标签:segment iss initial 最大 image blog 通过 nta 高并发
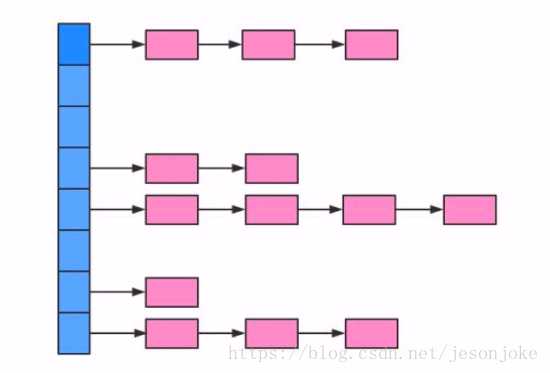
HashMap的实现方式是:数组+链表 的形式。
在HashMap中有两个参数会影响HashMap的性能:初始容量/加载因子
初始容量:Hash表中桶的数量
加载因子:是Hash表在自动增加之前可以达到多满的一个尺度。
通过计算key的hash值和数组长度值进行取模确定该key在数组中的索引。
//初始容量,默认16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//加载因子,默认0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
这两个参数的作用是:当Hash表中的条目数量超过了加载因子与当前容量的乘积,将会调用resize()进行扩容,将容量翻倍。
这两个参数在初始化HashMap的时候可以进行设置:可以单独指定初始容量,也可以同时设置
原因在于HashMap在多线程情况下,执行resize()进行扩容时容易造成死循环。
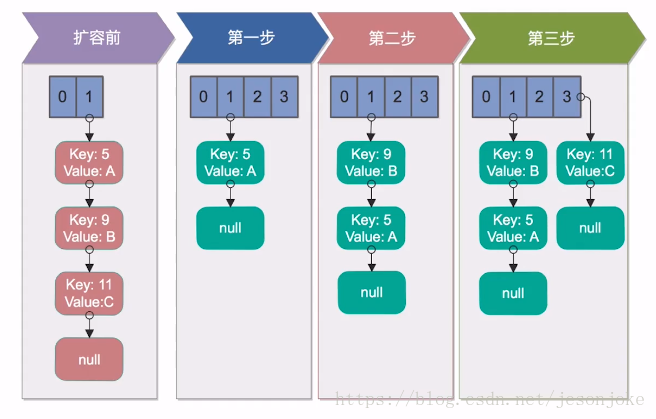
扩容思路为它要创建一个大小为原来两倍的数组,保证新的容量仍为2的N次方,从而保证上述寻址方式仍然适用。扩容后将原来的数组从新插入到新的数组中。这个过程称为reHash。
【单线程下的reHash】
单线程reHash完全没有问题。
【多线程下的reHash】

我们假设有两个线程同时需要执行resize操作,我们原来的桶数量为2,记录数为3,需要resize桶到4,原来的记录分别为:[3,A],[7,B],[5,C],在原来的map里面,我们发现这三个entry都落到了第二个桶里面。
假设线程thread1执行到了transfer方法的Entry next = e.next这一句,然后时间片用完了,此时的e = [3,A], next = [7,B]。线程thread2被调度执行并且顺利完成了resize操作,需要注意的是,此时的[7,B]的next为[3,A]。此时线程thread1重新被调度运行,此时的thread1持有的引用是已经被thread2 resize之后的结果。线程thread1首先将[3,A]迁移到新的数组上,然后再处理[7,B],而[7,B]被链接到了[3,A]的后面,处理完[7,B]之后,就需要处理[7,B]的next了啊,而通过thread2的resize之后,[7,B]的next变为了[3,A],此时,[3,A]和[7,B]形成了环形链表,在get的时候,如果get的key的桶索引和[3,A]和[7,B]一样,那么就会陷入死循环。
如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast。
在每一次对HashMap进行修改的时候,都会变动类中的modCount域,即modCount变量的值。
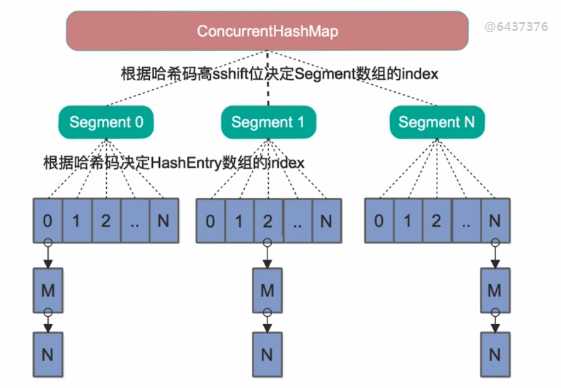
Segment继承自J.U.C里的ReetrantLock,所以可以很方便的对Segment进行上锁。即分段锁。理论上最大并发数是和segment的个数是想等的。 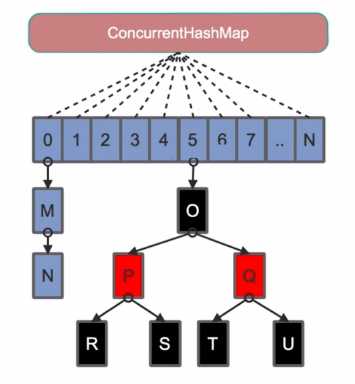
Java8为了进一步提高并发性,废弃了Java7中ConcurrentHashMap中分段锁的方案,并且不使用Segment,转为使用大的数组。同时为了提高Hash碰撞下的寻址做了性能优化。
标签:segment iss initial 最大 image blog 通过 nta 高并发
原文地址:https://www.cnblogs.com/xiangkejin/p/9276958.html