, 3)
res34: Boolean = true
scala> List(1, 2, 3) == List(1, 3, 2)
res35: Boolean = false
还可以对不同类型进行比较,如:
scala> 1 == 1.0
res36: Boolean = true
scala> List(1, 2, 3) == "hello"
res37: Boolean = false
甚至可以与null进行比较:
scala> List(1, 2, 3) == null
res38: Boolean = false
== 操作符在比较之前,会先判断左侧的操作符是否为null,不为null时再调用左操作数的equals方法进行比较,比较的结果主要是看这个左操作数的equals方法是怎么实现的。只要比较的两者内容相同且并且equals方法是基于内容编写的,不同对象之间比较也可能为true。x == that判断表达式判断的过程实质如下:
if (x.eq(null))
that eq null
else
x.equals(that)
equals方法是检查值是否相等,而eq方法检查的是引用是否相等。所以如果使用 == 操作符比较两个对象时,如果左操作数是null,那么调用eq判断右操作数也是否为null;如果左操作数不是null的情况则调用equals基于对象内容进行比较
!= 就是 == 计算结果取反
Java中的==即可以比较原始类型,也可以比较引用类型。对于原始类型,Java的==比较值的相等性,与Scala一致,而对于引用类型,Java的==是比较这两个引用是否都指向了同一个对象,不过Scala比较对象地址不是 == 而是使用eq方法,所以Scala中的 == 操作符作用于对象时,会转换调用equals方法来比较对象的内容(在左操作数非null情况下)
AnyRef的equals方法默认调用eq方法实现,也就是说,默认情况下,判断两个变量相等,要求必须指向同一个对象实例
注:在Scala中,如果要基于引用地址进行比较,则要使用eq方法,而不是==,这与Java是不一样的
Scala中没有操作符,操作符只是方法的一种表达方式,其优先级是根据作用符的第一个字符来判断的(也有例外,请看后面以等号 = 字符结束的一些操作符),如规定第一个字符*就比+的优先级高。以操作符的第一个字符为依据,优先级如下:
(所有其他的特殊字符)
* / %
+ -
:
= !
< >
&
^
|
(所有字母)
(所有赋值操作)
上面同一行的字符具有同样的优先级
scala> 2 << 2 + 2 // 2<< (2 + 2)
res41: Int = 32
<<操作符第一个字符为<,根据上表 << 要比 + 优先级低
如果操作符以等号字符( =)结束 , 且操作符并非比较操作符<=,> =, ==,或=,那么这个操作符的优先级与赋值符( =)相同。也就是说,它比任何其他操作符的优先级都低。例如:
x *= y + 1
与下面的相同:
x *= (y + 1)
操作符 *= 以 = 结束,被当作赋值操作符,它的优先级低于+,尽管操作符的第一个字符是*看起来高于+。
任何以“:”字符结尾的方法由它的右操作数调用,并传入左操作数;其他结尾的方法与之相反,它们被左操作数调用,并传入右操作:a * b 变成 a.*(b), a:::b 变成 b.:::(a)。
多个同优先级操作符出现时,如果方法以:结尾,它们就被从右往左进行分组;反之,就从左往右进行分组,如:a ::: b ::: c 会被当作 a :::
(b ::: c),而 a * b * c 被当作(a * b) * c
基本类型除了一些常见的算术操作外,还有一些更为丰富的操作,这些操作可以直接使用,更多需要参考API中对应的富包装类:
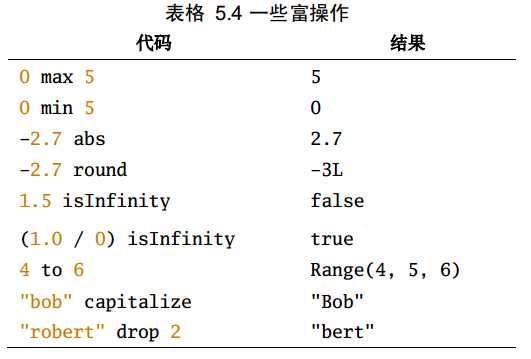
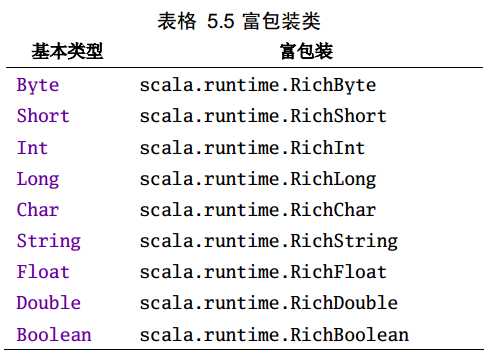
上述相应的富操作都是由下面相应的富包装类提供的,使用前会先自动进行隐式转换:
标签:不能 反码 assign 注意 har 排序 turned any list
原文地址:https://www.cnblogs.com/nucdy/p/9270666.html